如何构建一个交互式数据分析 Web 应用?


本文主要介绍如何利用Python的Streamlit库和Heroku云平台来做一个交互式数据分析Web应用。开发环境如下:
Windows10系统
Anaconda3(python3.7.4)
Git(2.26.0.windows.1)
Heroku账号
梯子(Heroku需科学上网才可访问)

Streamlit
根据Streamlit官方文档介绍,它是一个开放源代码的Python库,可以轻松地为机器学习和数据科学构建漂亮的自定义web应用程序。也就是说,即使你对web开发并不熟悉,但只要利用它,就可以很容易搭建出一个Web。
通过“pip install streamlit”进行安装,再执行“streamlit hello”。若安装成功,默认浏览器会自动打开或输入“localhost:8501”,会弹出如下图界面。
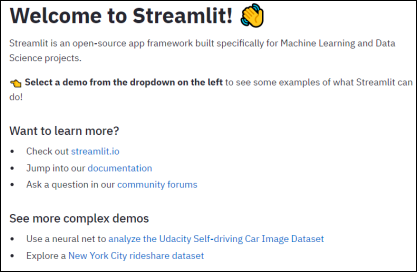
图1 安装成功界面
Streamlit用于数据可视化的话,主要模块有:Cache,Interactive widgets,Charts。
1) Cache
Streamlit遵循由上至下的运行顺序,所以每次代码中有进行任何更改,都会重新开始运行一遍,会十分耗时。@st.cache会对封装起来的函数进行缓存,避免二次加载。如果函数中的代码发生变动,cache会重新加载一遍并缓存起来。假如将代码还原到上一次版本,由于先前的数据已经缓存起来了,所以不会进行二次加载。
import streamlit as st
import time
st.write("Loading....")
start_time = time.clock()
@st.cache()
def expensive_computation(a, b):
time.sleep(5)
return a ** b
a = 2
b = 21
res = expensive_computation(a, b)
st.write("Result:", res)
end_time = time.clock()
st.write("耗时:%0.1f 秒" % (end_time-start_time))
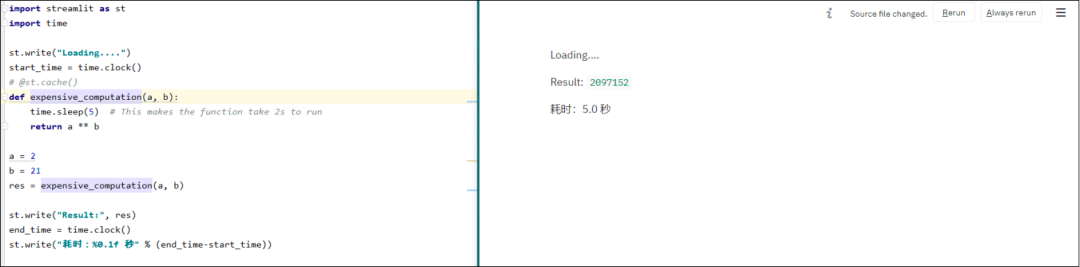
图2 Cache
2) Interactive widgets
Streamlit提供多种组件,如滑块,选择框和按钮等交互组件。利用组件可以灵活地展示数据,这一点类似很多BI工具提供的功能。
import streamlit as st
import pandas as pd
import time
# 按钮
st.subheader("按钮")
if st.button('Say hello'):
st.write('Why hello there')
# 复选框
st.subheader("复选框")
agree = st.checkbox('I agree')
if agree:
st.write('Great!')
# 单选框
st.subheader("单选框")
genre = st.radio(
"What's your favorite movie genre",
('Comedy', 'Drama', 'Documentary'))
if genre == 'Comedy':
st.write('You selected comedy.')
else:
st.write("You didn't select comedy.")
# 选择框
st.subheader("选择框")
option = st.selectbox(
'How would you like to be contacted?',
('Email', 'Home phone', 'Mobile phone'))
st.write('You selected:', option)
# 多选框
st.subheader("多选框")
options = st.multiselect(
'What are your favorite colors',
('Green', 'Yellow', 'Red', 'Blue'),'Yellow')
st.write('You selected:', options)
# 滑块
st.subheader("滑块")
age = st.slider('How old are you?', 0, 130, 25)
st.write("I'm ", age, 'years old')
# 数值输入框
st.subheader("数值输入框")
number = st.number_input('Insert a number')
st.write('The current number is ', number)
# 加载数据
uploaded_file = st.file_uploader("Choose a CSV file", type="csv")
if uploaded_file is not None:
data = pd.read_csv(uploaded_file)
st.write(data)
# 进度条
my_bar = st.progress(0)
for percent_complete in range(100):
time.sleep(0.1)
my_bar.progress(percent_complete + 1)
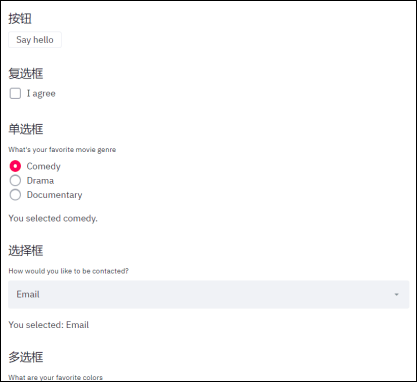
图3 Interactive widgets
3) Charts
Streamlit图库底层基于Matplotlib库搭建,一些常见的图表如折线图,条形图,关系图等,都可以直接传递数据生成图表。此外还增加了deck.gl,可以用于绘制3D地图。
import streamlit as st
import pandas as pd
import numpy as np
# 折线图
st.subheader("折线图")
chart_data = pd.DataFrame(
np.random.randn(20, 3),
columns=['a', 'b', 'c'])
st.line_chart(chart_data)
# 面积图
st.subheader("面积图")
chart_data = pd.DataFrame(
np.random.randn(20, 3),
columns=['a', 'b', 'c'])
st.area_chart(chart_data)
# 条形图
st.subheader("条形图")
chart_data = pd.DataFrame(
np.random.randn(50, 3),
columns=["a", "b", "c"])
st.bar_chart(chart_data)
# 3D图
st.subheader("3D图")
df = pd.DataFrame(
np.random.randn(1000, 2) / [50, 50] + [37.76, -122.4],
columns=['lat', 'lon'])
st.deck_gl_chart(
viewport={
'latitude': 37.76,
'longitude': -122.4,
'zoom': 11,
'pitch': 50,
},
layers=[{
'type': 'HexagonLayer',
'data': df,
'radius': 200,
'elevationScale': 4,
'elevationRange': [0, 1000],
'pickable': True,
'extruded': True,
}, {
'type': 'ScatterplotLayer',
'data': df,
}])
# 关系图
st.subheader("关系图")
st.graphviz_chart('''
digraph {
run -> intr
intr -> runbl
runbl -> run
run -> kernel
kernel -> zombie
kernel -> sleep
kernel -> runmem
sleep -> swap
swap -> runswap
runswap -> new
runswap -> runmem
new -> runmem
sleep -> runmem
}
''')
# 地图
st.subheader("地图")
df = pd.DataFrame(
np.random.randn(1000, 2) / [50, 50] + [37.76, -122.4],
columns=['lat', 'lon'])
st.map(df)
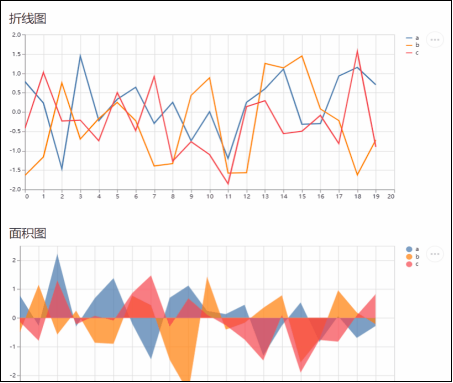
图4 Charts

Heroku
Heroku是一个支持多种编程语言的云平台,如Java,Node.js和Python等等。注册账号需要自备梯子,并且需使用gmail邮箱注册。用户每月可享受1000小时免费时长,以及512M内存,若应用超过30分钟没访问会自动休眠,重新访问即可唤醒。然后,需要下载Heroku CLI命令行工具,下载以后可以使用命令行直接部署。

图5 Heroku支持的语言
图6 Heroku CLI下载页面

应用部署实例
首先,新建一个文件“Streamlit_Demo.py”。
import streamlit
as st
import pandas
as pd
import numpy
as np
st.title(
'Uber pickups in NYC')
DATE_COLUMN =
'date/time'
DATA_URL = (
'https://s3-us-west-2.amazonaws.com/'
'streamlit-demo-data/uber-raw-data-sep14.csv.gz')
@st.cache
def load_data(nrows):
data = pd.read_csv(DATA_URL, nrows=nrows)
lowercase = lambda x: str(x).lower()
data.rename(lowercase, axis=
'columns', inplace=True)
data[DATE_COLUMN] = pd.to_datetime(
data[DATE_COLUMN])
return
data
data_load_state = st.text(
'Loading data...')
data = load_data(
100)
data_load_state.text(
"Done! (using st.cache)")
if st.checkbox(
'Show raw data'):
st.subheader(
'Raw data')
st.write(
data)
st.subheader(
'Number of pickups by hour')
hist_values = np.histogram(
data[DATE_COLUMN].dt.hour, bins=
24, range=(
0,
24))[
0]
st.bar_chart(hist_values)
hour_to_filter = st.slider(
'hour',
0,
23,
17)
filtered_data =
data[
data[DATE_COLUMN].dt.hour == hour_to_filter]
st.subheader(
'Map of all pickups at %s:00' % hour_to_filter)
st.map(filtered_data)
然后,再新建三个文件:Procfile,requirements.txt,setup.sh。这三个文件是部署Streamlit必备的,缺一不可。
1) Procfile
#代码的执行语句
web: sh setup.sh && streamlit run Streamlit_Demo.py
2) requirements.txt
# 代码所需的库及其版本
streamlit==0.56.0
pandas==0.25.1
numpy==1.16.5
3) setup.sh
# 配置
mkdir -p ~/.streamlit/
echo "\
[server]\n\
headless = true\n\
port = $PORT\n\
enableCORS = false\n\
\n\
" > ~/.streamlit/config.toml
最后,配置文件和代码准备好后,可以保存在本机demo路径下。再按照以下步骤进行部署:
1) 进入项目路径,先登录heroku,输入“heroku login”后按下空格键,默认浏览器会自动打开,输入heroku账号和密码后关闭即可。
cd demo
heroku login
2) 创建一个新应用,输入”heroku create xx”,heroku规定应用名称开头结尾只能是小写字母,并且全名只能包含小写字母,数字和破折号。也可以只输入”heroku create”,会自动命名一个应用。
heroku create streamlit-demo-01
# 或者
# heroku create
3) 初始化git代码库,并远程操控heroku。
git init
heroku git:remote –a streamlit-demo-01
git add .
git commit -m "Initialize Project"
# 若git出现"git Please tell me who you are.",运行以下两条命令,再重新执行commit:
# git config user.name "heroku用户名"
# git config user.email "heroku注册邮箱"
4) 上传代码到heroku代码库。
git push heroku master5) 执行”heroku open”打开部署好的应用,若打开后出现” Application error”,需要自行排查是否缺失文件或文件内容有误,笔者一开始因为缺少”setup.sh”文件导致部署失败。另外,笔者直接从github clone后也会报错,所以是在本机新建文件和文件夹的,项目上传至https://github.com/guoxulong/streamlit_demo。
heroku open6) 部署完成后,输入“https://streamlit-demo-01.herokuapp.com/”(需翻墙)就能够访问这个Web。
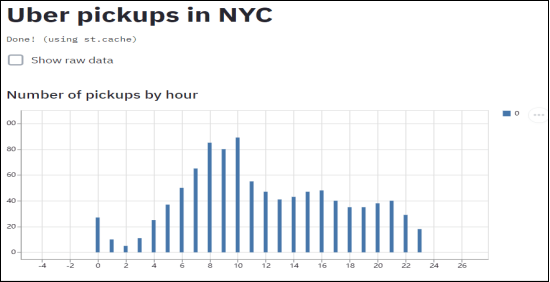
图7 部署完成界面

总结
总体上来讲,相比较用Django框架开发Web,Streamlit开发一个交互式应用会更轻松,虽然功能还不完善,但对于数据分析可视化来说已经满足了,而且只需要掌握Streamlit库的用法就可以实现。
作者:AJ Gordon,对爬虫/机器学习/数据建模/可视化均有所涉猎的数据分析师。

更多精彩推荐
![]()
你点的每个“在看”,我都认真当成了喜欢





