【资源】T2T:利用StackGAN和ProGAN从文本生成人脸
选自GitHub
来源:机器之心
在现实生活中,我们通常见过一个人后只会留下非常抽象的印象,也许只能用少量话语描述特定特征。而计算机视觉是不是也能仅使用少量的描述性语句就生成对应的人脸图像?本 GitHub 项目使用了最新发布的 Face2Text 数据集,并通过结合 StackGAN 与 ProGAN 从文本生成人脸图像。
项目地址:https://github.com/akanimax/T2F
本项目利用深度学习由文本生成人脸图像,除了结合 StackGAN 和 ProGAN,作者还参考了从文本到图像的研究,并修改为从文本合成人脸。
StackGAN++由树状结构的多个生成器和鉴别器组成;从树的不同分支生成对应于同一场景的多尺度图像。ProGAN 的关键思想是逐步增加生成器和鉴别器的表征能力:从低分辨率开始,我们添加了新的层,随着训练的进行,这些层的细节越来越精细。
论文:StackGAN++: Realistic Image Synthesis with Stacked Generative Adversarial Networks
地址:https://arxiv.org/abs/1710.10916
论文:Progressive Growing of GANs for Improved Quality, Stability, and Variation
地址:https://arxiv.org/abs/1710.10196
数据
Face2Text v1.0 数据集包含来自 LFW(Labelled Faces in the Wild)数据集 400 个随机选择图像的自然语言描述。这些数据已经经过清洗,剔除了不适合、不相关的人像描述。有些文字不仅描述了面部特征,还提供了一些来自图片的隐含信息。例如,其中一张人像的描述这样写道:「图中人物可能为一名罪犯」。由于以上因素及数据集相对较小,我决定使用该数据集来证明架构的概念。最终,我们可以扩展模型,以灌输更大、更多样的数据集。
数据存储地址:data/LFW/Face2Text/face2text_v0.1
样例:

架构:
视频 Demo:
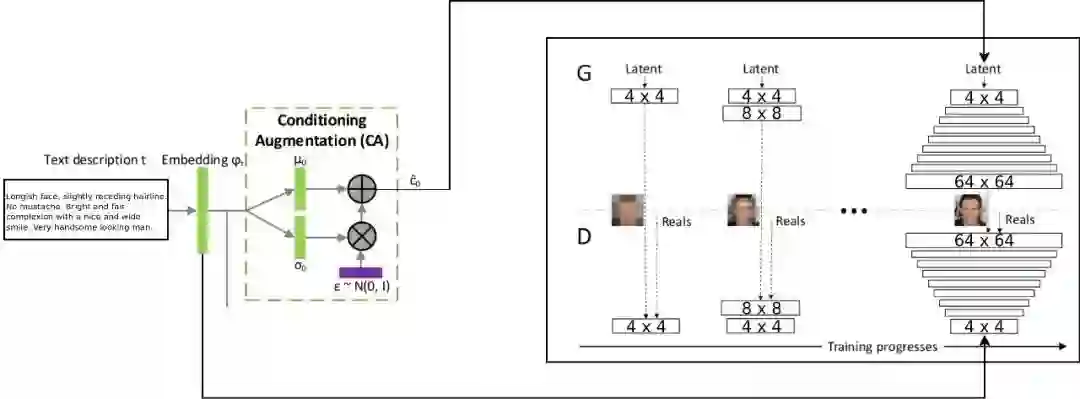
使用 LSTM 网络将文本描述编码为一个汇总向量。使图中所示的汇总向量,即嵌入(psy_t),通过条件增强块(单一线性层)以获得 GAN 本征向量的文本部分(使用变分自动编码器,如重新参数化技术)作为输入。本征向量的第二部分为随机高斯噪声。由此产生的本征向量被馈送到 GAN 的发生器部分,而嵌入被馈送到鉴别器的最后一层用于条件分布匹配。GAN 的训练进展与 ProGAN 论文所述完全一致;即在增加的空间分辨率上逐层进行。使用淡入技术引入新层以避免破坏先前的学习。
运行代码
代码存在 implementation/子目录中。使用 PyTorch 框架实现。因此,若要运行此代码,请先安装 PyTorch version 0.4.0,然后再继续。
代码组织:
configs:包含用于训练网络的配置文件(你可以使用任意一个,也可以自己创建)。
data_processing:包含数据处理和加载模块的包
networks:包含网络实现的包
processed_annotations:目录存储运行 process_text_annotations.py 脚本的输出
process_text_annotations.py:处理标题并将输出存储在 processed _ annotations /目录中。(无需运行此脚本;pickle 文件包含在报告中。)
train_network.py:运行训练网络的脚本。
示例配置:
# All paths to different required data objects
images_dir: "../data/LFW/lfw"
processed_text_file: "processed_annotations/processed_text.pkl"
log_dir: "training_runs/11/losses/"
sample_dir: "training_runs/11/generated_samples/"
save_dir: "training_runs/11/saved_models/"
# Hyperparameters for the Model
captions_length: 100
img_dims:
- 64
- 64
# LSTM hyperparameters
embedding_size: 128
hidden_size: 256
num_layers: 3 # number of LSTM cells in the encoder network
# Conditioning Augmentation hyperparameters
ca_out_size: 178
# Pro GAN hyperparameters
depth: 5
latent_size: 256
learning_rate: 0.001
beta_1: 0
beta_2: 0
eps: 0.00000001
drift: 0.001
n_critic: 1
# Training hyperparameters:
epochs:
- 160
- 80
- 40
- 20
- 10
# % of epochs for fading in the new layer
fade_in_percentage:
- 85
- 85
- 85
- 85
- 85
batch_sizes:
- 16
- 16
- 16
- 16
- 16
num_workers: 3
feedback_factor: 7 # number of logs generated per epoch
checkpoint_factor: 2 # save the models after these many epochs
use_matching_aware_discriminator: True # use the matching aware discriminator
使用 requirements.txt 安装项目的所有依赖项。
$ workon [your virtual environment]
$ pip install -r requirements.txt
样本运行:
$ mkdir training_runs
$ mkdir training_runs/generated_samples training_runs/losses training_runs/saved_models
$ train_network.py --config=configs/11.comf☞【学界】OpenPV:中科院研究人员建立开源的平行视觉研究平台
☞【学界】ParallelEye:面向交通视觉研究构建的大规模虚拟图像集
☞【CFP】Virtual Images for Visual Artificial Intelligence
☞【最详尽的GAN介绍】王飞跃等:生成式对抗网络 GAN 的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王飞跃教授:生成式对抗网络GAN的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王坤峰副研究员:GAN与平行视觉
☞【重磅】平行将成为一种常态:从SimGAN获得CVPR 2017最佳论文奖说起
☞【干货】DeepMind 提出 GQN,神经网络也有空间想象力
☞【前沿】谷歌提出Sim2Real:让机器人像人类一样观察世界
☞【深度】何恺明CVPR演讲:深入理解ResNet和视觉识别的表示学习(41 PPT)
☞【深度】小数据,大任务!详解英特尔中国研究院的视频物体分割解决方案




