ECCV 2020 | 利用单帧标注进行视频时序动作检测
点击上方“CVer”,选择加"星标"置顶
重磅干货,第一时间送达

论文已上传,文末附下载方式
本文作者:Flowerfan
https://zhuanlan.zhihu.com/p/158594785
本文已由原作者授权,不得擅自二次转载

论文题目: SF-Net: Single-Frame Supervision for Temporal Action Localization
论文地址: arxiv.org/abs/2003.06845
作者:Fan Ma, Linchao Zhu, Yi Yang, Shengxin Zha, Gourab Kundu, Matt Feiszli, Zheng Shou
Code: https://github.com/Flowerfan/SF-Net
Task & Motivation:
本文解决的是视频分析中的时序动作检测问题,目的是根据给定的训练数据训练模型,并且在测试视频中检测出目标动作的发生时间范围。
以前的视频时序动作检测训练数据主要有两种,一种是给定视频中所有动作的开始起止时间(fully supervised), 另外一种是指只给整个视频中出现的动作类别(weakly supervised)。本文采用的是介于两种之间的标注数据,即对视频中每一个动作,只给定动作中的标记数据。如下图:
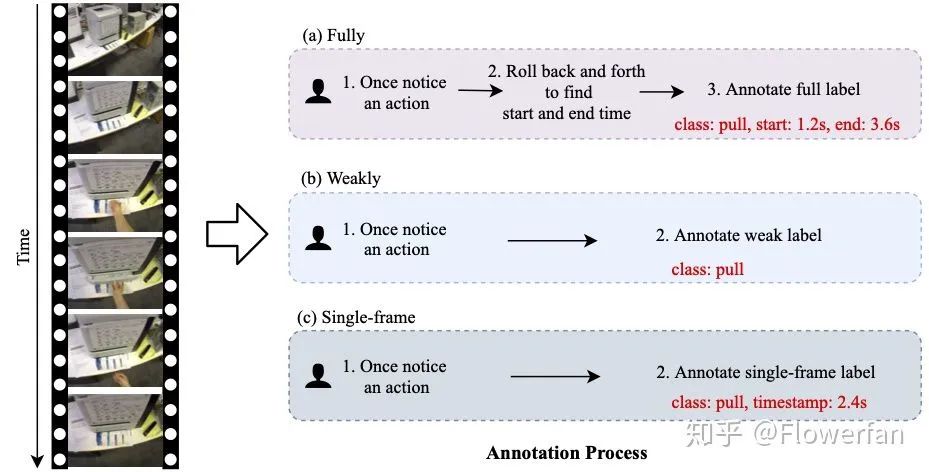
Fully 标注一般需要给出每个动作的起止结束时间,这个在人工标记的时候比较麻烦。在标记视频动作边界的时候,标注者可能需要反复观看视频。而这个过程及其耗时,对于某些段时间内发生的动作,可能还需要放慢倍数对动作的时间边界进行准确的标注。一个10分钟的视频中有10个目标动作,人工标记的时间很可能远远超过10min,有时候还需要多个标注者标注同一个视频来校准边界标注。
为了缩短人工标记时间,weakly 标注应运而生。这两年也出现了很多基于weakly标注的工作。然而基于weakly标注训练得到的模型比基于fully标注训练得到的模型性能要差很多(评估指标主要是AP@IoU, 这一点和object detection 比较相似). 另外目前的两个主流数据集(THUMOS, ActivityNet)每一个视频中基本是单一动作,THUMOS是一个视频中有多个动作,但是多个动作基本是同一类别,AcitivityNet数据集中一个视频基本只含1-2个动作。如果单个视频中包含多个不同多动作,而训练数据集又不是很大的,weakly的方法失效的概率比较大。
此外,对于某些动作检测的场景,准确的视频时序定位可能没有太必要,我们有时只需定位到的相关的动作发生区间即可。例如,对于某个车辆违章的动作,检察员在观看的时候,检测系统只需给出违章动作出现的大致时间点即可,检察员然后再去相应时间区检查违章情况。
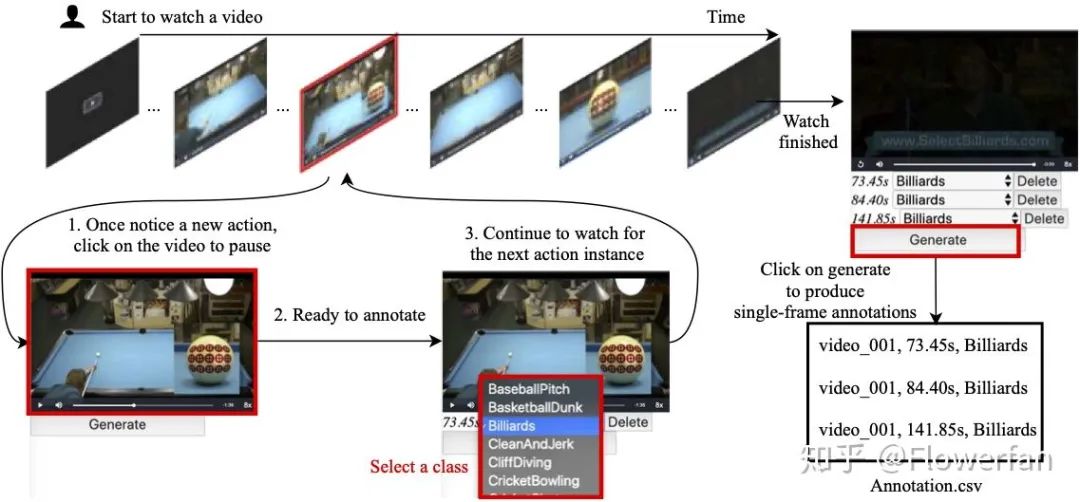
基于上面的考虑,本文提出的一种标注方法——单帧动作标注(Single-Frame)。在观看视频的时候(可以多倍速看节省时间),标注者只需要注意到目标动作视频出现的话,便可以按下暂停键进行动作类别标记,这个和weakly标记几乎是完全一致的,并且标记的动作单帧时间可以由标注工具自动生成,不需要额外的人工记录。因此,我们用和weakly 差不多的标注时间,得到了一种监督信息更强的标注数据——单帧动作标注。这样训练的时候,这些单帧动作时间可以为模型提供更多更有效的信息,取得更好的效果。我们设计的简易的标注工具大概是下面这样:
Framework
基于视频的的单帧标注,我们设计的SF-Net模型框架长这样:
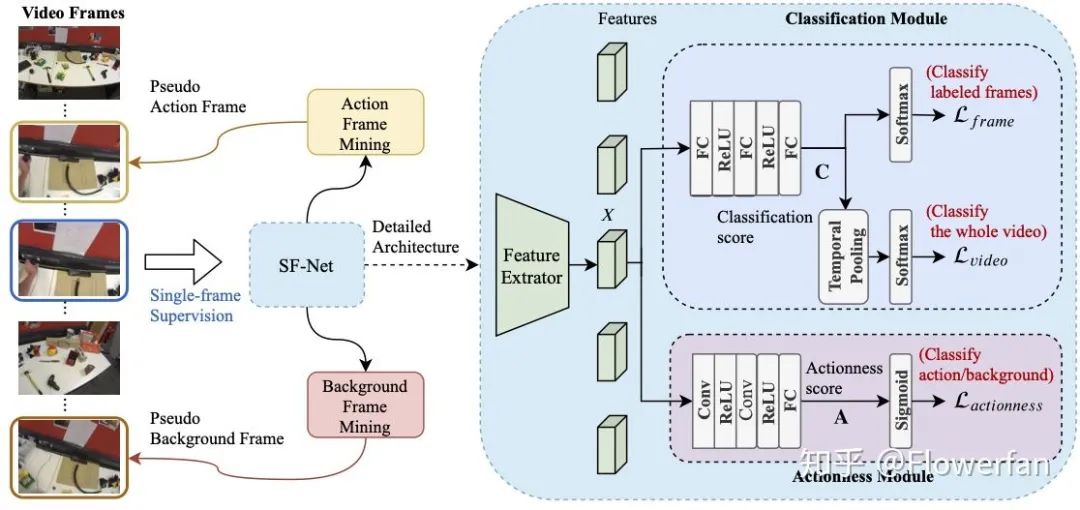
左边的是模型训练的主要逻辑。首先利用标注的单帧数据进行模型训练,并且在训练过程中,选出额外背景和动作帧作为额外的数据进行训练。
右边的事模型的主要构成。模型主要包含两个模块,动作分类模块(classificaiton module)和动作识别模块(actionness module)。动作分类模块包含视频整体分类和动作帧分类。视频整体分类的思路与weakly基本一致, 采用temporal pooling得到视频全局特征直接分类。动作识别模块主要用于区分每一帧是否包含动作 和挖掘额外的动作背景帧进行再训练。
背景帧挖掘是基于分类(classification score)和动作(actionnes score)得分来判别的。为了进一步提升background的准确度,在实现的过程中,我们对一个batch的视频中的所有帧的分类和动作得分进行排序,背景类别得分比较高的帧会作为新的标记数据加入到模型训练中。
Dataset
我们一共在三个数据集上进项了标注, GTEA, BEOID, 和 THUMOS14。(ActivityNet实在是标不动了)。GTEA 和 BEOID 都是相对比较小的数据集,但是视频的难度比THUMOS14和ActivtyNet要到。一是这两个数据集都是第一人称视角的数据集,背景晃动比较厉害。其次就是 这两个数据集中一个视频通常包含很多个不同类别的动作。
Experiment
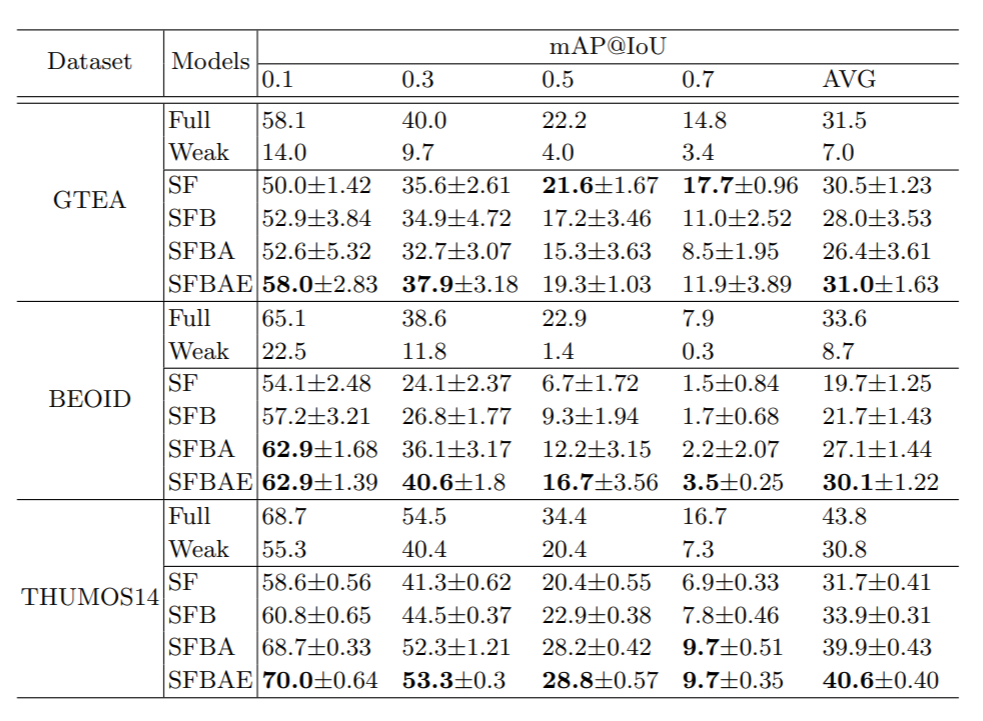
上面是Fully, Wekaly, 和single-frame 使用同一模型的比较结果。可以看到再GTEA 和 BEOID这两个数据集上,weakly的方法失效了,检测结果比较差。在使用single-frame的标注数据后,我们的模型与基于fully-supervised的模型相比,对于目标动作的检测性能几乎差不多(lower IoU)。但对于动作的精细发生区间检测(higher IoU),模型的性能表现一般。这主要是由于精细视频动作边界还是需要更多的监督信息来指导模型训练
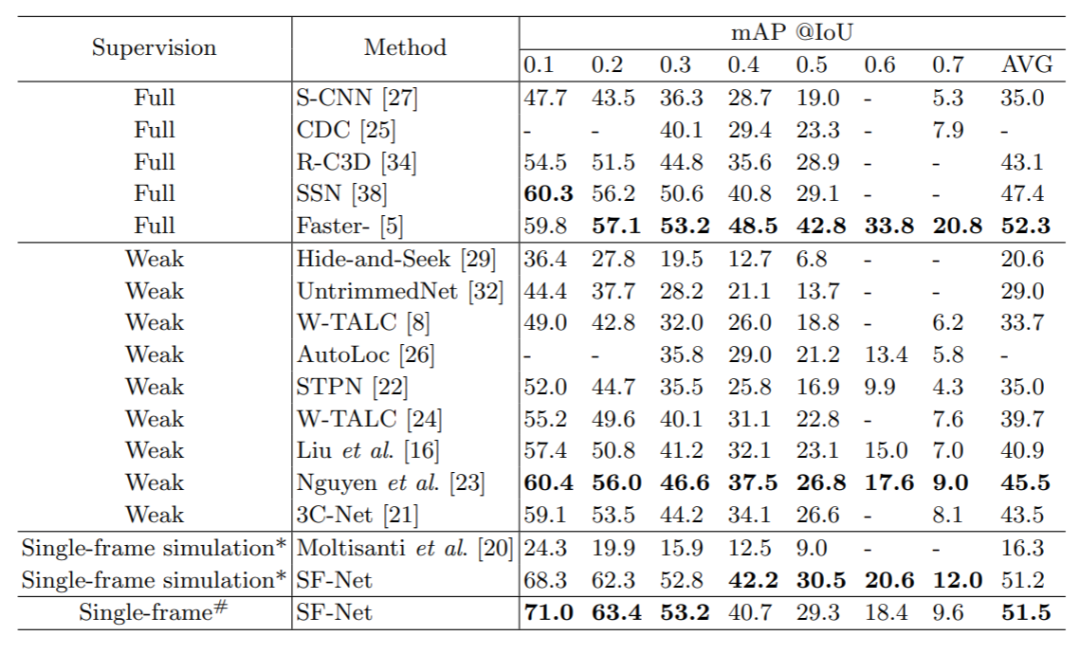
上面是在THUMOS14数据集上和其他方法比较结果。结论基本也是一样的。当只需要定位目标动作的大致发生区间的话,我们的方法还是能取得一个不错的性能。
感谢看完~~ 欢迎点赞转发评论~~
欢迎大家关注悉尼科技大学ReLER实验室的后续工作!
下载
在CVer公众号后台回复:CVPR2020,即可下载CVPR2020 2020代码开源的论文合集
在CVer公众号后台回复:ECCV2020,即可下载ECCV 2020代码开源的论文合集
重磅!CVer-论文写作与投稿交流群成立
扫码添加CVer助手,可申请加入CVer-论文写作与投稿 微信交流群,目前已满2000+人,旨在交流顶会(CVPR/ICCV/ECCV/ICML/ICLR/AAAI等)、顶刊(IJCV/TPAMI等)、SCI、EI等写作与投稿事宜。
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如论文写作+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加微信群

▲长按关注CVer公众号
整理不易,请给CVer点赞和在看!


