学界 | 滴滴 KDD 2018 论文详解:基于强化学习技术的智能派单模型
国际数据挖掘领域的顶级会议 KDD 2018 在伦敦举行,今年 KDD 吸引了全球范围内共 1480 篇论文投递,共收录 293 篇,录取率不足 20%。其中滴滴共有四篇论文入选 KDD 2018,涵盖 ETA 预测 (预估到达时间) 、智能派单、大规模车流管理等多个研究领域。
四篇论文分别是(文末附论文打包下载地址)
Efficient Large-Scale Fleet Management via Multi-Agent Deep Reinforcement Learning
Kaixiang Lin (Michigan State University); Renyu Zhao (AI Labs, Didi Chuxing); Zhe Xu (AI Labs, Didi Chuxing); Jiayu Zhou (Michigan State University)
Multi-task Representation Learning for Travel Time Estimation
Yaguang Li (University of Southern California); Kun Fu (DiDi AI Labs); Zheng Wang (DiDi AI Labs); Cyrus Shahabi (University of Southern California); Jieping Ye (DiDi AI Labs); Yan Liu (University of Southern California)
Large-Scale Order Dispatch in On-Demand Ride-Sharing Platforms: A Learning and Planning Approach
Zhe Xu (AI Labs, Didi Chuxing); Zhixin Li (AI Labs, Didi Chuxing); Qingwen Guan (AI Labs, Didi Chuxing); Dingshui Zhang (AI Labs, Didi Chuxing); Qiang Li (AI Labs, Didi Chuxing); Junxiao Nan (AI Labs, Didi Chuxing); Chunyang Liu (AI Labs, Didi Chuxing); Wei Bian (AI Labs, Didi Chuxing); Jieping Ye (AI Labs, Didi Chuxing)
Learning to Estimate the Travel Time
Zheng Wang (Didi Chuxing); Kun Fu (Didi Chuxing); Jieping Ye (Didi Chuxing)
昨天,我们重点对滴滴 KDD 2018 Poster 论文《Learning to Estimate the Travel Time》进行了介绍,本文则是对滴滴 KDD 2018 Oral 论文《Large‑Scale Order Dispatch in On‑Demand Ride‑Hailing Platforms: A Learning and Planning Approach》的详细解读。
在这篇文章中,滴滴技术团队在其 KDD 2017 论文《A Taxi Order Dispatch Model based On Combinatorial Optimization》的基础上,新设计了一种基于马尔可夫决策过程 (MDP) 的智能派单方法,通过将派单建模成为一个序列决策 (Sequential Decision Making) 问题,结合了强化学习和组合优化,能在即时完成派单决策的条件下,基于对全天供需、出行行为的预测和归纳,达到优化一天之内司机整体效率的效果,能在确保乘客出行体验的同时明显提升司机的收入。

这一事件在雷锋网学术频道 AI 科技评论旗下数据库项目「AI 影响因子」中有相应加分。
研究背景
移动出行的本质是在乘客和司机之间建立连接。在滴滴,平台日订单达 3000 万,高峰期每分钟接收超过 6 万乘车需求,如何设计一个更高效的匹配算法来进行司机和乘客的撮合也成为非常核心的问题。
当下滴滴的专车、快车等业务线已经在普遍使用智能派单模式,即从全局视角出发,由算法综合考虑接驾距离、服务分、拥堵情况等因素,自动将订单匹配给最合适的司机接单。论文所述的算法也是在这一派单模式下的改进。
然而实际上,出行场景下的司乘匹配非常复杂。一方面,高峰期出行平台每分钟会接到大量出行需求,一方面车辆会在路上不停地移动,可能几秒后这个司机就通过了一个路口,或是行驶上了高速路;不仅如此,每一次派单的决定也都在影响未来的司机分布。
这些都对算法提出更高的要求: 不仅需要足够高效,能快速地对司机和乘客进行动态、实时的匹配,秒级做出决策,同时还要能基于未来情况的预测,考虑匹配算法的长期收益。此外还要在考虑司机收入的同时保障用户体验,全局优化总体交通运输效率。
方法简述
为了解决上述问题,滴滴技术团队创新性地提出了一个融合强化学习和组合优化的框架。算法的主要思路如下:
1) 平台下发派单决策需要在秒级做出,同时每次决策的优化目标均为提升长期收益。由于该问题自然形成了序列决策 (Sequential Decision Making) 的定义,使用马尔可夫决策过程 (MDP) 进行建模,并用强化学习求解;
2) 针对司乘间多对多的匹配,建模成一个组合优化问题,以获得全局最优。
通过将二者结合,即将组合优化中的司机和乘客的匹配价值,用强化学习得到的价值函数 (Value Function) 来表示,即得到了所述的算法,其流程如下图所示。
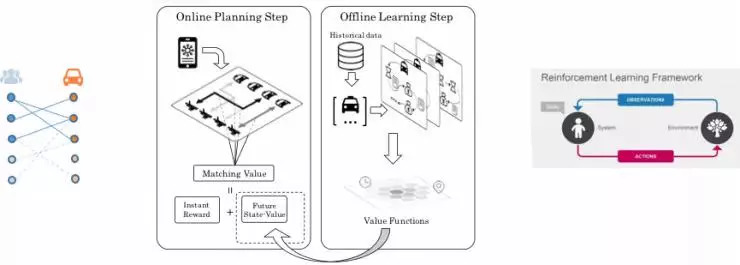
模型定义
这一定义的马尔可夫决策过程由以下模块组成:
智能体 (agent):定义每个司机为一个智能体。虽然此定义会使问题变为一个多智能体学习 (multi-agent) 求解问题,但单司机作为智能体的方式可大大减少状态和动作空间,使得求解变得可能;
状态 (state):状态 s 定义了司机所处的周边信息。为简化起见,论文定义司机所处的时间和空间为其状态,并将时空进行量化为 10 分钟的时间段和固定大小的区域。这样,一个完整的 episode(记为一天)由 144 个时间片组成,每个城市包含着数千至数万的区域单位。
动作 (action):动作 a 定义了司机的完成订单或空闲操作。对完成订单而言,司机会经过前往接乘客、等待乘客和送乘客到目的地等过程。
状态转移 (state transition) 与奖励函数 (rewards):完成订单的动作会自动使司机发生时空状态的转移,其同时会带来奖励,我们定义奖励 r 为订单的金额。
在定义了 MDP 的基本元素之后,下一步即选定一个最优的策略,使其最大化累积期望收益。
匹配策略
在此 MDP 的定义下,平台派单的过程即针对每一次分单的轮次(2 秒),平台会取得每个待分配司机的状态 s,并将所有待分配订单设为司机可执行的动作之一。该问题的优化目标是 在确保用户体验的基础上最大化所有司机的收益总和。论文将其建模为二分图匹配问题,使用 KM((Kuhn-Munkres) 算法进行求解。
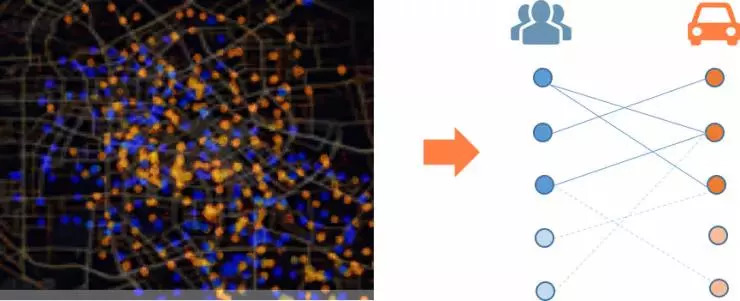
在二分图建图的过程中,某司机和某订单的边权实际上表示了司机在状态 s 下,执行完成订单的动作 a 下的预期收益,即强化学习中的动作价值函数 (Action-State Value Function) Q(s,a)。该函数表示了司机完成某订单后,可获得的预期收益,其包含了两部分:订单的即时收益 r,以及司机完成订单后新状态下的预期收益期望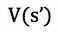
价值函数
如何评估司机出现在某个特定时间/空间时的价值也成为一个核心问题。在强化学习中的价值函数表示了智能体 (Agent) 在某状态下的预期累积收益的期望。而在滴滴这一场景中,司机处在某状态下的价值函数,则对应了在常态状态下司机出现在某时空位置下的预期流水收入。
通过将时间和空间进行量化,再基于滴滴平台上海量的历史数据资源,滴滴使用动态规划 (Dynamic Programming) 的方法求解出了每个时空状态下司机的预期收益,即价值函数。价值函数实际上代表了滴滴出行平台上供需状况的一种浓缩。下图显示了某城市晚高峰和平峰的价值函数示意。
价值函数和匹配策略相结合
将价值函数和组合优化的目标函数结合在一起,即形成了完整的派单方法。算法流程包括:
离线部分
步骤 1.1 收集历史数据中的订单信息,表示为强化学习中的四元组形式;
步骤 1.2 使用动态规划求解价值函数。将价值函数以查找表 (lookup table) 形式保存以供线上使用。
线上部分
步骤 2.1 收集待分配的司机和订单列表;
步骤 2.2 计算每个司乘匹配对应的动作价值数 (State-Action Function),并以此为权重建立二分图;
步骤 2.3 将上述匹配权值作为权重嵌入 KM 算法,充分考虑接驾距离、服务分等因素,求解最优匹配,进入最终派单环节。
迭代部分
步骤 3 迭代重复进行 1 和 2,即根据新积累的数据离线更新价值函数,和使用更新后的价值函数指导派单的过程。
线上使用
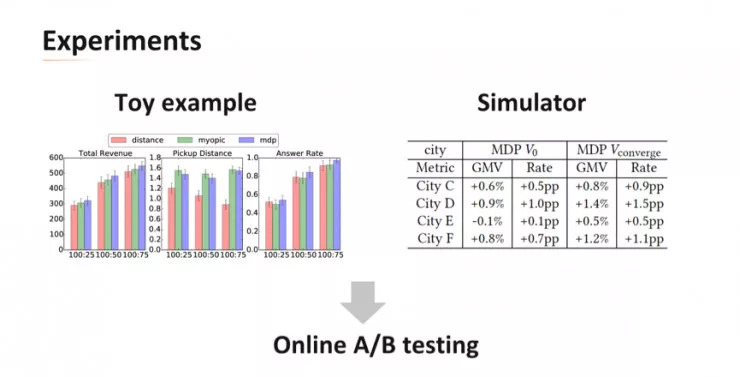
滴滴团队进行了大量的离线实验和在线 AB 测试,结果均显示,这种基于强化学习和组合优化的派单算法能在确保乘客出行体验的同时明显提升司机的收入。目前该算法已成功部署在滴滴平台二十多个核心城市,承接广大用户的出行需求。
结论和下一步计划
滴滴团队指出,与传统的「只考虑当下」的策略不同,这一全新的基于强化学习和组合优化的派单算法能能考虑到每一次派单的决定会对未来的司机分布发生影响,面向长期收益。后续将在深度 Q 学习 (DQN) 算法求解和不同城市间进行迁移学习等方面持续优化,并将持续拓展算法在其他应用场景中的应用。
(论文地址:Large‑Scale Order Dispatch in On‑Demand Ride‑Hailing Platforms: A Learning and Planning Approach
http://delivery.acm.org/10.1145/3220000/3219824/p905-xu.pdf?ip=183.240.196.144&id=3219824&acc=OPENTOC&key=4D4702B0C3E38B35%2E4D4702B0C3E38B35%2E4D4702B0C3E38B35%2E054E54E275136550&__acm__=1534949330_cd114e6e3a392b6b3eeabeafae021d77)
或点击文末阅读原文移步AI研习社社区打包下载四篇论文。






