近日,来自 FAIR 的研究者提出结合自训练和无监督预训练执行语音识别任务,证明这两种方法存在互补性,并取得了不错的结果。
自训练和无监督预训练成为使用无标注数据改进语音识别系统的有效方法。但是,我们尚不清楚它们能否学习类似的模式,或者它们能够实现有效结合。
最近,Facebook 人工智能研究院(FAIR)一项研究展示了,伪标注和使用 wav2vec 2.0 进行预训练在多种标注数据设置中具备互补性。
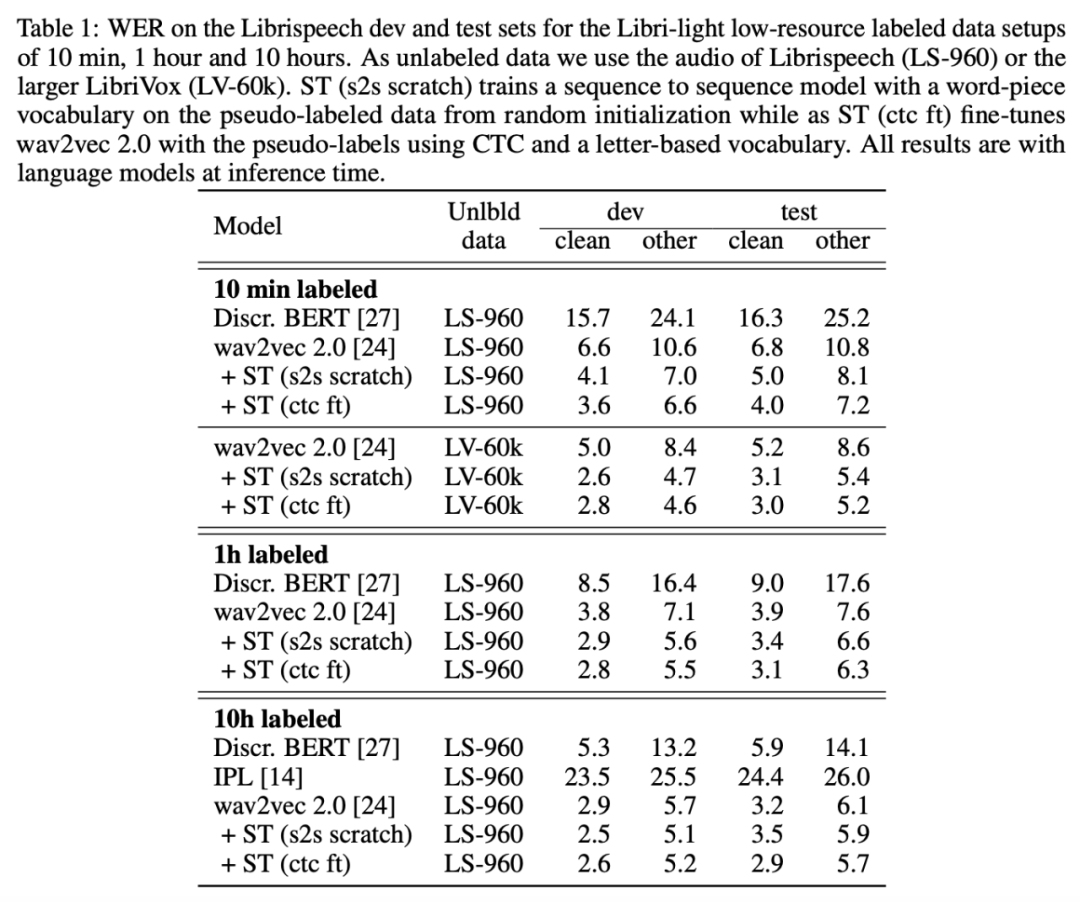
只需来自 Libri-light 数据集的 10 分钟标注数据和来自 LibriVox 数据集的 5.3 万小时无标注数据,该方法就能在 Librispeech clean 和 other 测试集上取得 3.0%/5.2% 的 WER(词错率),甚至打败了仅仅一年前基于 960 个小时标注数据训练的最优系统。在 Librispeech 所有标注数据上训练后,该方法可以达到 1.5%/3.1% 的词错率。
![]()
论文链接:https://arxiv.org/pdf/2010.11430.pdf
近期,基于标注语音数据的语音识别模型取得了显著进展。但这些模型存在一个缺陷:它们需要大量标注数据,而这些数据仅针对英文和少数几种语言。因此,纯监督式的训练对于全球 7000 种语言中的绝大多数是不可行的,因此很多人对如何更好地利用无标注语音数据产生了极大兴趣。
利用无标注数据的方法包括经典的自训练,这类方法对无标注音频数据进行伪标注,并使用额外标注数据对系统进行重新训练,取得了不错的结果。另一类工作是先在无标注语音数据上预训练表征,然后在标注数据上进行微调。
Facebook 这篇论文将自训练和无监督预训练结合起来。这两种利用无标注数据的方法在基准上都取得了不错的结果,该研究想要解决的核心问题是它们能否互补。具体而言,该研究基于最近提出的 wav2vec 2.0 模型与 Kahn et al. (2020; [13]) 和 Xu et al. (2020; [14]) 提出的自训练方法进行,探索了从头开始基于伪标注数据训练模型,以及对预训练模型进行微调。为了更好地了解这两种方法的互补性,研究人员使用了相同的无标注数据。
在 Librispeech 完整数据集和 Librilight 低资源标注数据设置下,自训练和无监督预训练具备互补性,这与近期自然语言理解领域的研究结果一致。仅使用 10 分钟的标注数据和 LibriVox 无标注数据,wav2vec 2.0 和自训练方法的结合体就在 Librispeech clean 和 other 测试集上取得 3.0%/5.2% 的词错率,相比仅使用预训练方法的近期研究 [24] 词错率分别降低了 25% 和 40%。这一结果支持了该假设:自训练将伪标注所用的语言模型融入进最终模型。在 960 小时标注数据上训练后,该方法可以达到 1.5%/3.1% 的词错率。
该研究使用了 Librispeech 数据集(约有 960 个小时的音频)和 LibriVox (LV-60k) 数据(经过预处理后,包含约 5.3 万小时的音频)。
研究人员考虑了五种标注数据设置:Librispeech 的全部 960 小时标注数据和 train-clean-100 子集(100 小时数据),Libri-light 有限资源训练子集 train-10h (10h)、train-1h (1h) 和 train-10min (10min)。该研究在 Librispeech dev-other/clean 和 test-clean/other 数据集上进行方法评估。
该研究使用了 wav2vec 2.0 预训练模型(https://github.com/pytorch/fairseq/tree/master/examples/wav2vec)。该库提供针对上述五种标注数据设置的微调模型。
至于自训练,研究人员使用基于不同标注数据设置微调过的 wav2vec 2.0 LARGE 模型对 LS-960 或 LV-60k 音频数据执行伪标注。
最后,研究人员按照 Synnaeve et al. (2020; [2]) 的方式,并在使用 wav2letter++ [37] 执行伪标注后,利用 log-Mel filterbank 输入训练一个基于 Transformer 的序列到序列模型。编码器使用包含 4 个时间卷积层的卷积前端模块(滤波器宽度为 3),然后是 36 个 Transformer 块(模型维度为 768、注意力头数量为 4、前馈网络维度为 3072)。该模型包含约 3 亿参数。
下表 1 展示了,在所有低资源数据设置中,结合预训练和自训练 (wav2vec 2.0 + ST) 后的性能超过仅使用预训练 (wav2vec 2.0) 的性能。在 10h labeled 设置中,该方法相比迭代伪标注方法 [14] 有大幅提升。
![]()
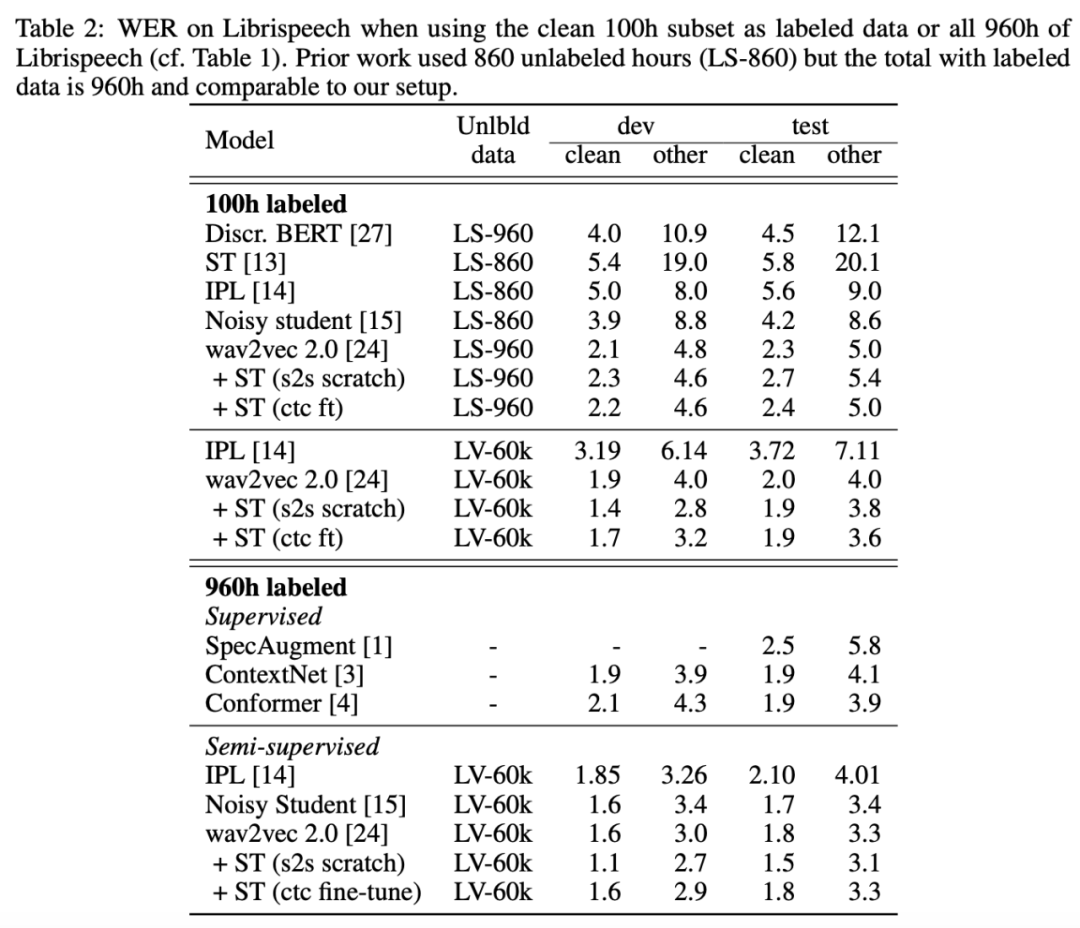
该研究在 Librispeech 100h clean 子集和 Librispeech 960h labeled 数据集上进行评估。下表 2 显示,在 100h labeled 设置下,LS-960 作为无标注数据时该研究提出的方法无法超过基线模型。但是使用更大规模的 LV-60k 作为无标注数据时,该方法性能有所提升,在 test-other 测试集上的词错率比 wav2vec 2.0 降低了 10%。
![]()
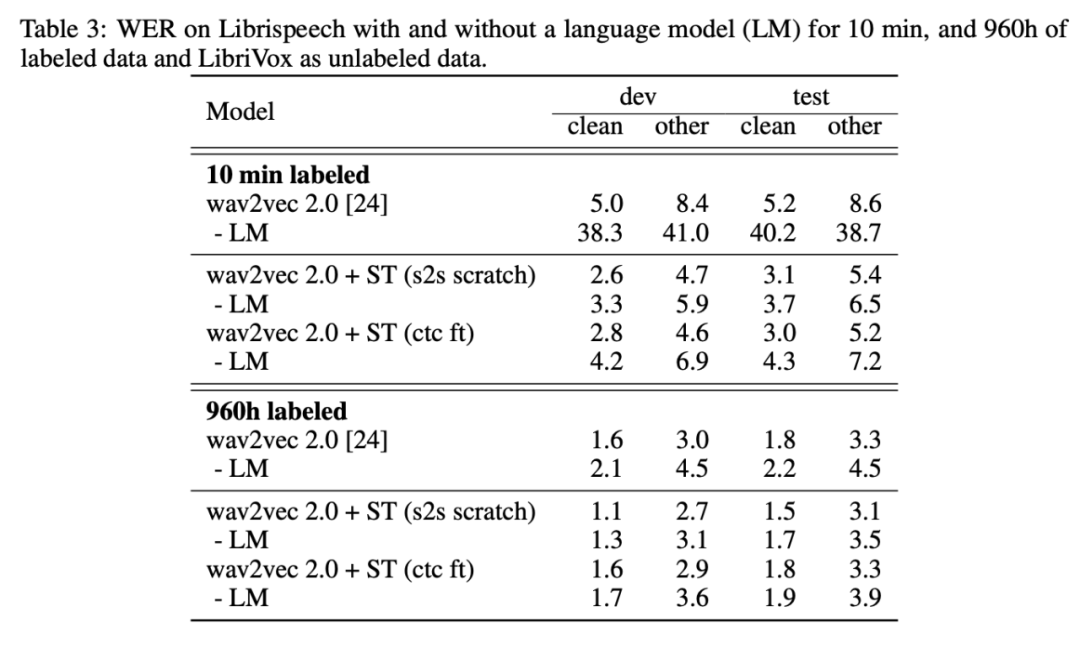
下表 3 展示了,在没有语言模型的情况下,自训练和预训练的结合仍能取得不错的性能。这是因为伪标注过程中使用的语言模型已被部分融入伪标注数据中。在没有语言模型的 10 min labeled 设置下这一效应尤其显著:在 test-other 数据集上,wav2vec 2.0 + ST (s2s scratch) 将基线方法 (wav2vec 2.0 - LM) 的词错率降低了 83%。
![]()
Java工程师入门深度学习(三):轻松上手Deep Java Library
DJL是亚马逊推出的开源的深度学习开发包,它是在现有深度学习框架基础上使用原生Java概念构建的开发库。DJL目前提供了MXNet,、PyTorch和TensorFlow的实现。Java开发者可以立即开始将深度学习的SOTA成果集成到Java应用当中。
11月5日20:00
,魏莱(AWS算法工程师)将带来线上分享,介绍DJL主要模块并结合具体场景讲解各模块的使用方法、主要API的使用方法和注意事项、神经网络从训练到部署的基本流程并结合动手深度学习Java版讲解具体代码和实操展示。
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com