这是美国密西根大学教授Satinder Singh长期以来致力于解决的问题。在2020北京智源大会上,Satinder Singh教授对这个问题进行了深度阐释,他通过Meta-Gradient方法来学习发现以往强化学习智能体中需要手动设置的参数:内在奖励和辅助任务问题。
Satinder Singh从近期关于强化学习的两个研究工作出发,针对如何通过数据驱动的方式学习到内在奖励函数,他提出了一个学习跨多生命周期(Lifetime)内部奖励函数的Meta-Gradient框架,同时设计了相关实验证明学习到的内在奖励函数能够捕获有用的规律,这些规律有助于强化学习过程中的Exploration和Exploitation,并且可以迁移到到不同的学习智能体和环境中。
针对于如何在数据中发现问题作为辅助任务,他扩展通用辅助任务架构,参数化表示General Value Functions,并通过Meta-Gradient方法学习更新参数发现问题。实验证明这个方法可以快速发现问题来提高强化学习效果。
Satinder Singh,美国密西根大学教授,Deep Mind科学家,AAAI Fellow。主要研究兴趣是人工智能(AI)的传统目标,即构建能够学习在复杂、动态和不确定环境中具有广泛能力的自主智能体。目前的主要研究是将深度学习与强化学习结合起来。
“发现”的意义
什么是强化学习中的“发现”?简单的思考方式是强化学习智能体中的参数可以分成两部分:一部分参数是从数据中学习发现得到,另一部分是由研究人员根据经验手动设置。Satinder Singh教授的报告主要讨论他和他的团队如何尝试通过Meta-Gradient方法来学习发现参数。
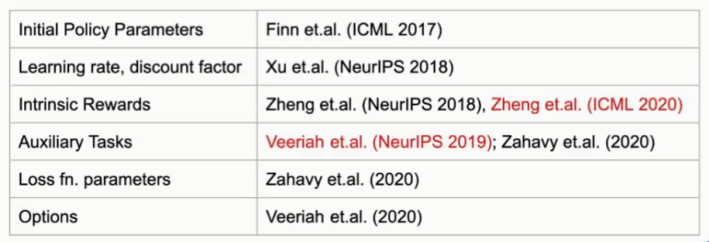
在强化学习中,策略(Policy)函数和价值(Value)函数的参数值通常从数据中学习得到。对于那些通常手动设置的参数,如图1所示,表格中是最新论文中的一些例子以及它们的出处。这些例子都是采用Meta-Gradient方法发现参数。有些通过元学习(Meta-Laring)发现一个好的策略参数初始值。有些是用Meta-Gradient方法发现学习率(Learing Rate)和折扣因子(Discount Factor)。有些是用Meta-Gradient方法发现内在奖励(Intrinsic Rewards)和辅助任务(Auxiliary Tasks)等。
在本次报告中,Satinder Singh教授主要分享他和他的团队近期发表在ICML 2020和NeurIPS 2019中的两篇论文的相关研究工作(图1中标红的两篇)。虽然有许多不同的发现方法,比如:基于人口的方法(Population Based Method)、进化方法(Revolution Method),但是Satinder Singh教授他们只是采用启发式搜索方法发现超参数值。这次报告的重点是采用Meta-Gradient方法发现参数。
内在奖励
第一项工作由Satinder Singh教授和他的博生生共同完成的。文章的题目是:《What can Learned Intrinsic Rewards Capture ?》[1]
2.1 研究动机
在强化学习中,智能体有很多结构存储知识。这些结构分为:常见结构(Common Structure)和非常见结构(Uncommon Structure)。其中, 常见结构有:策略(Policies)、价值函数(Value Functions)、环境模型(Models)和状态表示(State Representations)等。在本次报告中,主要关注非常见结构:奖励函数(Reward Function)。之所以是非常见结构是因为在强化学习中这些奖励通常都是根据环境决定,并且是不可改变的。
在论文中,将强化学习问题中的奖励函数分为外在奖励(Extrinsic Rewards)和内在奖励(Intrinsic Rewards)。外在奖励用来衡量智能体的性能,通常是不能改变的。内在奖励是智能体内部的。在内在奖励中,有很多方法用来存储知识,但是这些方法都是手动设计的,比如:Reward Shaping、Novelty-Based Reward、Curiosity-Driven Reward等。这些手动的内在奖励方法都依赖领域知识或者需要细致的微调才能起作用。在本次报告中,Satinder Singh主要关注两个研究问题:
1、是否能够通过数据驱动的方式,学习得到一个内在奖励函数?
2、通过学习到的内在奖励函数,什么样的知识能够被捕获到?
针对第一个问题,论文中提出了一个学习跨多生命周期Lifetime)内部奖励函数的可扩展的Meta-Gradient框架。针对第二个问题,论文中设计了一系列的实验,通过实验证明:1)学习到的内在奖励函数能够捕获有用的规律,这些规律有助于强化学习过程中的Exploration和Exploitation;2)学习到的内在奖励函数可以推广到不同的学习智能体和不同的环境中;3)内在奖励函数可以捕获知识告诉智能体要做什么而不是怎么做,策略是用来告诉智能体应该怎么做。
2.2 Optimal Reward Framework
![]() 图
2:基于多生命周期的最优奖励框架
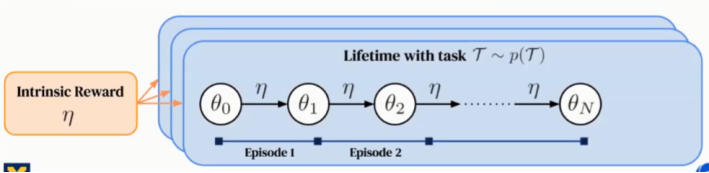
研究的目标是从经验中学习到有用的内在奖励,论文中考虑多生命周期(Multiple Lifetime)的情况(如图2所示)。涉及到的相关概念定义如下:
生命周期(Lifetime):是指由多个情节(Episodes)构成的智能体的整个训练时间。生命周期可以有成千上万的情节。每个情节有多个不同的参数更新(如图1所示)。在生命周期的开始,智能体被按照一定分布随机采样的任务初始化。在实验过程中,任务可以是静态(Stationary)或非静态(Non-Stationary)的。当情节属于一个生命周期时,任务随着时间改变。
内部奖励(Intrinsic Reward):在一个生命周期内被用来训练智能体策略(Policy),策略不能看到外在奖励,只能利用内部奖励更新参数。
最优奖励问题(Optimal Reward Problem):是指学习跨多生命周期的内在奖励函数。通过训练多个随机初始化的策略,获得累积最优的外在奖励。
目前针对最优化内在奖励函数,仍然存在两个开发不足的方面。
1、内在奖励函数的输入应该是整个生命周期的行为历史而不是情节(Episode)内的行为历史。这样有助于强化学习中的Exploration。这是因为Exploration需要关注跨多个Episodes的发生情况,即当进行探索时,需要观察整个生命周期内的行为历史。
2、需要最大化整个长生命周期的返回(Lifetime Return),而不是单个情节的返回(Episodic Return)。这样可以有更多空间来平衡跨多个场景之间的Exploration和Exploitation。
针对以上的不足,Satinder Singh教授和他的团队提出一个Scalable Gradient-Based的方法来解决最优化内在奖励的问题。
图
2:基于多生命周期的最优奖励框架
研究的目标是从经验中学习到有用的内在奖励,论文中考虑多生命周期(Multiple Lifetime)的情况(如图2所示)。涉及到的相关概念定义如下:
生命周期(Lifetime):是指由多个情节(Episodes)构成的智能体的整个训练时间。生命周期可以有成千上万的情节。每个情节有多个不同的参数更新(如图1所示)。在生命周期的开始,智能体被按照一定分布随机采样的任务初始化。在实验过程中,任务可以是静态(Stationary)或非静态(Non-Stationary)的。当情节属于一个生命周期时,任务随着时间改变。
内部奖励(Intrinsic Reward):在一个生命周期内被用来训练智能体策略(Policy),策略不能看到外在奖励,只能利用内部奖励更新参数。
最优奖励问题(Optimal Reward Problem):是指学习跨多生命周期的内在奖励函数。通过训练多个随机初始化的策略,获得累积最优的外在奖励。
目前针对最优化内在奖励函数,仍然存在两个开发不足的方面。
1、内在奖励函数的输入应该是整个生命周期的行为历史而不是情节(Episode)内的行为历史。这样有助于强化学习中的Exploration。这是因为Exploration需要关注跨多个Episodes的发生情况,即当进行探索时,需要观察整个生命周期内的行为历史。
2、需要最大化整个长生命周期的返回(Lifetime Return),而不是单个情节的返回(Episodic Return)。这样可以有更多空间来平衡跨多个场景之间的Exploration和Exploitation。
针对以上的不足,Satinder Singh教授和他的团队提出一个Scalable Gradient-Based的方法来解决最优化内在奖励的问题。
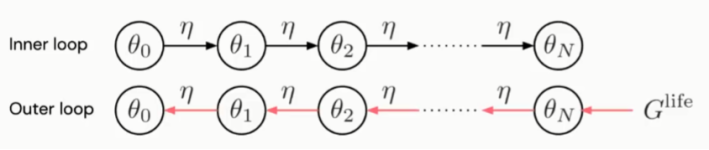
2.3 Truncated Meta-Gradients with Bootstrapping
Meta-Gradient方法有两个循环,分别是:内部循环(Inner Loop)和外部循环(Outer Loop)。
内部循环在强化学习中很常见,如图3所示,在展开的计算图中进行策略参数(q)更新,直到生命周期结束。外部循环是指在整个生命周期通过反向传播方法,更新内在奖励函数参数(h)。内在奖励函数可以是一个单独的神经网络或者是循环神经网络(RNN)。神经网络的节点与生命周期中各情节的行为历史对应,构成整个生命周期的行为历史。Meta-Gradient方法的核心思想是:在内部循环中的策略参数更新是关于内在奖励函数参数可微到。因此,如果我们能够展开计算图,在整个生命周期内更新策略参数(q),那么就可以通过这个巨大的计算图反向传播计算关于内在奖励函数参数(h)的Meta-Gradients。
当然,由于受到内存空间的限制,这是展开整个计算图更新参数是不可行的。这也是为什么之前的一些Meta-Gradients方法在更新了少量q参数后就调优情节返回(Episode Return)的原因。为了解决这个挑战,Satinder Singh教授他们仍然采用了截断计算图只更新少量参数的方法。但是他们采用生命周期价值函数(Lifetime Value Function)来近似截断内部循环参数更新之后的其他未展开计算图节点的生命周期奖励(如图4所示)。这个生命周期价值函数在未来不仅用来预测整个生命周期外部奖励同时不断的更新内部循环中的参数q。因此这个价值函数是在多生命周期间进行训练。
图4:Truncated Meta-Gradients with Bootstrapping
2.4 实验
Satinder Singh教授分享了他们是如何实验通过Meta-Gradients方法更新内部奖励函数参数的。
2.4.1方法(Methodology)
3、评价分析学习到的内部奖励函数在新的生命周期的效果。
2.4.2 探索不确定状态
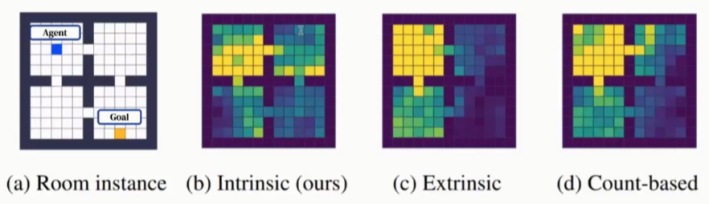
实验设置如图5所示,引入四个环境房间,智能体(图中蓝色方块)在每个Episode中找到不可见的目标位置。这个目标位置在不同的生命周期不同,由随机采样得到。但是每个生命周期的目标位置是确定的。如果智能体到达目标位置,则当前Episode结束。
这个实验中的最优表现应该是:在生命周期的第一个Episode,智能体可以高效的探索整个房间来找到目标位置。当找到目标位置,则第一个Episode结束。从第二个Episode开始,智能体能够记住目标位置在哪并直接到达目标位置。
图6中展示了生命周期内智能体的探索轨迹,图(a)中黄色的位置代表对于智能体不可见的目标位置,(b)是智能体采用学习到的内在奖励函数方法,(c)是智能体采用外部奖励方法,(d)是智能体采用Count-Based Exploration 方法。可以看到,(b)中有更多的黄色和绿色充满了四个房间,这表明采用学习到的内在奖励函数在探索过程中表现更好。
2.4.3 探索不确定的目的
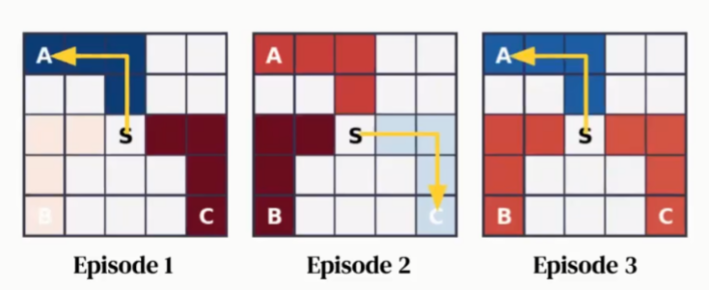
实验设置如图7所示,有三个目的(Object)A、B、C,它们分别具有不同的奖励,A表示不好也不坏,B表示总是坏的,C表示并没有那么好。这些Object在不同的生命周期内不同,通过随机采样产生,在特定的生命周期内是固定的。智能体收集到这三个目的中的任何一个,则该Episode结束。
在这个实验中,我们希望学习到内在奖励函数可以捕获到的规律是:规避B,因为它总是不好的,同时可以快速的指出A和C到底哪个更好,并在剩下的生命周期内总是做出最好的选择。为了学到这些规律,智能体需要跨多个Episode进行探索学习。图8展示了不同的Episode中探索到的Object,图中每个方格代表每个轨迹中积累的内在奖励,蓝色代表正的奖励,红色代表负的奖励。可以看到在Episode 1中,推荐Object A,在Episode 2中推荐Object C,在Episode 3中推荐Object A,整个过程中都没有推荐Object B,它的颜色总是红的。
2.4.4 处理非固定任务
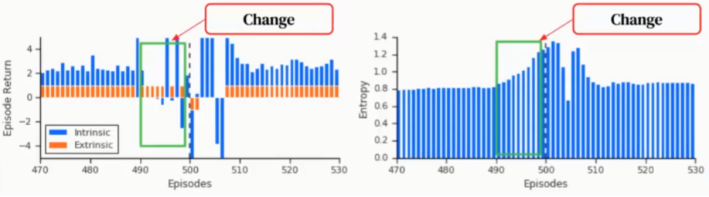
在这个实验中,假设A和C的外部奖励在一定时间后会发生变化,智能体需要学习预测这个变化是在什么时候发生,以此来改变策略适应新的任务。图9展示了实验结果,左侧图中蓝色柱状条代表内部奖励,在开始时内部奖励一直是正的,大约在Episode 400接近500的时候,内在奖励开始变为负值(绿色框的部分),即智能体开始缓慢的调整策略,到达Episode 500时,策略调整为一个新的行为来应对新的任务。
右侧图展示了整个过程策略的Entropy变化,可以看到在前400个Episodes中Entropy一直保持很小,当内部奖励为负值时,智能体不知道任务会如何改变,因此它的Entropy开始增加。紧接着,智能体可以快速学习到这些改变,做出策略调整,快速适应新的任务。
2.4.5 性能(performance)
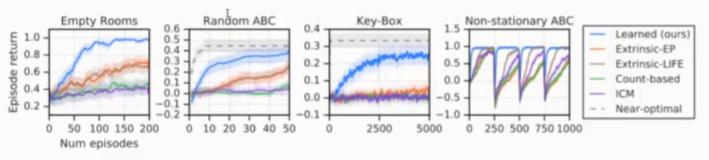
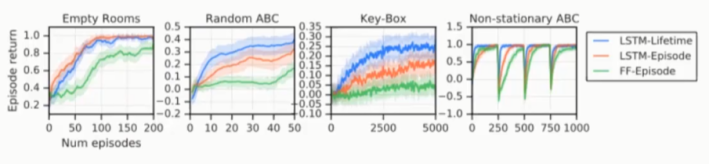
设计实验与手动设置内部奖励方法进行比较,如图10所示,前三个子图代表静态任务,在三个子图中学习到的内在奖励函数获得最高的Episode Return。最后一个子图代表非静态任务,可以看到在任务发生改变时通过学习到的内在奖励函数智能体的表现可以最快的恢复到最佳状态。
图10:Learned v.s. Handcrafted Intrinsic Rewards
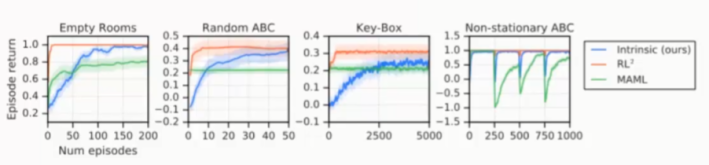
图11:Comparison to policy transfer methods
图11中展示的是与策略转移(Policy Transfer)方法(比如:MAML、RL2)的实验比较结果,可以看出内部奖励方法的表现优于MAML,最终达到同RL2一样的效果。这是因为内部奖励方法需要从部分Episode中学习策略,而RL2有一个好的初始化策略。
2.4.6迁移到新智能体环境
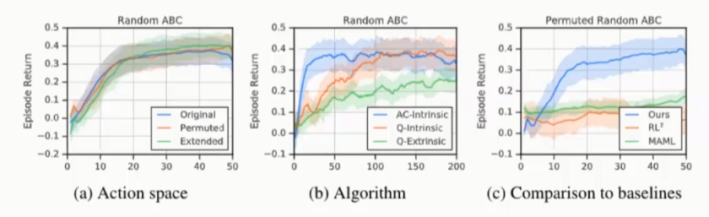
因为有些情况下策略是不能转移的,所以通用转移内部奖励比策略转移更可行。图12中,采用新的动作空间(Action Space)来验证训练得到的内部奖励,因此策略无法进行转移。Permuted Actions是指左/右和上/下的语义相反,Extended Actions是指添加4个对角移动的动作。从图中可以看到学习到的内在奖励可以很好的转移到新的动作空间中,对新环境是敏感的。
图12:Generalisation to new agent-environment interfaces in Random ABC
2.4.7 Ablation Study
如图13所示,蓝色曲线代表将Lifetime的历史行为作为输入的LSTM内部奖励网络,橙色曲线代表将Episode历史行为作为输入的LSTM内部奖励网络,绿色带表去掉Lifetime历史行为。从图中可以看出绿色曲线表现最差。这表明智能体在探索过程中,Lifetime History很重要。橙色曲线基本都比绿色曲线表现差,这也表明了long-term Lifetime History在智能体平衡Exploration和Exploitation过程中是必需的。
图13:Evaluation of different intrinsic reward architectures and Objectives
2.4.8 总结
文章中证明通过Meta-Gradient方法可以学习到有用的内在奖励。学习内在奖励可以捕获到有用的规律应用于智能体的Exploration和Exploitation。同时捕获到的知识可以迁移到其他学习环境的智能体上。目前该方法仍然太简单,有很多限制,Satinder Singh教授他们未来将研究在更加复杂环境下的内在奖励学习。
辅助任务
第二项工作由Satinder Singh教授和他的DeepMind同事共同完成的。文章的题目是:《Discovery of Useful Questions as Auxiliary Tasks》[2]。
3.1 预测问题
基本上所有的机器学习研究都是通过学习回答预先定义好的问题。为了能够实现更一般的人工智能,智能体需要能够自己发现问题并回答这些问题。在本文中,作者关注于将发现问题作为辅助任务来帮助构造智能体的表示。
3.2 General Value Functions (GVFs)
General value Functions是指表示任意状态特征的价值函数,是强化学习中的价值函数的扩展,它可以由如下公式表示。
由于GVFs可以表达丰富的预测知识,因此被成功的用作辅助任务。
3.3 发现问题辅助任务架构
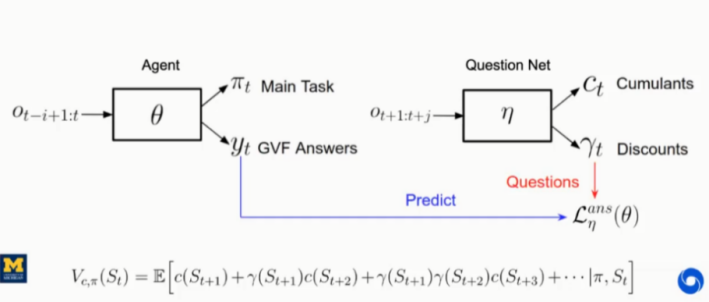
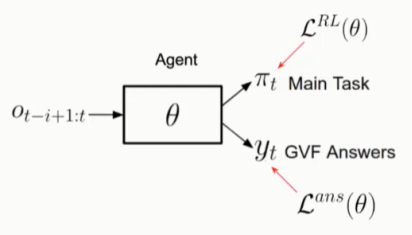
图14中展示的是通用辅助任务架构,以最近一次的观察作为输入,q为模型参数,输出为任务策略和预先定义的问题的回答(GVF)。
在训练过程中,损失函数包含两部分,分别为:主任务损失函数
![]() 和辅助任务损失函数
和辅助任务损失函数
![]() 。本文中提出将发现问题作为辅助任务,而不只是回答问题,架构如图15所示。针对于发现问题,提出单独的问题网络,用未来的观察作为输入,h表示参数,输出为累积向量和折扣因子向量。注意:未来的观察只能在训练阶段可以获取到,无法在验证阶段获得。但这对于本文提出的方法没有影响,因为本身在验证阶段就不需要问题,只需要在训练阶段提供与回答网络相对应问题的语义表示。
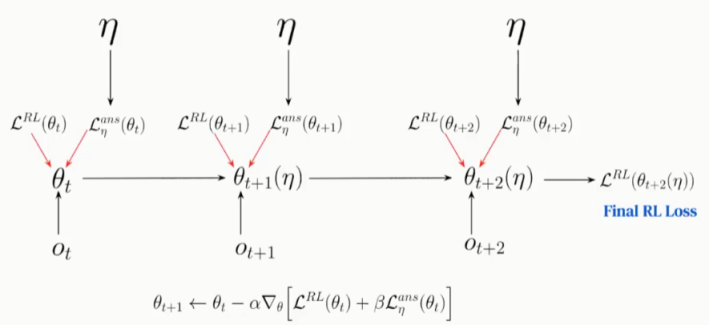
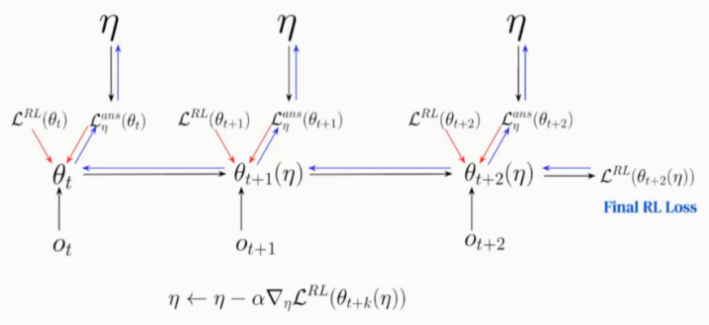
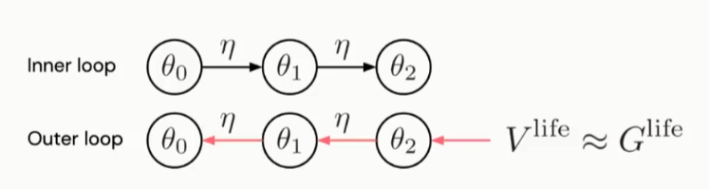
文中采用Meta-Gradients方法学习更新参数,具体的参数更新过程如图16、17所示。
图16:Meta-Gradients(inner-loop)
图17:Meta-Gradients(outer-loop)
。本文中提出将发现问题作为辅助任务,而不只是回答问题,架构如图15所示。针对于发现问题,提出单独的问题网络,用未来的观察作为输入,h表示参数,输出为累积向量和折扣因子向量。注意:未来的观察只能在训练阶段可以获取到,无法在验证阶段获得。但这对于本文提出的方法没有影响,因为本身在验证阶段就不需要问题,只需要在训练阶段提供与回答网络相对应问题的语义表示。
文中采用Meta-Gradients方法学习更新参数,具体的参数更新过程如图16、17所示。
图16:Meta-Gradients(inner-loop)
图17:Meta-Gradients(outer-loop)
3.4 实验
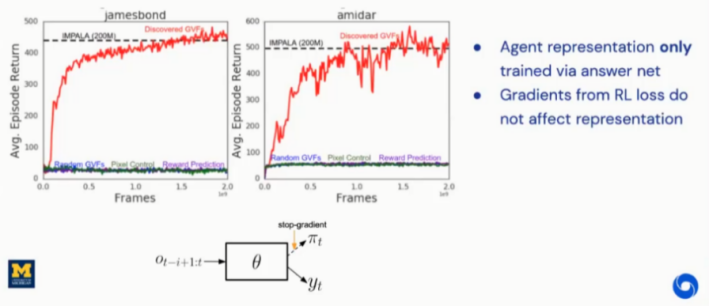
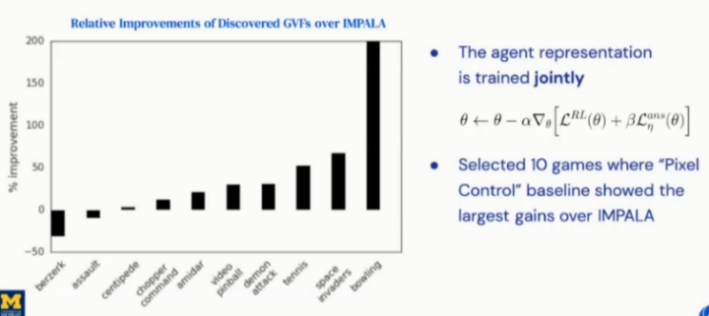
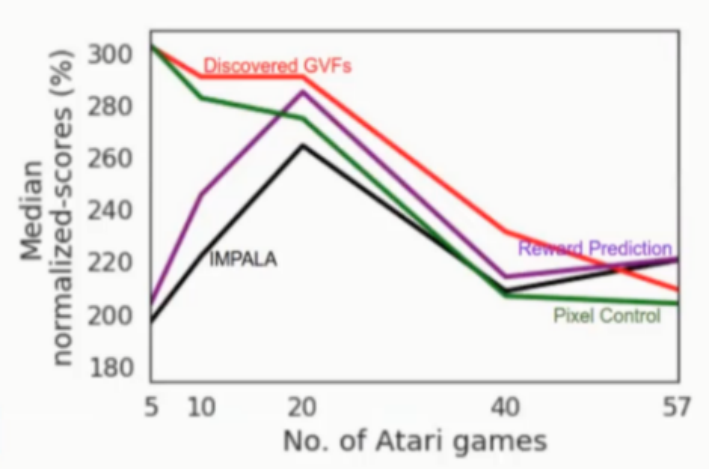
为了验证发现问题辅助方法效果,作者设计了两组实验,分别为:只有辅助任务学习更新参数(图18)、主任务和辅助任务共同学习更新参数(图19),同时设计问题发现辅助任务方法与其他辅助任务方法进行比较(图20)。实验结果显示采用问题发现辅助任务方法更新参数达到最好的效果。
图18:Representation Learning Experiments
图19:Joint Learning Experiments
图20:Comparison of Auxiliary Tasks on ATARI
3.5 总结
文章中提出的方法解决了在强化学习领域如何从自身数据中发现问题作为辅助任务的方法。这个方法可以快速发现问题来提高强化学习效果,但是仍然存在一些限制,比如:计算长序列问题参数更新受内存大小影响。这也是Satinder Singh教授他们未来的研究方向。
结语
Satinder Singh教授分享了他的团队最近的两篇研究工作[1]和[2],讨论了如何将Meta-Gradient方法应用的学习发现强化学习智能体中的内在奖励和辅助任务问题中。并通过实验证明通过数据驱动的方式可以发现很多有用的知识来优化强化学习效果。
Q&A
Q1:在强化学习中,内在奖励学习和熵正则化之间的关系?
Singh:让我用两种方式来回答。第一种是可以通过Meta-Gradient方法来学习熵正则化系数。Deepmind的Junhyuk Oh曾经采用过类似的方法,利用反向传播方法学习熵正则化。第二种是熵正则化可以看成是一种质量比较差的探索方法,它无法学习到有用的探索策略。内在奖励学习可以跨多个epsoides学习到有用的知识,这一点熵正则化是无法做到的,但它确实是另外一种特别的探索方法。
Q2:你主要关注Meta-Gradient框架,请问您有什么理论能保证性能吗?比如:什么场景下效果会更好?
Singh:简单来说,Meta-Gradient就是不断的进行梯度计算。我们采用类似local minimize optimization等方法保证Meta-Gradient性能。但是这些计算是受内存限制的,仍然存在很大的挑战。简短的回答就是:我们没有很强的理论保障。但是我认为这里有很多有趣的工作值得去做。
[1] Zheng Z, Oh J, Hessel M, et al. What Can Learned Intrinsic Rewards Capture?[J]. arXiv preprint arXiv:1912.05500, 2019.
[2] Veeriah V, Hessel M, Xu Z, et al. Discovery of useful questions as auxiliary tasks[C]//Advances in Neural Information Processing Systems. 2019: 9310-9321.
AI科技评论联合博文视点赠送周志华教授“森林树”十五本,在“周志华教授与他的森林书”一文留言区留言,谈一谈你和集成学习有关的学习、竞赛等经历。
AI 科技评论将会在留言区选出15名读者,每人送出《集成学习:基础与算法》一本。
活动规则:
1. 在“周志华教授与他的森林书”一文留言区留言,留言点赞最高的前 15 位读者将获得赠书。获得赠书的读者请联系 AI 科技评论客服(aitechreview)。
2. 留言内容会有筛选,例如“选我上去”等内容将不会被筛选,亦不会中奖。
3. 本活动时间为2020年8月23日 - 2020年8月30日(23:00),活动推送内仅允许中奖一次。
阅读原文,直达“ KDD”小组,了解更多会议信息!

 图
2:基于多生命周期的最优奖励框架
图
2:基于多生命周期的最优奖励框架


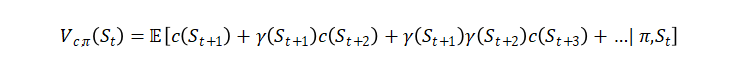
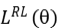 和辅助任务损失函数
和辅助任务损失函数
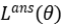 。本文中提出将发现问题作为辅助任务,而不只是回答问题,架构如图15所示。针对于发现问题,提出单独的问题网络,用未来的观察作为输入,h表示参数,输出为累积向量和折扣因子向量。注意:未来的观察只能在训练阶段可以获取到,无法在验证阶段获得。但这对于本文提出的方法没有影响,因为本身在验证阶段就不需要问题,只需要在训练阶段提供与回答网络相对应问题的语义表示。
。本文中提出将发现问题作为辅助任务,而不只是回答问题,架构如图15所示。针对于发现问题,提出单独的问题网络,用未来的观察作为输入,h表示参数,输出为累积向量和折扣因子向量。注意:未来的观察只能在训练阶段可以获取到,无法在验证阶段获得。但这对于本文提出的方法没有影响,因为本身在验证阶段就不需要问题,只需要在训练阶段提供与回答网络相对应问题的语义表示。