使用GAN生成序列数据
【导读】序列数据十分常见,但由于隐私,法规限制了对有用数据的访问,这极大地减慢了对研发至关重要的有用数据的访问。因此产生了对具有高度代表性但又完全私有的合成序列数据的需求。本文介绍了生成序列工具的DoppelGANger。它基于生成对抗网络(GAN)框架生成复杂顺序数据集。
生成序列数据比表格数据更具挑战性,在表格数据中,通常将与一个人有关的所有信息存储在一行中。在序列数据中,信息可以分布在许多行中,例如信用卡交易,并且保留行(事件)和列之间的相关性。此外,序列的长度是可变的。有些案例可能只包含少量交易,而其他案例则可能包含数千笔交易。
顺序数据和时间序列生成模型已经得到了广泛的研究,在许多情况下,模型都是针对特定问题设计,因此需要详细的领域知识。
我们通过引入两项创新来构建这项工作:
一种学习策略,可加快GAN的收敛速度并避免模式崩溃。
经过精心设计的鉴别器可提高模型的稳定性 。
引入DoppelGANger以生成高质量的合成时间序列数据
我们对DoppelGANger模型进行了修改,以解决顺序数据生成模型的局限性。
由于以下问题,传统的生成对抗网络或GAN难以对顺序数据进行建模:
它们没有捕获时间特征及其相关(不变)属性之间的复杂关联:例如,根据所有者的特征(年龄,收入等),交易中的信用卡模式非常不同。
时间序列内的长期相关性,例如昼夜模式:这些相关性与图像中的相关性在质量上有很大的不同,图像具有固定的尺寸,不需要逐个像素地生成。
DoppelGANger结合了一些创新的想法,例如:
使用两个网络(一个多层Perceptron MLP和一个递归网络)来捕获时间依赖性
分离归因生成,以更好地捕获时间序列及其属性(例如用户的年龄,位置和性别)之间的相关性
批量生成-生成长序列的小堆叠批次
解耦归一化-将归一化因子添加到生成器以限制特征范围
DoppelGANger将属性的生成与时间序列解耦,同时在每个时间步将属性馈送到时间序列生成器。
DoppelGANger的条件生成体系结构还提供了更改属性分布和对属性进行条件调整的灵活性。这也有助于隐藏属性分布,从而增加隐私性。
DoppelGANger模型还具有生成以数据属性为条件的数据特征的优势。
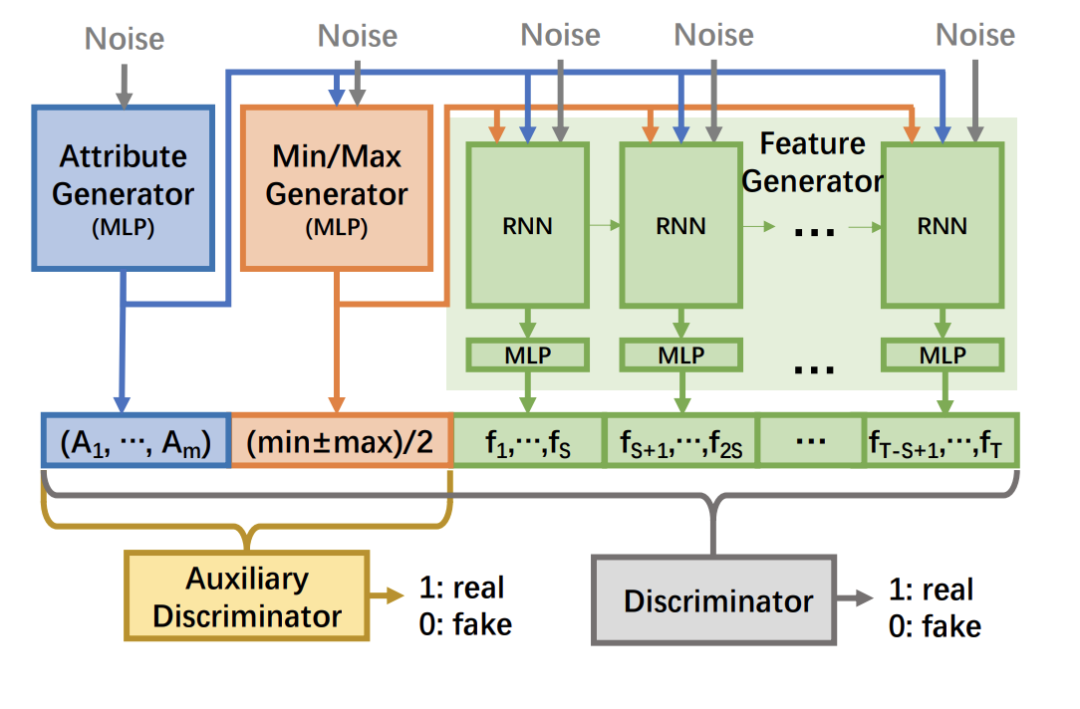
该模型的另一个巧妙特征是它如何处理极端值,这是一个非常具有挑战性的问题。顺序数据在样本中具有广泛的范围并不少见-有些产品可能有成千上万笔交易,而另一些则只有几笔。对于GAN来说,这是有问题的,因为它会产生模式崩溃-样本将仅包含最常见的,而忽略罕见值。这就是为什么DoppelGANger的作者提出了一种创新的方式来处理这些情况:自动归一化。它包括在训练之前对数据特征进行归一化,并将特征的最小和最大范围添加为每个样本的两个附加属性。
在生成的数据中,这两个属性通常会将要素缩放回现实范围。这可以通过三个步骤完成:
使用多层感知器(MLP)生成器生成属性。
将生成的属性作为输入,使用另一个MLP生成两个“伪”(最大/最小)属性。
将生成的真实和假属性作为输入,生成要素。
在银行交易数据上训练DoppelGANger模型
首先,我们在银行交易数据集上评估了DoppelGANger。我们的目的是证明该模型能够学习数据中的时间依赖性。
如何准备数据?
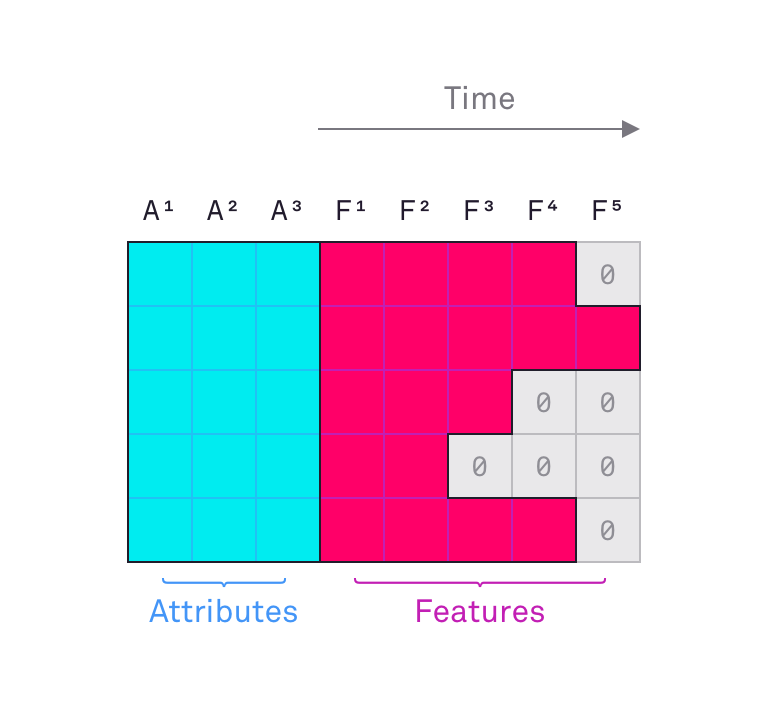
我们假设需要生成一组最大长度为Lmax的数据-在这里我们设置Lmax =100。每个序列包含一组属性A(固定数量)和特征F(交易)。在我们的例子中,唯一的属性是初始银行余额,其特征是:交易金额(正数或负数)以及两个描述交易的其他类别:标志和描述。
要运行模型,我们需要三个NumPy数组:
data_feature:训练特征,采用NumPy float32数组格式。大小为[(训练样本数)x(最大长度)x(特征的总尺寸)]。分类特征通过一键编码存储。
data_attribute:训练属性,为NumPy float32数组格式。大小为[(训练样本数)x(属性的总维数)]。
data_gen_flag:标志阵列,指示特征的激活。大小为[(训练样本数)x(最大长度)]。
此外,我们需要一个Output类的对象列表,其中包含每个变量,规范化和基数的数据类型。在这种情况下,它是:
data_feature_outputs = [output.Output(type_=OutputType.CONTINUOUS,dim=1,normalization=Normalization.ZERO_ONE,is_gen_flag=False),# time intervals between transactions (Dif)output.Output(type_=OutputType.DISCRETE,dim=20,is_gen_flag=False),# binarized Amountoutput.Output(type_=OutputType.DISCRETE,dim=5,is_gen_flag=False),# Flagoutput.Output(type_=OutputType.DISCRETE,dim=44,is_gen_flag=False)# Description]
列表的第一个元素是事件Dif之间的时间间隔,其后是经过1个热编码的交易值(金额),然后是标志,第四个元素是交易描述。所有gen_flags均设置为False,因为它是一个内部标志,以后可由模型本身进行修改。
该属性被编码为介于-1和1之间的归一化连续变量,以解决负余额问题:
data_attribute_outputs = [output.Output(type_=OutputType.CONTINUOUS,dim=1,normalization=Normalization.MINUSONE_ONE,is_gen_flag=False)]使用的唯一属性是初始余额。每个步骤的余额只需添加相应的交易金额即可更新。
我们使用Hazy处理器对每个序列进行预处理,并以正确的格式对其进行整形。
n_bins = 20processor_dict = {"by_type": {"float": {"processor": "FloatToOneHot", #FloatToBin""kwargs": {"n_bins": n_bins}},"int": {"processor": "IntToFloat","kwargs": {"n_bins": n_bins}},"category": {"processor": "CatToOneHot",},"datetime": {"processor": "DtToFloat",}}}from hazy_trainer.processing import HazyProcessorprocessor = HazyProcessor(processor_dict)
现在,我们将读取数据并使用format_data函数对其进行处理。辅助变量category_n和category_cum分别存储变量的基数和基数的累积和。
data=pd.read_csv('data.csv',nrows=100000) # read the datacategorical = ['Amount','Flag','Description']continuous =['Balance','Dif']cols = categorical + continuousprocessor = HazyProcessor(processor_dict) #call Hazy processorprocessor.setup_df(data[cols]) # setup the processorcategories_n = [] # Number of categories in each categorical variablefor cat in categorical:categories_n.append(len(processor.column_to_columns[cat]['process']))categories_cum = list(np.cumsum(categories_n)) # Cumulative sum of number of categorical variablescategories_cum = [x for x in categories_cum] # We take one out because they will be indexescategories_cum = [0] + categories_cumdef format_data(data, cols, nsequences=1000, Lmax=100, cardinality=70):''' cols is a list of columns to be processednsequences number of sequences to use for trainingLmax is the maximum sequence lengthCardinality shape of sequences'''idd=list(accenture.Account_id.unique()) # unique account idsdata.Date = pd.to_datetime(data.Date) # format date# dummy to normalize the processorsdata['Dif']=np.random.randint(0,30*24*3600,size=accenture.shape[0])data_all = np.zeros((nsequences,Lmax,Cardinality))data_attribut=np.zeros((nsequences))data_gen_flag=np.zeros((nsequences,Lmax))real_df = pd.DataFrame()for i,ids in enumerate(idd[:nsequences]):user = data[data.Account_id==ids]user=user.sort_values(by='Date')user['Dif']=user.Date.diff(1).iloc[1:]user['Dif']=user['Dif'].dt.secondsuser = user[cols]real_df=pd.concat([real_df,user])processed_df = processor.process_df(user)Data_attribut[i] = processed_df['Balance'].values[0]processed_array = np.asarray(processed_df.iloc[:,1:)data_gen_flag[i,:len(user)]=1data_all[i,:len(user),:]=processed_arrayreturn data_all, data_attribut, data_gen_flag
数据
数据包含大约1000万笔银行交易,我们将仅使用其中包含5,000个唯一帐户的100,000个样本,每个帐户平均20个交易。我们考虑以下领域:
交易日期
交易金额
平衡
交易标记(5级)
描述(44级)
以下是所用数据的标题:
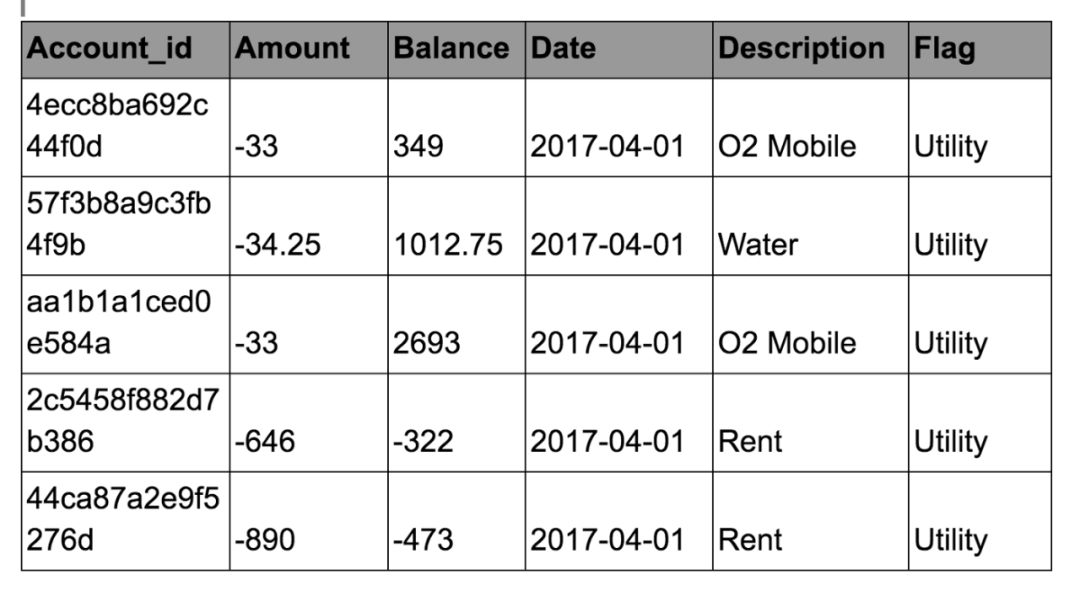
如前所述,时间信息将被建模为两个连续事务之间的时间差(以秒为单位)。
运行代码
我们使用以下参数运行了100个迭代的代码:
import sysimport ossys.path.append("..")import matplotlib.pyplot as pltfrom gan import outputsys.modules["output"] = outputimport numpy as npimport pickleimport pandas as pdfrom gan.doppelganger import DoppelGANgerfrom gan.load_data import load_datafrom gan.network import DoppelGANgerGenerator, Discriminator, AttrDiscriminatorfrom gan.output import Output, OutputType, Normalizationimport tensorflow as tffrom gan.network import DoppelGANgerGenerator, Discriminator, \RNNInitialStateType, AttrDiscriminatorfrom gan.util import add_gen_flag, normalize_per_sample, \renormalize_per_samplesample_len = 10epoch = 100batch_size = 20d_rounds = 2g_rounds = 1d_gp_coe = 10.0attr_d_gp_coe = 10.0g_attr_d_coe = 1.0
请注意,生成器由具有softmax激活函数(用于分类输入)和线性激活(用于连续变量)的层列表组成。生成器和鉴别器均使用Adam算法以指定的学习速率和动量进行了优化。
现在,我们准备数据以供网络使用。real_attribute_mask是一个True / False列表,其长度与属性数相同。如果属性为(max-min)/ 2或(max + min)/ 2,则为False;否则为false。否则为True。首先我们实例化生成器和鉴别器:
# create the necessary input arraysdata_all, data_attribut, data_gen_flag = format_data(data,cols)# normalise data(data_feature, data_attribute, data_attribute_outputs,real_attribute_mask) = normalize_per_sample(data_all, data_attribut, data_feature_outputs,data_attribute_outputs)# add generation flag to featuresdata_feature, data_feature_outputs = add_gen_flag(data_feature, data_gen_flag, data_feature_outputs, sample_len)generator = DoppelGANgerGenerator(feed_back=False,noise=True,feature_outputs=data_feature_outputs,attribute_outputs=data_attribute_outputs,real_attribute_mask=real_attribute_mask,sample_len=sample_len,feature_num_units=100,feature_num_layers=2)discriminator = Discriminator()attr_discriminator = AttrDiscriminator()
我们使用了由两层100个神经元组成的神经网络,用于生成器和鉴别器。所有数据均经过标准化或1热编码。然后,我们使用以下参数训练模型:
checkpoint_dir = "./results/checkpoint"sample_path = "./results/time"epoch = 100batch_size = 50g_lr = 0.0001d_lr = 0.0001vis_freq = 50vis_num_sample = 5d_rounds = 3g_rounds = 1d_gp_coe = 10.0attr_d_gp_coe = 10.0g_attr_d_coe = 1.0extra_checkpoint_freq = 30num_packing = 1
原文链接:
https://medium.com/towards-artificial-intelligence/generating-synthetic-sequential-data-using-gans-a1d67a7752ac






