点击上方“CVer”,选择加"星标"置顶
重磅干货,第一时间送达![]()
本文转载自:机器之心 | 论文已上传,文末附下载方式
作者:Quoc V. Le等人 | 参与:魔王、杜伟
预训练是当前计算机视觉领域的主要范式,但何恺明等人先前的研究发现,预训练对目标检测和分割任务的影响有限。因而,重新探究预训练和自训练的效果成为一个非常重要的课题。在这篇谷歌团队的论文中,Quoc V. Le 等研究者发现,当具有大量的标注数据时,自训练的运行效果要优于预训练,并在 COCO 检测和 PASCAL 分割任务上实现了 SOTA 结果。
众所周知,预训练是计算机视觉领域的主导范式,研究人员也热衷于预训练。
早在 2018 年,何恺明等人在论文《Rethinking ImageNet Pre-training》中重新思考了 ImageNet 预训练模型。他们发现这种利用预训练模型抽取「通用」特征,并借此解决大多数视觉任务的方法是值得质疑的。因为即使在比 ImageNet 还大 3000 倍的数据集上进行预训练,它们对目标检测任务的性能提升仍然不是很大。
近日,谷歌大脑研究团队首席科学家 Quoc V. Le 公布了其团队的一项新研究,主题是「重新思考预训练和自训练」。在这篇论文中,谷歌研究者展示了
当标注数据很多时,预训练不起作用。相比之下,当标注数据很多时,自训练可以运行良好,并在 PASCAL 分割和 COCO 检测数据集上实现 SOTA 效果
。
![]()
关于自训练,谷歌团队先前已经展开相关研究,分别是在 ImageNet 数据集上实现 SOTA 的 Noisy Student Training 和在 LibriSpeech 数据集上实现 SOTA 的 Noisy Student Training for Speech。
而这项新研究则是对先前研究成果的延续,该研究发现:在大型数据集上取得优秀结果需要自训练(w/Noisy Student)。
![]()
论文链接:https://arxiv.org/pdf/2006.06882.pdf
预训练是计算机视觉领域中的主要范式。例如,监督式 ImageNet 预训练常用于初始化目标检测和分割模型的主干网络。但是,何恺明等人的研究展示了一个令人惊讶的结果,即 ImageNet 预训练对 COCO 目标检测任务的影响有限。
于是,谷歌大脑的研究人员将自训练作为另一种在相同设置上利用额外数据的方法进行研究,并将其与 ImageNet 预训练进行对比。该研究展示了自训练的通用性和灵活性,并发现以下三点洞见:
更强的数据增强和更多标注数据,却使得预训练的价值降低;
与预训练不同,在提供更强大的数据增强时,自训练通常起到积极作用,不论是在低数据机制还是高数据机制下;
在预训练有用的情况下,自训练比预训练更有用。
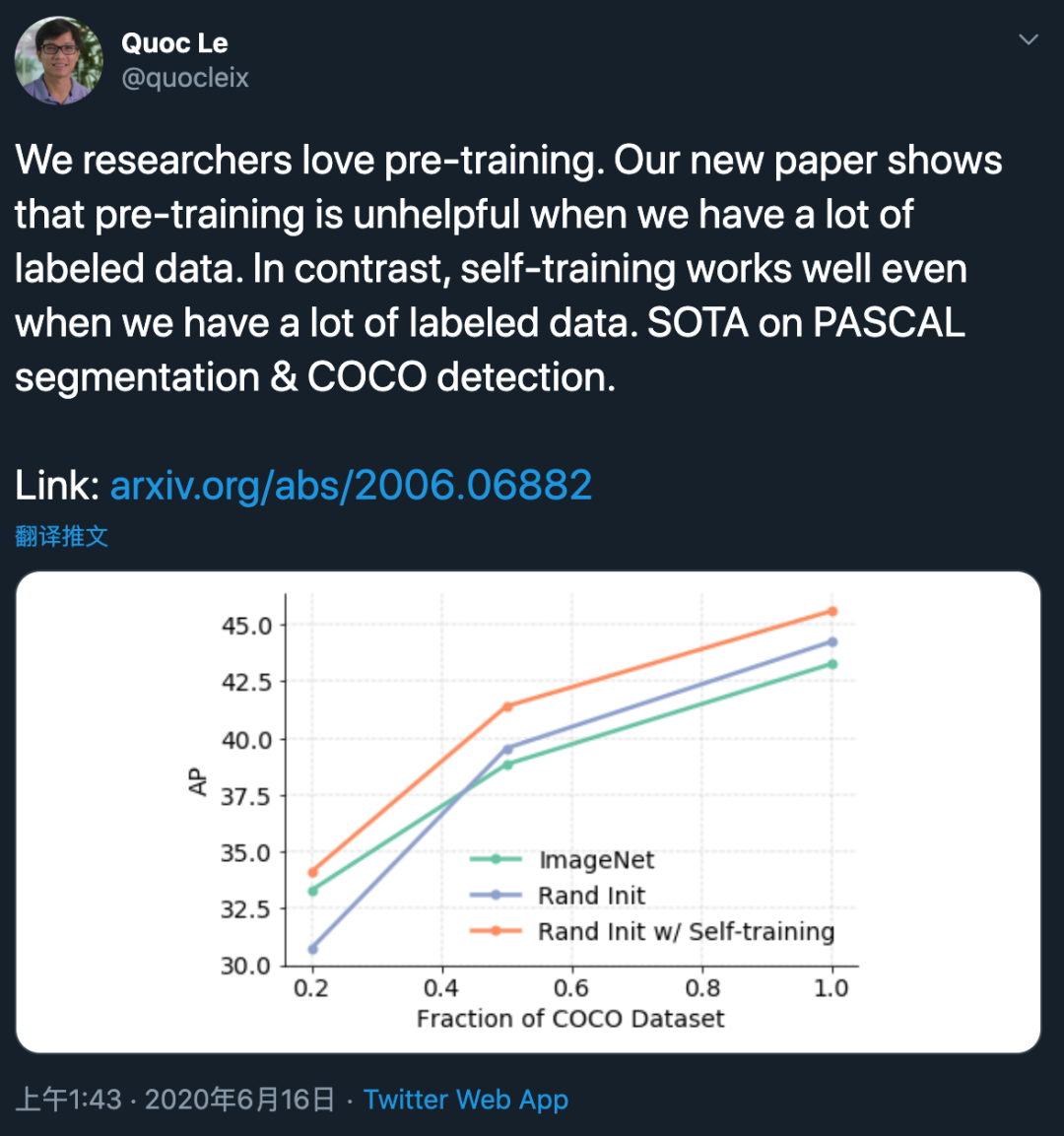
例如,在 COCO 目标检测数据集上,研究人员使用 1/5 的标注数据时,预训练起到积极影响,但当使用全部标注数据时,准确率反而下降。而自训练在所有数据集规模下都能带来 1.3 至 3.4AP 的性能提升,即自训练在预训练不起作用的场景下依然有效。在 PASCAL 分割数据集上(该数据集比 COCO 小很多),尽管预训练起到很大的作用,但自训练带来的性能提升更大。
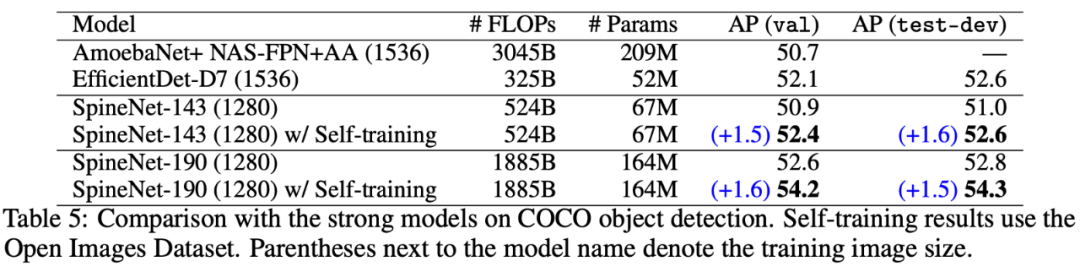
在 COCO 目标检测任务中,自训练实现了 54.3AP,
相比最强大的预训练模型 SpineNet 提升了 1.5AP
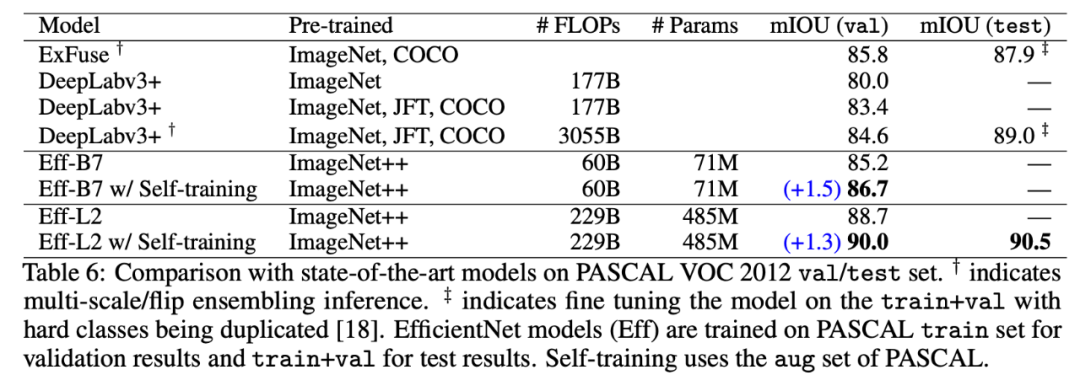
;在 PASCAL 分割任务中,自训练实现了 90.5 mIOU,
相比之前的最优结果(来自 DeepLabv3+)提升了 1.5%
。
该研究使用四种适用于目标检测和分割任务的不同数据增强策略,分别是:FlipCrop、AutoAugment、具备更高 scale jittering 的 AutoAugment 以及具备更高 scale jittering 的 RandAugment。(下文中,这四种数据增强策略分别写作 Augment-S1、Augment-S2、Augment-S3 和 Augment-S4。)
为了评估预训练的效果,研究者对不同质量的 ImageNet 预训练模型检查点进行了研究。此外,为了控制模型容量,所有检查点均使用同样的模型架构,不过由于训练方法不同,它们在 ImageNet 上的准确率有所不同。
该研究使用 EfficientNet-B7 架构 [51] 作为预训练的强基线方法。EfficientNet-B7 架构有两个可用的检查点:1)使用 AutoAugment 训练的 EfficientNet-B7 检查点,它在 ImageNet 上的 top-1 准确率为 84.5%;2)使用 Noisy Student 方法训练的 EfficientNet-B7 检查点,它利用额外 300M 无标注图像,实现了 86.9% 的 top-1 准确率。该研究将这两个检查点分别写为 ImageNet 和 ImageNet++。基于随机初始化进行训练的模型即 Rand Init。
下表 1 展示了该研究所用数据增强和预训练检查点的定义:
![]()
该研究使用的自训练实现基于 Noisy Student training [10],共有三个步骤:
1)基于标注数据(如 COCO 数据集)训练教师模型;2)教师模型基于无标注数据(如 ImageNet 数据集)生成伪标签;3)训练学生模型,对人类标签和伪标签上的损失进行联合优化
。
学生模型中的主要噪声来源是数据增强和相关模型之前使用过的其他噪声扰动方法。
谷歌研究人员将前述何恺明的研究进行了扩展,发现了以下几点:
1. 在使用强大的数据增强时,预训练会损伤模型性能。
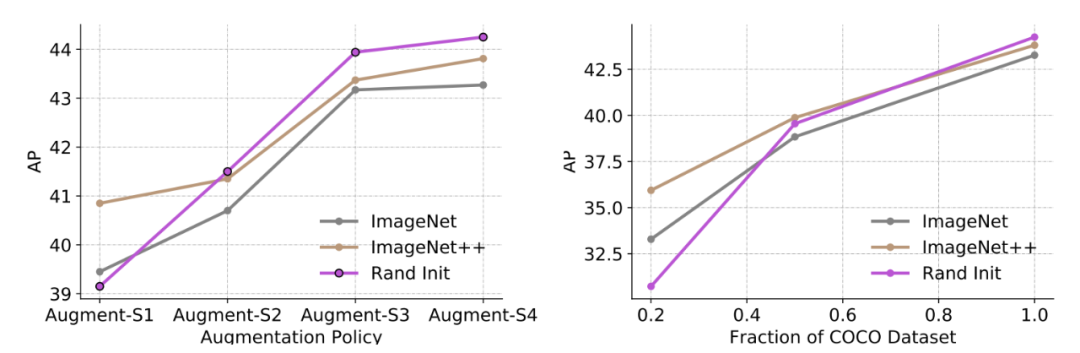
研究者改变数据增强的强度,并分析对预训练的影响。如下图 1 左图所示,在使用标准数据增强(Augment-S1)时,预训练起到积极作用。但随着数据增强强度的增加,预训练的价值逐渐减退。
![]()
研究者分析了标注数据集规模变化时,预训练的影响。如上图 1 右图所示,在低数据机制(20%)下预训练产生积极影响,但在高数据机制下,预训练的作用是中性甚至有害的。
这一结果与何恺明的观察基本一致。不过该研究还有一项新发现:检查点质量与低数据机制下的最终性能有关(ImageNet++ 在 20% COCO 数据集上的性能最优)。
研究者对自训练展开分析,并将其与上述结果进行了对比。出于一致性的考虑,研究人员继续使用 COCO 目标检测任务,并以 ImageNet 数据集作为自训练数据源。与预训练不同,自训练将 ImageNet 数据集仅作为无标注数据。
1. 自训练在高数据 / 强数据增强的机制下能够起到积极作用,而预训练则不能。
研究者首先分析了数据增强强度对目标检测器性能的影响。下表 2 展示了使用四种数据增强策略时自训练的性能变化,并将这些结果与监督学习(Rand Init)和预训练(ImageNet Init)进行了比较。
![]()
表 2:使用四种数据增强方法时自训练的性能变化,以及与监督学习和预训练的比较。
2. 自训练适用于不同规模的数据集,是对预训练的补充。
研究者接下来分析了不同 COCO 标注数据集规模对自训练性能的影响。
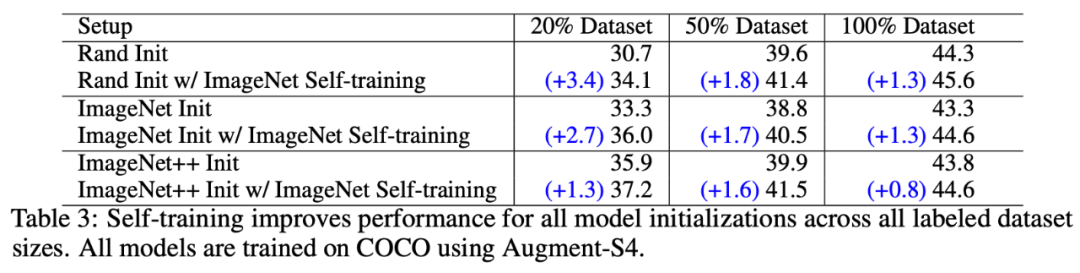
如下表 3 所示,自训练在小数据集和大数据集上都对目标检测器起到积极作用。最重要的是,在 100% 标注数据集规模的高数据机制下,自训练显著提升了所有模型的性能,而预训练则损害了模型性能。
![]()
表 3:自训练可以在所有规模的标注数据集上提升模型性能,而预训练无法实现该效果。
自训练在高数据/强数据增强机制下起到积极作用,自监督预训练则不能
研究者还研究了另一种流行的预训练方法:自监督学习。
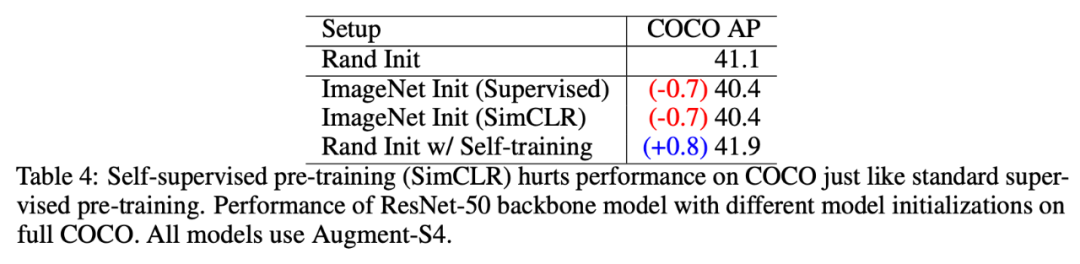
如下表 4 所示,自监督预训练检查点在 COCO 数据集上对性能的损害与监督预训练方法相当。与使用随机初始模型(randomly initialized model)相比,自监督和监督预训练模型的性能均下降了 0.7AP。相较于它们,自训练模型将性能提升了 0.8AP。
此外,尽管自监督学习和自训练都忽略了标签,但在使用无标注 ImageNet 数据增强 COCO 数据集方面,自训练似乎更有效。
![]()
表 4:在 COCO 数据集上,自监督 / 监督预训练与自训练对模型性能的影响。
研究者结合了数据增强、自训练和预训练的相互作用来提升 SOTA 结果,具体如下表 5 和下表 6 所示:
![]()
![]()
表 6:在 PASCAL VOC 语义分割数据集上的结果。
计算机视觉的目标之一是开发能够解决多项任务的通用特征表示。而该研究实验通过预训练和自训练的性能差异,展示了在分类和自监督任务中学习通用表示的局限性。
研究人员对预训练性能较弱的直观见解是,预训练无法感知要处理的特定任务,因而无法进行适应。而在任务发生变化时,这样的适应是必要的。例如,适合 ImageNet 的特征可能缺失对 COCO 数据集有用的位置信息。
谷歌研究者得出的结论是:将自训练目标和监督学习进行联合训练,更有利于适应特定任务
。这或许能够使自训练产生更普遍的积极影响。
自训练机制的优势在于,它能联合训练监督和自训练目标,从而解决二者之间的不匹配。那么,联合训练 ImageNet 和 COCO 是否也能解决这种不匹配呢?
下表 7 展示了将 ImageNet 分类和 COCO 目标检测联合训练的结果:
![]()
表 7:预训练、自训练和联合训练在 COCO 数据集上的对比结果。
灵活性:自训练可以很好地应对实验中的每一种设置,如低数据、高数据、弱数据增强和强数据增强。同时自训练对不同的架构(ResNet、EfficientNet、SpineNet、FPN、NAS-FPN)、数据源(ImageNet、OID、PASCAL、COCO)和任务(目标检测、分割)都有效;
通用性:对于预训练失败或成功的场景,自训练都能够应对;
可扩展性:在使用更多标注数据和更好模型时,自训练也能实现优秀的性能。
机器学习领域的一个苦涩教训是:在具备更多标注数据、更多算力或更好的监督训练方法时,大部分方法会失败,不过这种情况并没有出现在自训练这里。
现有的自训练方法也有局限。相比基于预训练模型进行微调,自训练需要更多算力。根据预训练模型的质量、数据增强的强度和数据集规模,预训练可实现 1.3 至 1.8 倍的加速。此外,低数据应用(如 PASCAL 分割)也需要优秀的预训练模型。
论文下载
在CVer公众号后台回复:自训练,即可下载本论文
重磅!CVer-论文写作与投稿交流群成立
扫码添加CVer助手,可申请加入CVer-论文写作与投稿 微信交流群,目前已满2000+人,旨在交流顶会(CVPR/ICCV/ECCV/ICML/ICLR/AAAI等)、顶刊(IJCV/TPAMI等)、SCI、EI等写作与投稿事宜。
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如论文写作+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
![]()
▲长按加微信群
![]()
▲长按关注CVer公众号
整理不易,请给CVer一个在看!![]()