【IJCAI2020-华为诺亚】面向深度强化学习的策略迁移框架
Efficient Deep Reinforcement Learning via Adaptive Policy Transfer
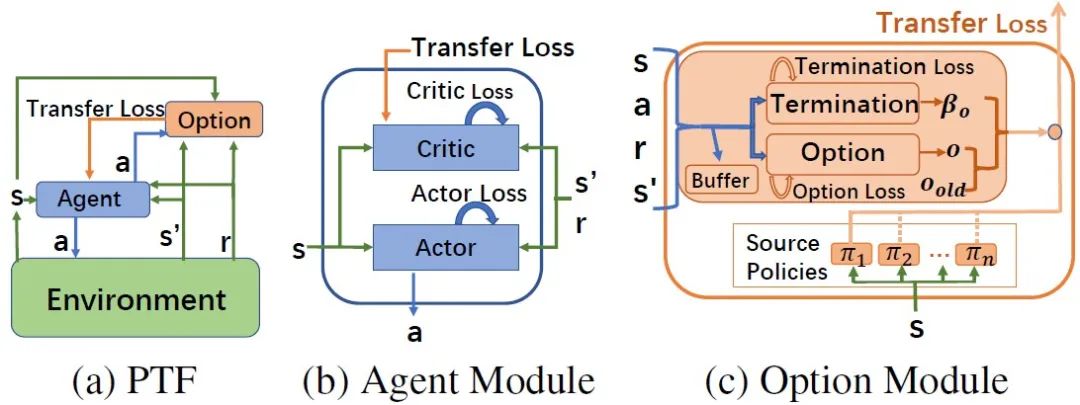
深度强化学习解决很多复杂问题的能力已经有目共睹,然而,如何提升其学习效率是目前面临的主要问题之一。现有的很多方法已验证迁移学习可利用相关任务中获得的先验知识来加快强化学习任务的学习效率。然而,这些方法需要明确计算任务之间的相似度,或者只能选择一个适合的源策略,并利用它提供针对目标任务的指导性探索。目前仍缺少如何不显式的计算策略间相似性,自适应的利用源策略中的先验知识的方法。本文提出了一种通用的策略迁移框架(PTF),利用上述思想实现高效的强化学习。PTF通过将多策略迁移过程建模为选项(option)学习,option判断何时和哪种源策略最适合重用,何时终止该策略的重用。如图1所示,PTF分为两个子模块,智能体(agent)模块和option模块。Agent模块负责与环境交互,并根据环境的经验和option的指导进行策略更新。以PTF-A3C为例,agent模块的策略更新公式如下:
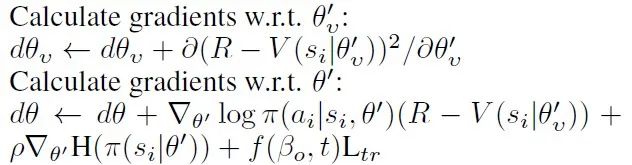
其中,agent模块对源策略的利用通过添加一个额外的损失函数,该损失函数计算agent策略与源策略之间的差异。根据option的终止函数,我们提出了一种自适应调整策略重用的机制,为损失函数设计了启发式的权重系数,避免负迁移的出现。Option模块负责option的值网络和终止网络的学习,option的值函数更新参考DQN的更新方式,最小化损失函数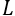
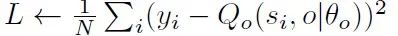
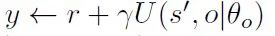
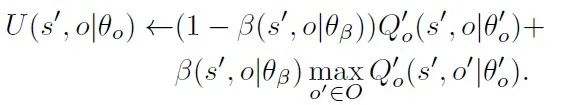
Option模块通过计算以下梯度更新终止网络的参数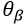
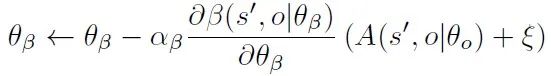
【诺亚决策推理RL研究团队与天津大学、南京大学等联合研究工作】
参考:
https://mp.weixin.qq.com/s/B5w7LsI7bAyY-drCY384LA
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“RLAPT” 可以获取《【IJCAI2020-华为诺亚】面向深度强化学习的策略迁移框架》专知下载链接索引





