【ACL2020】使用问题图生成解决multi-hop复杂KBQA
 !
!
阅读大概需要10分钟 ![]()
跟随小博主,每天进步一丢丢 ![]()


目前解决复杂KBQA(Knowledge Base Question Answering)的难点主要在于:问题带限制以及问题里包含有多个关系。这篇文章提出了一个query graph生成方法解决这个问题。
1. 背景介绍
在了解本文具体做什么之前,需要再明确下什么是带限制的问题和multi-hop of relations。带限制的问题,其实就是带限定词,例如Who was the first president of the U.S,这里的first就是限定词。multi-hop问题,例如像Who is the wife of the founder of Facebook, 包含两个关系,wife of和founder of,这就是多跳问题。目前的工作对于这两个难点都有一些研究进展,但是大多都是解决其中一个问题,针对第一个问题,已有的方法是先识别出一个relation path,再加限定词去形成一个query graph,针对第二个问题,最直接的思路就是扩展relation path,像广度优先搜索那样,但这种方法的问题是随着relation path变长,搜索空间会指数级增大。目前的工作很少有将两个问题一起解决,这篇文章提出一个改进的阶段性问题图生成方法,在延长relation path加入限定词来剪枝,有效的减少了搜索空间。
2. 方法
论文给了一个例子就是下图的Who is the first wife of TV producer that was nominated for The Jeff Probst Show? 这句话中有两个relation——“wife of”, “nominated for”, 两个constraint——”first“,”TV producer”。
接下来我们以一种比较直观的方式根据下图看看如何生成query graph,首先从一个grounded entity “The Jeff Probst Show”出发,找到一条核心relation path连接entity和answer,如果没有多余的限定词和其他关系,那这个answer就是图中的x,但是因为还有限定词,所以这个x变成了y1,一个中间节点。从y1接着往下走,加入问题中的限定词(如图所示的两个constraints,其中第二个argmin代表的是first,可以理解为在众多选项中选择最小的一个)。当我们已经找到所有候选query graphs,再通过和问题相似度进行排名,这一步通常使用CNN实现。最后选择分数最高的query graph来答题。
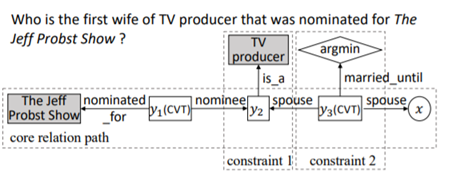

每一次迭代结束后,都会对候选query graphs进行排序,排序的方法是对每一个query graph进行一个7-dimensional向量的求导,在把这些向量送入一个全连接层,最后用softmax算出概率。
向量的第一维是BERT的词向量,第二维是所有grounded entity的linking scores,第三维是所有出现在query graph里的grounded entities的数量,四五六分别是实体类别,短语和最高级词语的数量,最后一维是答案的数量。
3. 实验与结果
(1) 实验设置
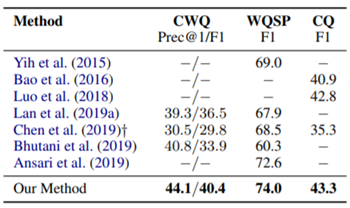
实验结果如图所示,作者和之前的一些模型进行了对比。图片中列举的前三个是不能解决multi-hop问题,第四个是没有使用beam search或者constraints来减少搜索空间。第五个是使用了beam size为1的beam search但没有解决constraints。六七两个是把复杂问题解构成简单问题。
实验结果证明作者的方法要好于前人的工作。
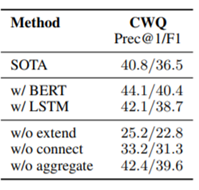
作者为了证明模型的有效性并不是依赖BERT,他们把BERT换成了LSTM,分数依然超越之前的模型。同时,作者还测试了去除掉extend/connect/aggregate三个动作的分数,结果如下图
4. 总结
下载一:中文版!学习TensorFlow、PyTorch、机器学习、深度学习和数据结构五件套!
![]()
![]()
![]()
后台回复【五件套】
下载二:南大模式识别PPT
![]()
后台回复【南大模式识别】




由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方“深度学习自然语言处理”,进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
整理不易,还望给个在看!



