谷歌大脑2017总结 | Jeff Dean执笔,干货满满

谷歌AI Senior Fellow、谷歌大脑负责人Jeff Dean,按照惯例,日前发布了2017年度的谷歌大脑年度总结。
在这份已经发布的总结中,Jeff Dean回顾了谷歌大脑团队过去一年的核心研究,以及在多个AI领域的研究进展。
Jeff Dean还把相关研究的论文等一并附上,堪称良心之作,值得收藏。

以下是最新发布的总结(灰色字体为编者注):
上篇
作为谷歌整体人工智能计划的一部分,谷歌大脑团队致力于通过研究和系统工程,提升人工智能的技术水平。我们去年分享了2016年的工作总结。从那以后,我们在提升机器智能这个长期研究项目上继续取得进展,并与谷歌和Alphabet的多个团队合作,使用我们的研究成果来改善人们的生活。
我们将为2017年撰写两篇总结文章,这是第一篇,包括我们的一些基础研究工作,以及关于开源软件、数据集和机器学习的新硬件的更新。第二篇文章的重点是探讨我们针对机器学习能产生巨大影响的领域展开的深入研究,如医疗、机器人和一些基础科学领域,以及我们在创造性、公平和包容等方面所作的工作,并让你更加深入地了解我们。
核心研究
我们团队的一个研究重点是促进我们的理解力和提高我们解决机器学习领域新问题的能力。以下是我们去年研究的几大主题。
AutoML
自动化机器学习的目标是开发各种技术,让计算机自动解决新的机器学习问题,而不需要人类机器学习专家逐一干预。如果我们有朝一日真的能有真正的智能系统,这就是我们所需的基本能力。
我们开发了利用强化学习和进化算法设计神经网络体系结构的新方法。
注释:AutoML在去年5月的2017 Google I/O开发者大会上首次正式发布。这个新方法意在让让神经网络去设计神经网络,谷歌希望能借AutoML来促进深度学习开发者规模的扩张,让设计神经网络的人,从供不应求的PhD,变成成千上万的普通工程师。
在AutoML中,一个主控的神经网络可以提出一个“子”模型架构,并用特定的任务来训练这个子模型,评估它的性能,然后,主控收到反馈,并根据反馈来改进下一个提出的子模型。
这个过程,简单来说就是:生成新架构-测试-提供反馈供主控网络学习。在重复上千次后,主控网络学会了哪些架构能够在已知验证集上得到更高的准确率。
将此项工作扩展到ImageNet最新分类和检测结果中,并展示了如何自动学习新的优化算法和有效的激活函数。我们正积极与我们的云人工智能团队合作,将这项技术提供给谷歌客户使用,并继续在多方面推动该研究。
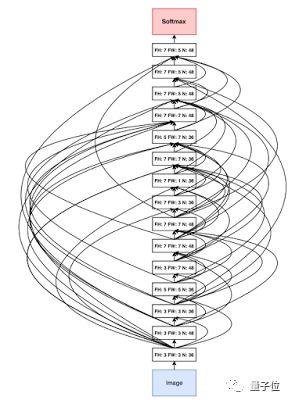
去年11月,谷歌对AutoML进行了升级。此前AutoML能设计出与人类设计的神经网络同等水平的小型神经网络,但始终被限制在CIFAR-10和Penn Treebank等小型数据集上。
为了让这种方法应用到ImageNet中,研究人员对AutoML做了两点调整,方便更容易地处理大型数据集。
相关论文:
Neural Optimizer Search with Reinforcement Learning
https://arxiv.org/abs/1709.07417
Searching for Activation Functions
https://arxiv.org/abs/1709.07417
语音理解和生成
另一个主题是开发新技术,提高我们的计算系统在理解和生成人类语音方面的能力,包括我们与谷歌语音团队合作为一个端到端语音识别方法开发了一系列改进措施,把谷歌语音识别系统的相对词错误率降低了16%。这项工作有一个好处,那就是需要融合很多独立的研究线索。
相关论文:
State-of-the-art Speech Recognition With Sequence-to-Sequence Models
https://arxiv.org/abs/1712.01769
Minimum Word Error Rate Training for Attention-based Sequence-to-Sequence Models
https://arxiv.org/abs/1712.01818
Multi-Dialect Speech Recognition With A Single Sequence-To-Sequence Model
https://arxiv.org/abs/1712.01541
Multilingual Speech Recognition With A Single End-To-End Model
https://arxiv.org/abs/1711.01694
Improving the Performance of Online Neural Transducer Modele
https://arxiv.org/abs/1712.01807
Monotonic Chunkwise Attention
https://arxiv.org/abs/1712.05382
Learning Hard Alignments with Variational Inference
https://arxiv.org/abs/1705.05524
No Need for a Lexicon? Evaluating the Value of the Pronunciation Lexica in End-to-End Models
https://arxiv.org/abs/1712.01864
An analysis of incorporating an external language model into a sequence-to-sequence model
https://arxiv.org/abs/1712.01996
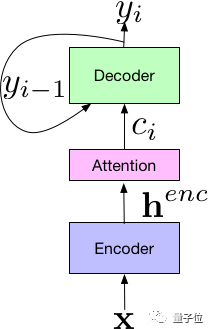
△Listen-Attend-Spell端到端语音识别模型的部件
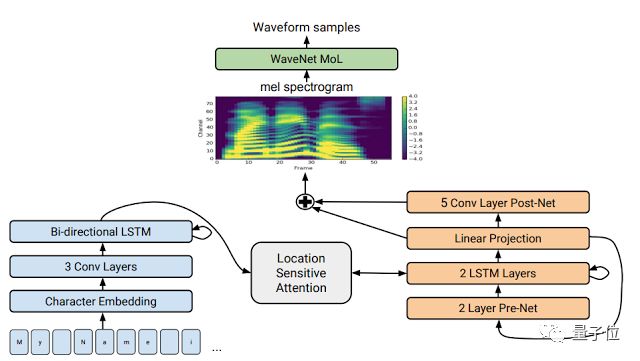
我们还和谷歌机器感知团队合作,开发了一种进行文字到语音生成的新方法:Tacotron2。这种新方法极大地改进了所生成语音的效果,模型达到的平均意见分(MOS)达到4.53,而你在有声书里听到的那些专业人类播音员,MOS也只有4.58,以前,计算机合成语音的最佳成绩是4.34。
Tacotron 2合成音频试听:
https://google.github.io/tacotron/publications/tacotron2/index.html
新的机器学习算法和方法
我们继续开发新颖的机器学习算法和方法,包括对capsules的研究(在执行视觉任务时,明确地寻找激活功能协议,以此作为一种评估不同噪声假设的方法)。
相关论文:
Dynamic Routing between Capsules
https://research.google.com/pubs/pub46351.html
sparsely-gated mixtures of experts (这能实现仍然具有计算效率的大型模型)。
在这个研究中,新的神经网络层只需要很小的计算能力提升,便能高效地提升模型的能力。
相关论文:
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
https://arxiv.org/abs/1701.06538
hypernetworks(使用一个模型的权重来生成另一个模型的权重)。
相关论文:
HYPERNETWORKS
https://openreview.net/pdf?id=rkpACe1lx
新型多模模型(使用相同模型执行音频、视觉和文本输入等多任务学习)。
相关论文:
One Model To Learn Them All
https://arxiv.org/abs/1706.05137
基于注意力的机制(代替卷积和循环模型)。
相关论文:
Attention is All You Need
https://arxiv.org/pdf/1706.03762.pdf
符号和非符号学习优化方法。
相关论文:
Neural Optimizer Search with Reinforcement Learning
http://proceedings.mlr.press/v70/bello17a/bello17a.pdf
Learned Optimizers that Scale and Generalize
https://arxiv.org/abs/1703.04813
一项通过离散变量反向传播的技术。
相关论文:
Categorical Reparameterization with Gumbel-Softmax
https://arxiv.org/abs/1611.01144
以及对强化学习算法的一些改进。
相关论文:
Bridging the Gap Between Value and Policy Based Reinforcement Learning
https://arxiv.org/pdf/1702.08892.pdf
计算机系统的机器学习
在计算机系统中用机器学习取代传统的启发式应用也是我们非常感兴趣的方向。我们已经展示了如何使用强化学习在把计算机图像映射到一组计算设备上的时候制定位置决策,效果比人类专家还好。
相关论文:
Bridging the Gap Between Value and Policy Based Reinforcement Learning
https://arxiv.org/pdf/1702.08892.pdf
我们与谷歌研究院的其他同事共同在“The Case for Learned Index Structures”中展示,神经网络不仅比传统的数据结构(B-树、哈希表和Bloom过滤器)更快,而且也小得多。我们认为,我们只是掌握了在核心计算系统中使用机器学习的皮毛。
相关论文:
The Case for Learned Index Structures
https://arxiv.org/abs/1712.01208
隐私和安全
机器学习及其与安全与隐私的交互仍是我们研究的重点。在ICLR 2017的一篇得奖论文中,我们展示了机器学习技术可以用于提供不同的隐私保障方式。
相关论文:
Semi-supervised Knowledge Transfer for Deep Learning from Private Training Data
https://arxiv.org/abs/1610.05755
我们还继续调查了对抗样例的特性,包括在现实世界中展示对抗样例,以及如何在训练过程中规模化使用对抗样例,使模型更适用于对抗样例。
相关论文:
Adversarial examples in the physical world
https://research.google.com/pubs/pub45818.html
Adversarial Machine Learning at Scale
https://arxiv.org/abs/1611.01236
理解机器学习系统
虽然通过机器学习技术得到了漂亮的结果,但更重要的是理解机器学习在什么时候能发挥作用,什么时候无效。
在另一篇ICLR 2017最佳论文中,我们展示了,当前机器学习理论框架无法解释深度学习方法取得的出色结果。
相关论文:
Understanding deep learning requires rethinking generalization
https://openreview.net/forum?id=Sy8gdB9xx¬eId=Sy8gdB9xx
我们还展示了,通过优化方法发现的最小值“平坦度”并不像最初想象中与良好的泛化方法密切相关。为了更好地理解深度框架中训练如何推进,我们发布了一系列分析随机矩阵的论文,因为这是大多数训练方法的出发点。
相关论文:
Nonlinear random matrix theory for deep learning
https://research.google.com/pubs/pub46342.html
理解深度学习的另一个重要途径是更好地衡量性能。我们在最近一项研究中比较了多种GAN方法,展示了良好的实验设计和统计严格性的重要性。许多GAN方法很热门,被用于增强生成模型,但实际上并没有带来性能优化。我们希望这项研究能给其他研究员带来范例,帮助他们展开健壮性更好的实验性研究。
我们正在开发能对机器学习系统进行更好表达的方法。去年3月,通过与OpenAI、DeepMind和YC Research等公司和机构合作,我们推出了新的开放科学在线杂志Distill,致力于支持人类对机器学习的理解。这份在线杂志的文章提供了清晰的机器学习概念,以及出色的交互式可视化工具。在推出第一年中,Distill发布了多篇有启发性的文章,旨在帮助人们了解机器学习的各种内部原理。我们期待2018年能带来更多内容。

△特征可视化
https://distill.pub/2017/feature-visualization/
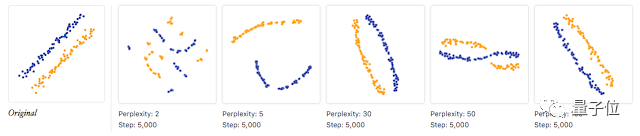
△如何有效地使用t-SNE
用于机器学习研究的开放数据集
MNIST、CIFAR-10、ImageNet、SVHN和WMD等开放数据集快速推动了机器学习的研究进展。我们团队和谷歌研究院一起,在过去一年里一直积极探索开放有趣的新数据集,用于开源机器学习领域的研究。我们提供了规模更大的有标签数据集,其中包括:
YouTube-8M:大于700万个YouTube视频,被标注为4716个不同类别
https://research.google.com/youtube8m/
YouTube-Bounding Boxes:来自21万个YouTube视频的500万个边界框
https://research.google.com/youtube-bb/
Speech Commands Dataset:数千名讲话者说出的简短命令
https://research.googleblog.com/2017/08/launching-speech-commands-dataset.html
AudioSet:200万个10秒钟YouTube短视频,用527个不同声音事件去标记
https://research.google.com/audioset/
Atomic Visual Actions(AVA):5.7万个视频片段中的21万个动作标签
https://research.google.com/ava/
Open Images:900万张获得知识共享许可的图片,被标记为6000个类别
https://github.com/openimages/dataset
Open Images with Bounding Boxes:600个类别的120万边界框

△YouTube-Bounding Boxes数据集示例
TensorFlow和开源软件
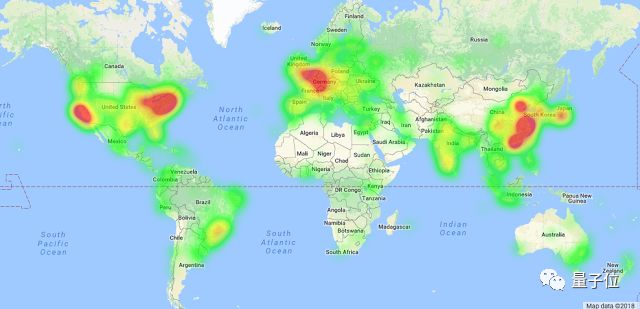
△TensorFlow全球用户分布
http://jrvis.com/red-dwarf/?user=tensorflow&repo=tensorflow
在团队历史上,我们开发了一些工具,帮助我们在谷歌的多种产品中开展机器学习研究,部署机器学习系统。
2015年11月,我们开源了第二代机器学习框架TensorFlow,希望让机器学习界从我们的投入中受益。2月份,我们发布了TensorFlow 1.0。11月份,我们又发布了1.4版本,加入了以下重要内容:用于交互式非典型编程的Eager Execution、针对TensorFlow程序优化的编译器XLA,以及用于移动和嵌入式设备的轻量级解决方案TensorFlow Lite。
预编译的TensorFlow二进制文件已在180多个国家被下载了1000多万次,GitHub上的源代码已有超过1200名贡献者。
2月份,我们举办了首届TensorFlow开发者峰会,超过450人来到山景城现场参会,全球有6500多人观看了在线直播,包括35个国家的超过85场本地观看活动。所有演讲记录了下来,主题包括新特性,使用TensorFlow的新技术,以及对低级TensorFlow抽象的详细描述。
TensorFlow开发者峰会2017演讲视频:
https://www.youtube.com/playlist?list=PLOU2XLYxmsIKGc_NBoIhTn2Qhraji53cv
我们将于2018年3月30日在旧金山湾区举行另一场TensorFlow开发者峰会。现在你可以注册,保存日期,追踪最新消息。
TensorFlow开发者峰会2017注册地址:
https://services.google.com/fb/forms/tfds-2018-save-the-date/
△一个用TensorFlow玩石头剪刀布的实验
我们很高兴看见,2017年TensorFlow得到了广泛应用,包括黄瓜分拣的自动化,在航拍照片中寻找海牛,对土豆进行分拣确保儿童食品安全,协助翻译新西兰鸟类保护区的鸟叫声,以及对坦桑尼亚最受欢迎根茎作物的病害进行识别。
11月,TensorFlow作为开源项目庆祝了两周岁生日。我们很高兴看到TensorFlow开发者和用户社区的兴起和繁荣。TensorFlow目前是GitHub上排名第一的机器学习平台,也是GitHub上的最火的五大代码库之一,被许多大大小小的企业和组织使用。
此外,GitHub上已有2.45万个与TensorFlow有关的不同代码库。目前的许多研究论文关于开源代码的TensorFlow实现,并提供了研究成果,帮助整个社区更容易地理解确切的研究方法,模仿或拓展相关工作。
Google Research其他团队的相关开源工作也令TensorFlow受益,其中包括TF-GAN。这是个轻量级库,用于TensorFlow、TensorFlow Lattice(一组用于晶格模型的估计工具),以及TensorFlow对象检测API中的生成对抗模型。随着模型数量的不断增长,TensorFlow模型库也在继续壮大。
TF-GAN
https://research.googleblog.com/2017/12/tfgan-lightweight-library-for.html
除TensorFlow之外,我们还发布了deeplearn.js,提供了一种在浏览器中配置深度学习API的开源、硬件加速的方法(无需下载或安装任何东西)。deeplearn.js的主页提供了许多很好的范例,包括Teachable Machine(一种计算机视觉模型,可以用自己的摄像头去训练)和Performance RNN(实现了基于实时神经网络的钢琴作曲和表演)。2018年,我们将在此基础上进一步推进,协助将TensorFlow模型直接部署至deeplearn.js环境。
相关链接:
Teachable Machine
https://teachablemachine.withgoogle.com/
Performance RNN
https://deeplearnjs.org/demos/performance_rnn
TPU

大约5年前,我们意识到,深度学习将极大地改变我们对硬件的需求。深度学习计算将带来计算密集型任务,同时具备两个特点:
一方面,它们主要由繁重的线性代数运算(矩阵乘法、向量运算等)组成;另一方面,它们对精度降低宽容度很高。
我们意识到,可以基于这两大特点来构建专用硬件,从而更高效地运行神经网络计算。因此,我们向谷歌的平台团队提供了设计输入,而他们设计并开发了第一代的“张量处理单元(TPU)”。这是一种单芯片ASIC,用于加速深度学习推理(与训练不同,推理用于已经过训练的神经网络)。
第一代TPU在数据中心的部署已有3年时间,谷歌搜索、谷歌翻译、谷歌照片,以及AlphaGo中的深度学习模型就使用了这种芯片,同时也给许多其他研究项目和产品提供了计算能力。去年6月,我们在ISCA 2017上发表了一篇论文,表明第一代TPU要比同时代GPU或CPU快15到30倍,而性能功耗比则提升了30倍到80倍。

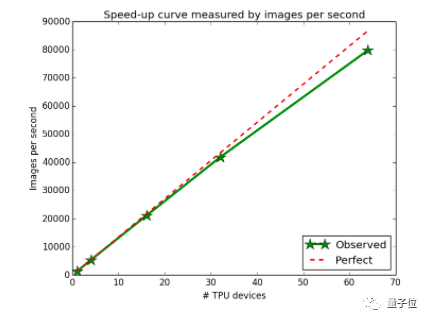
△用ImageNet训练ResNet-50的实验表明,随着TPU数量的增长,神经网络训练加速
推理很重要,但训练的加速是个更重要的问题,同时也更困难。如果研究人员可以更快地尝试新想法,那么我们就可以取得更多突破。
我们的第二代TPU于去年5月在谷歌I/O大会上发布,提供了完整的系统(包括订制的ASIC芯片、电路板和连接方式),可以同时加速训练和推理。我们展示了单个设备的配置,以及包含多个机架的深度学习超级计算机配置,即TPU舱。我们宣布将通过谷歌云计算平台提供第二代设备,即云TPU。我们还启动了TensorFlow研究云(TFRC)项目,向愿意将工作成果分享给全世界的顶级机器学习研究员提供包含1000个云TPU的计算集群。
12月,我们又展示了一项成果:用TPU舱去训练ResNet-50 ImageNet模型,并在22分钟内取得了高水平的精确度。而传统工作站达到这样的效果需要几天甚至更长时间。我们认为,缩短研究周期将大大提高谷歌机器学习团队,以及所有使用云TPU的组织的效率。
如果你对云TPU、TPU舱和TensorFlow研究云感兴趣,那么可以在 g.co/tpusignup 注册,了解更多信息。我们很高兴,2018年能让更多工程师和研究员用上TPU。
原文:
https://research.googleblog.com/2018/01/the-google-brain-team-looking-back-on.html
这是Jeff Dean总结Google Brain 2017成就的上篇,在下篇中,Jeff Dean谈到了他们对机器学习应用于医疗、机器人、各种科学研究、创造等领域的研究,也谈到Google Brain在公平性和包容性方面所做的工作。
下篇

在这第二篇总结中,Jeff Dean详细论述了谷歌大脑过去一年的AI应用研究,例如如何将机器学习等技术应用于医疗、机器人、创意、公平等等多个领域。
这在某种程度上,也代表了2017人工智能具体应用的最高水平研究。
在这篇文章中,我们将深入到谷歌大脑在多个特定领域所做的研究。
医疗
我们认为,机器学习技术在医疗行业的应用潜力巨大。我们正在解决各种各样的问题,包括协助病理学家检测癌症,理解各种对话来为医生和病人提供帮助,使用机器学习解决基因组学中的各种问题,其中包括一个名叫DeepVariant的开源工具,用深度神经网络来从DNA测序数据中快速精确识别碱基变异位点。
相关论文:
Detecting Cancer Metastases on Gigapixel Pathology Images
https://drive.google.com/file/d/0B1T58bZ5vYa-QlR0QlJTa2dPWVk/view
理解对话论文:
Speech recognition for medical conversations
https://arxiv.org/abs/1711.07274
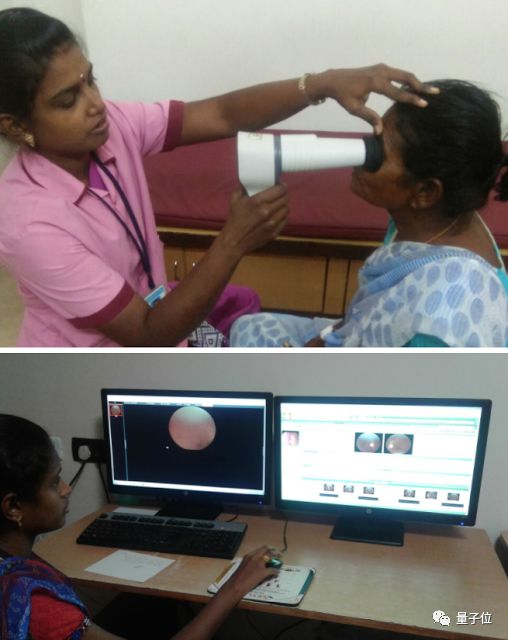
我们还致力于尽早发现糖尿病视网膜病变(DR)和黄斑水肿,并于2016年12月在《美国医学协会杂志》(JAMA)上发表论文。
相关论文:
Development and Validation of a Deep Learning Algorithm for Detection of Diabetic Retinopathy in Retinal Fundus Photographs
https://jamanetwork.com/journals/jama/article-abstract/2588763
2017年,我们将这个项目从研究阶段过渡到实际的临床影响阶段。我们与Verily(Alphabet旗下的一家生命科学公司)合作,通过严格的流程来引导这项工作,我们还一起将这项技术整合到尼康的Optos系列眼科相机中。
此外,我们在印度努力部署这套系统,因为印度的眼科医生缺口多达12.7万人,因此,几乎一半的患者确诊时间过晚,并因为这种疾病而导致视力下降。作为试点的一部分,我们启动了这个系统,帮助Aravind Eye Hospitals眼科医院的学生更好地诊断糖尿病眼病。
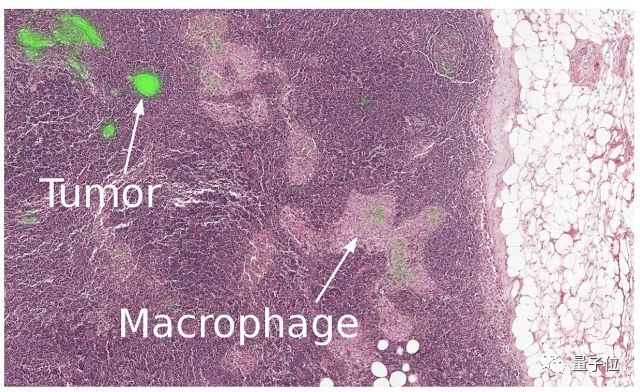
我们还与合作伙伴共同了解影响糖尿病眼睛护理的人类因素,从患者和医疗服务提供者的人种学研究,到研究眼科医生如何与人工智能系统之间的互动方式。
我们也与领先的医疗组织和医疗中心的研究人员(包括斯坦福大学、加州大学旧金山分校和芝加哥大学),共同演示机器学习利用匿名病历来预测医疗结果所能达到的具体效果(例如,考虑到病人的现状,我们相信可以用针对其他数百万病人的病程进行的研究来预测这个病人的未来,以此帮助医疗专业人士做出更好的决策)。我们对这项工作感到非常兴奋,我们期待着在2018年告诉你更多与之有关的事情。
机器人
我们在机器人领域的长期目标是设计各种学习算法,让机器人在混乱的现实环境中运行,并通过学习快速获得新的技能和能力。而不是让它们身处精心控制的环境中,处理当今机器人所从事的那些为数不多的手工编程任务。
我们研究的一个重点是开发物理机器人的技术,利用他们自己的经验和其他机器人的经验来建立新的技能和能力,分享经验,共同学习。我们还在探索如何将基于计算机的机器人任务模拟与物理机器人的经验结合起来,从而更快地学习新任务。
相关博客:
https://research.googleblog.com/2017/10/closing-simulation-to-reality-gap-for.html
虽然模拟器的物理效果并不完全与现实世界相匹配,但我们观察到,对于机器人来说,模拟的经验加上少量的真实世界经验,比大量的实际经验更能带来更好的结果。
除了真实世界的机器人经验和模拟的机器人环境,我们还开发了机器人学习算法,可以学习通过观察人类的演示进行学习。我们相信,这种模仿学习模式是一种非常有前途的方法,可以让机器人快速掌握新的能力,不需要明确编程或明确规定一个活动的具体目标。
论文及项目:
Unsupervised Perceptual Rewards for Imitation Learning
https://sermanet.github.io/rewards/
Time-Contrastive Networks: Self-Supervised Learning from Multi-View Observation
https://sermanet.github.io/tcn/
End-to-End Learning of Semantic Grasping
https://arxiv.org/abs/1707.01932
例如,在下面的视频中,机器人会从不同的角度观察人类执行任务的过程,然后努力模仿他们的行为,从而在15分钟的真实世界体验中学会用杯子倒水。就像教自己3岁的孩子一样,我们可能会给予它鼓励,告诉它只洒出来一点水。
我们还共同组织并主持了11月召开的第一届Conference on Robot Learning (CoRL),汇集了在机器学习和机器人技术的交叉领域工作的研究人员。这次会议的总结包含了更多的信息,我们很期待明年在苏黎世召开的会议。
会议总结:
https://research.googleblog.com/2017/12/a-summary-of-first-conference-on-robot.html
基础科学
我们也很看好机器学习技术解决重要科学问题的长期潜力。去年,我们利用神经网络预测了量子化学中的分子性质。
相关论文:
Machine learning prediction errors better than DFT accuracy
https://arxiv.org/abs/1702.05532
Neural Message Passing for Quantum Chemistry
https://arxiv.org/abs/1704.01212
通过分析天文数据发现了新的系外行星。
相关博客:
https://www.blog.google/topics/machine-learning/hunting-planets-machine-learning/
对地震的余震进行预测,并利用深度学习来指导自动证明系统。
相关论文:
Deep Network Guided Proof Search
https://arxiv.org/abs/1701.06972
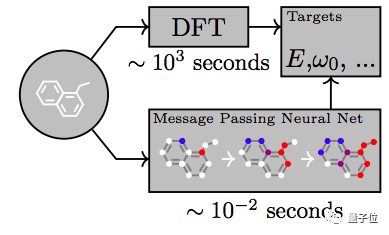
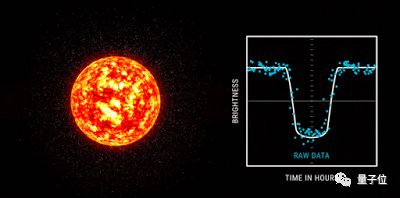
创意
我们也很感兴趣,如何利用机器学习技术去协助创意活动。2017年,我们开发了一个人工智能钢琴二重奏工具。
弹琴地址:
https://experiments.withgoogle.com/ai/ai-duet/view/
帮助YouTube音乐人Andrew Huang制作了新的音乐。
对这个感兴趣,可以前往YouTube观看:
https://youtu.be/AaALLWQmCdI
并展示了如何教机器画画。
相关论文:
A Neural Representation of Sketch Drawings
https://arxiv.org/abs/1704.03477
画画地址:
autodraw.com

我们还演示了,如何控制运行在浏览器中的深度生成模型,制作新的音乐。这项工作赢得了NIPS 2017的“最佳演示奖”,这也是谷歌大脑团队Magenta项目的成员连续第二年赢得这个奖项。
Demo地址:
https://deeplearnjs.org/demos/performance_rnn/index.html
在NIPS 2016上,来自Magenta项目的互动音乐即兴创作也赢得了“最佳演示奖”。
在以下YouTube视频中,你可以看到这个演示的一部分,即MusicVAE变分自动编码器模型将一段旋律平滑地转换为另一段。
MusicVAE地址:
https://colab.research.google.com/notebook#fileId=/v2/external/notebooks/magenta/music_vae/music_vae.ipynb
People + AI研究项目(PAIR)
机器学习的进步为人类与计算机的交互带来了全新的可能。与此同时,同样重要的是让全社会从我们开发的技术中受益。我们将这方面的机遇和挑战视为高优先级工作,并与谷歌内部的许多团队合作,成立了PAIR项目(https://ai.google/pair)。
PAIR的目标是研究和设计人类与人工智能系统互动最高效的方式。我们发起了公共研讨会,将多个领域,包括计算机科学、设计,甚至艺术等领域的学术专家和实践者聚集在一起。PAIR关注多方面课题,其中一些我们已有所提及:尝试解释机器学习系统,帮助研究者理解机器学习,以及通过deeplearn.js扩大开发者社区。关于我们以人为中心的机器学习工程方法,另一个案例是Facets的推出。这款工具实现训练数据集的可视化,帮助人们理解训练数据集。
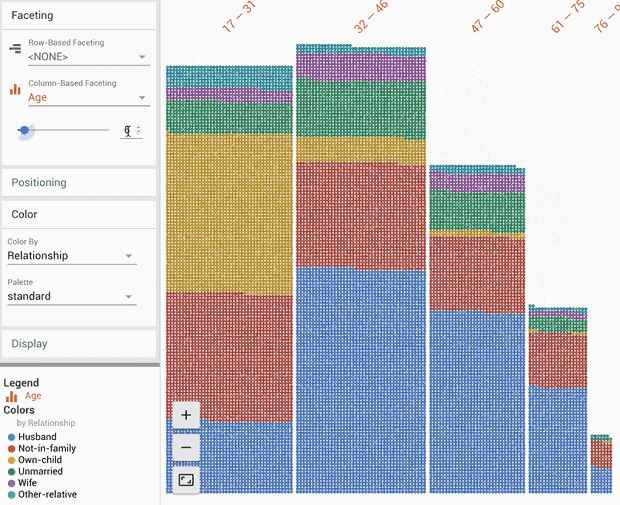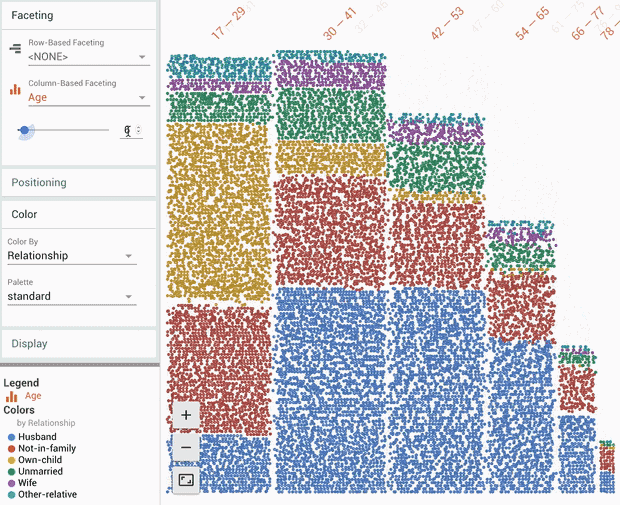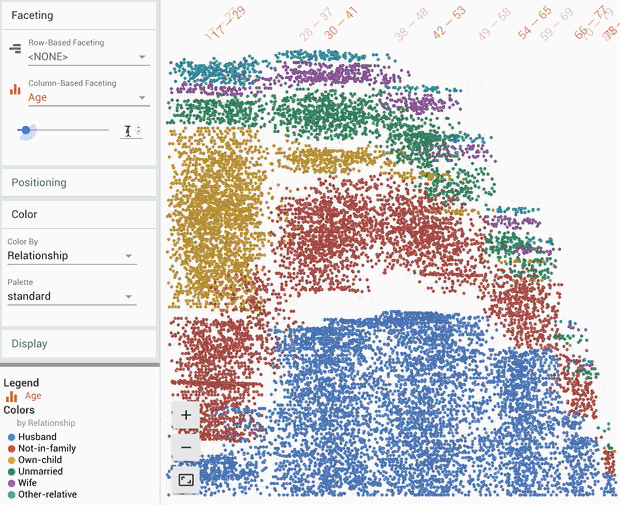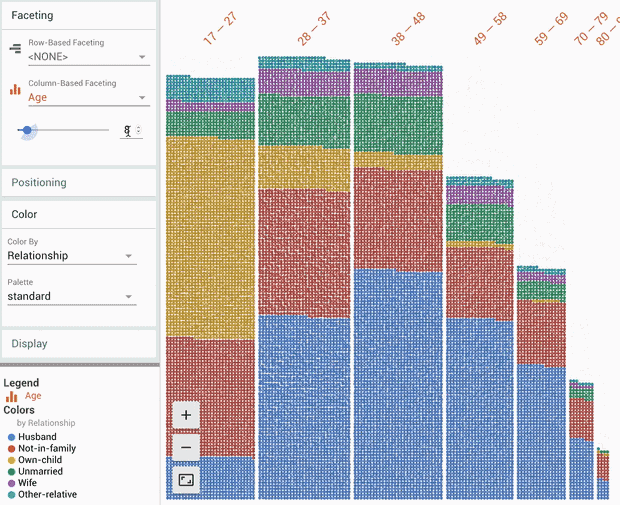
机器学习的公平性和包容性
随着机器学习在技术领域发挥越来越大的作用,对包容性和公平性的考量也变得更重要。谷歌大脑团队和PAIR正努力推动这些领域的进展。
我们发表的论文涉及,如何通过因果推理来避免机器学习系统的偏见,在开放数据集中地理多样性的重要性,以及对开放数据集进行分析,理解多元化和文化差异。我们也一直与跨行业项目Partnership on AI密切合作,确保公平性和包容性成为所有机器学习实践者的目标。
相关论文:
Avoiding Discrimination through Causal Reasoning
https://arxiv.org/pdf/1706.02744.pdf
No Classification without Representation: Assessing Geodiversity Issues in Open Data Sets for the Developing World
https://arxiv.org/abs/1711.08536

我们的文化
我们团队文化的一个重要方面在于,赋能研究员和工程师,帮助他们解决他们认为最重要的基本研究问题。9月份,我们公布了开展研究的一般方法。
相关博客:
https://research.googleblog.com/2017/09/the-google-brain-teams-approach-to.html
在我们的研究工作中,教育和指导年轻研究员贯穿始终。去年,我们团队吸纳了100多名实习生,2017年我们研究论文的约25%共同作者是实习生。
2016年,我们启动了“谷歌大脑入驻”项目,给有志于学习机器学习研究的人们提供指导。在项目启动第一年(2016年6月到2017年5月),27名入驻者加入我们团队。我们在项目进行到一半时,以及结束后公布了进展,列出了入驻者的研究成果。项目第一年的许多入驻者都是全职研究员和研究工程师,他们大部分人没有参加过伯克利、卡耐基梅隆、斯坦福、纽约大学和多伦多大学等顶级机器学习研究机构的博士研究。
2017年7月,我们迎来了第二批入驻者,他们将与我们一同工作至2018年7月。他们已经完成了一些令人兴奋的研究,成果在许多研究场合发表。
详情可见:
https://research.google.com/pubs/AIResidency.html
现在,我们正在扩大项目范围,引入谷歌内部的许多其他研究团队,并将项目更名为“Google AI Residency program”项目。(今年项目的申请截止时间已过,可以通过链接g.co/airesidency/apply了解明年的项目情况)。
2017年,我们所做的工作远远超出我们在这两篇博客中介绍的内容。我们致力于在顶级研究场合发表我们的成果。去年,我们团队发表了140篇论文,包括在ICLR、ICML和NIPS上发表的超过60篇论文。如果想要进一步了解我们的工作,你可以仔细阅读我们的研究论文。
论文详情:
https://research.google.com/pubs/BrainTeam.html
你也可以在这段视频中了解我们的团队成员。
视频地址:
https://youtu.be/rsN690cfWsM
或是读一读我们在第二次“Ask Me Anything”活动上的回答。(你也可以看看我们2016年的同一活动。)
谷歌大脑团队正在开枝散叶,在北美和欧洲都吸纳了成员。如果你觉得我们所做的工作听起来很有趣,想要加入我们,那么可以看看我们正在招聘的空缺职位,申请实习,参与人工智能入驻项目,拜访我们的研究员,或是通过g.co/brain最下方的链接去跟踪全职的研究和工程开发岗位。
你可以通过谷歌研究博客,或Twitter帐号@GoogleResearch关注我们2018年的工作,你也可以关注我的个人帐号@JeffDean。

Jeff Dean还在Twitter上等待大家的反馈呢。

📚往期文章推荐

🔗征稿延期通知|第二届IEEE/IFAC区块链与知识自动化国际会议
🔗黄铁军 | 多媒体技术研究:面向智能视频监控的视觉感知与处理
🔗Judea Pearl | 机器学习的理论局限性与因果推理的七大特性
🔗Berkeley吴翼&FAIR田渊栋等人提出强化学习环境House3D

点击“阅读原文”,快速进入峰会报名通道!



