《多任务学习》最新综述论文,20页pdf阐述算法、理论和应用

引言
人类可以同时学习多个任务,在这个学习过程中,人类可以使用在一个任务中学习到的知识来帮助学习另一个任务。例如,根据我们学习打网球和壁球的经验,我们发现打网球的技巧可以帮助学习打壁球,反之亦然。多任务学习(Multi-Task learning, MTL)[1]是机器学习的一种学习范式,受人类这种学习能力的启发,它的目标是共同学习多个相关的任务,使一个任务中包含的知识能够被其他任务利用,从而提高手头所有任务的泛化性能。
在其早期阶段,MTL的一个重要动机是缓解数据稀疏问题,即每个任务都有有限数量的标记数据。在数据稀疏性问题中,每个任务中标记数据的数量不足以训练出一个准确的学习器,而MTL则以数据增强的方式将所有任务中的标记数据进行聚合,从而为每个任务获得更准确的学习器。从这个角度来看,MTL可以帮助重用已有的知识,降低学习任务的手工标注成本。当“大数据”时代在计算机视觉和自然语言处理(NLP)等领域到来时,人们发现,深度MTL模型比单任务模型具有更好的性能。MTL有效的一个原因是与单任务学习相比,它利用了更多来自不同学习任务的数据。有了更多的数据,MTL可以为多个任务学习到更健壮、更通用的表示形式和更强大的模型,从而更好地实现任务间的知识共享,提高每个任务的性能,降低每个任务的过拟合风险。
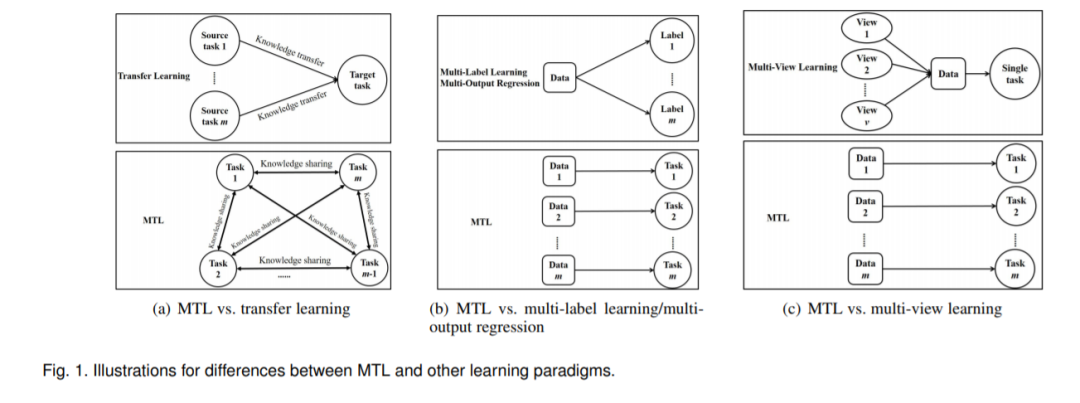
MTL与机器学习中的其他学习范式有关,包括迁移学习[2]、多标签学习[3]和多输出回归。MTL的设置与迁移学习相似,但存在显著差异。在MTL中,不同任务之间没有区别,目标是提高所有任务的性能。而迁移学习是借助源任务来提高目标任务的性能,因此目标任务比源任务起着更重要的作用。总之,MTL对所有的任务一视同仁,但在迁移学习中目标任务最受关注。从知识流的角度来看,迁移学习中的知识转移流是从源任务到目标任务,而在多任务学习中,任何一对任务之间都存在知识共享流,如图1(a)所示。持续学习[4]是一个一个地学习任务,任务是有顺序的,而MTL是将多个任务一起学习。在多标签学习和多输出回归中,每个数据点都与多个标签相关联,这些标签可以是分类的或数字的。如果我们把所有可能的标签都当作一个任务,那么多标签学习和多输出回归在某种意义上可以看作是多任务学习的一种特殊情况,不同的任务在训练和测试阶段总是共享相同的数据。一方面,这种多标签学习和多输出回归的特点导致了与MTL不同的研究问题。例如,排名损失使得与数据点相关的标签的分数(例如分类概率)大于没有标签的分数,可以用于多标签学习,但它不适合MTL,因为不同的任务拥有不同的数据。另一方面,这种在多标签学习和多输出回归中的特性在MTL问题中是无效的。例如,在2.7节中讨论的一个MTL问题中,每个任务都是根据19个生物医学特征预测患者帕金森病的症状评分,不同的患者/任务不应该共享生物医学数据。总之,多标签学习和多输出回归与图1(b)所示的多任务学习是不同的,因此我们不会对多标签学习和多输出回归的文献进行综述。此外,多视图学习是机器学习的另一种学习范式,每个数据点与多个视图相关联,每个视图由一组特征组成。虽然不同的视图有不同的特征集,但是所有的视图是一起学习同一个任务的,因此多视图学习属于具有多组特征的单任务学习,这与图1(c)所示的MTL是不同的。
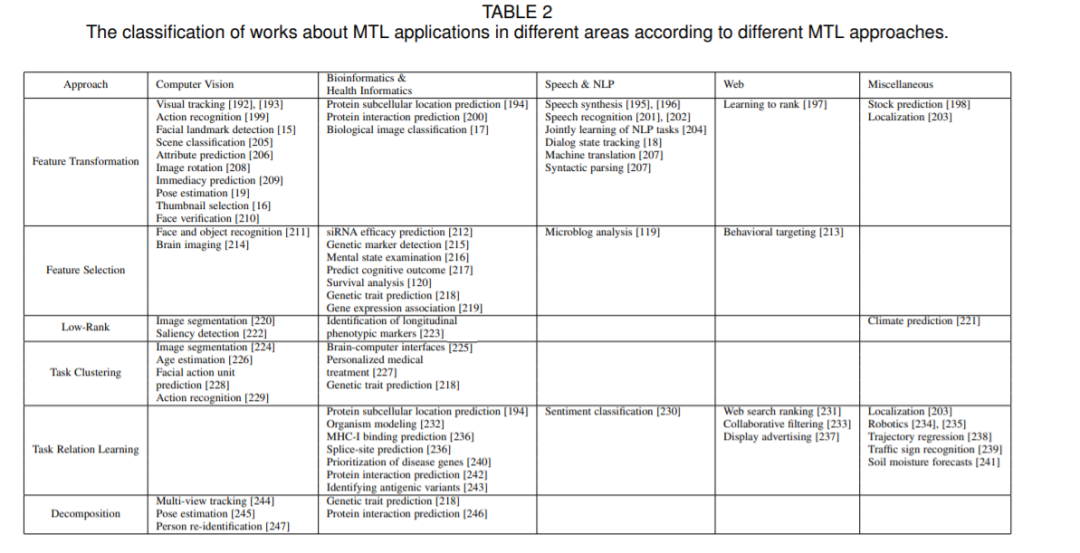
在过去的几十年里,MTL在人工智能和机器学习领域引起了广泛的关注。许多MTL模型已经被设计出来,并在其他领域得到了广泛的应用。此外,对MTL的理论问题也进行了大量的分析。本文从算法建模、应用和理论分析三个方面对MTL进行了综述。在算法建模方面,首先给出了MTL的定义,然后将不同的MTL算法分为5类: 特征学习方法,又可分为特征转换与特征选择方法、低秩方法、任务聚类方法、任务关系学习方法和分解方法。然后,我们讨论了MTL与其他学习范式的结合,包括半监督学习、主动学习、无监督学习、强化学习、多视图学习和图形模型。为了处理大量的任务,我们回顾了在线、并行和分布式的MTL模型。对于高维空间中的数据,引入特征选择、降维和特征哈希作为处理这些数据的重要工具。MTL作为一种很有前途的学习范式,在计算机视觉、生物信息学、健康信息学、语音、自然语言处理、web等领域有着广泛的应用。从理论分析的角度,对MTL的相关工作进行回顾。最后,讨论了MTL的未来发展方向。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“MTL20” 就可以获取《《多任务学习》最新综述论文,20页pdf阐述算法、理论和应用》专知下载链接




