行人重识别算法优化技巧:Bags of Tricks and A Strong Baseline
极市计划做CVPR2019的专题直播分享会,邀请CVPR2019的论文作者进行线上直播,分享优秀的科研工作和技术干货,也欢迎各位小伙伴自荐或推荐优秀的CVPR论文作者到极市进行技术分享~
本周四(3月28日)晚,澳大利亚阿德莱德大学博士生王鑫龙,将为我们分享联合点云分割中的实例和语义(CVPR2019),公众号回复“39”即可获取直播详情。
TeddyZhang:上海大学研究生在读,研究方向是图像分类、目标检测以及人脸检测与识别
本文主要收集并介绍行人重识别(PersonReID)算法中的一些训练技巧,随着深度卷积神经网络的不断改进,行人重识别领域也有了很大的进步,但大多数的SOTA的算法都是设计了很复杂的网络结构和融合了多支路的特征。作者首先设计了一个强力的baseline, 然后尝试使用一个简单的全局特征,并融合了很多有效的训练技巧,使得模型在Market1501数据集上达到了94.5%rank-1以及85.9% mAP。

论文:Bags of Tricks and A Strong Baseline for Deep Person Re-identification
论文链接:https://arxiv.org/abs/1903.07071
开源代码:
https://github.com/michuanhaohao/reid-strong-baseline
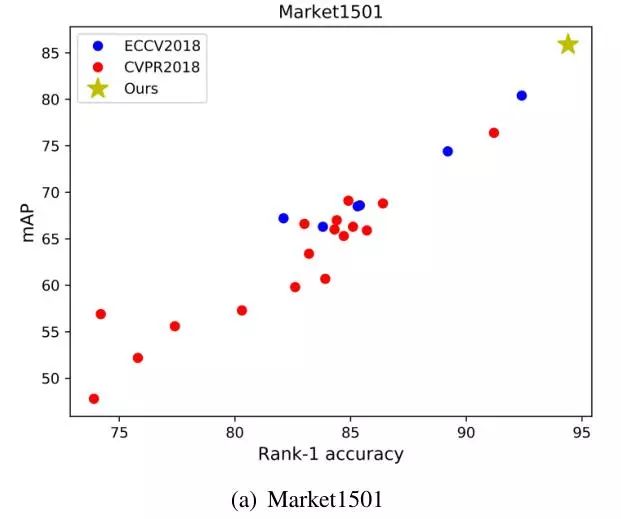
首先作者在Maket1501数据集上对比了ECCV2018和CVPR2018的一些baseline的性能,并与自己提出的baseline作对比,这些baseline大部分都是通过一些训练技巧来提升的,由于在论文中轻描淡写易被忽视,因此作者也建议评价一篇学术论文一定要把训练技巧考虑在内,这样才会更加客观。
StandardBaseline
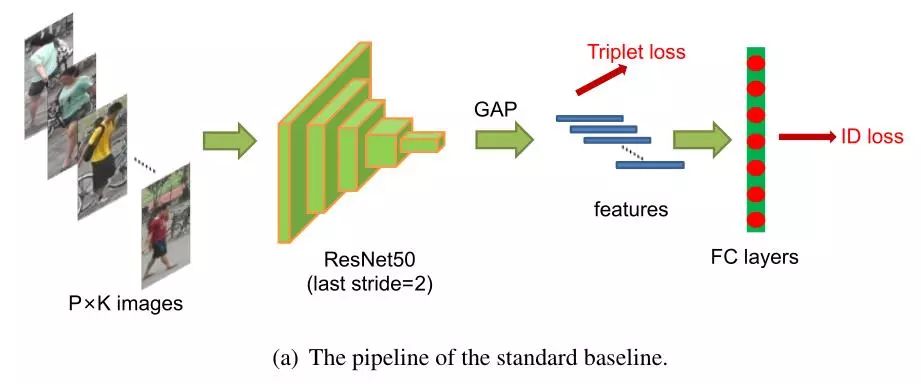
上图为作者所提出的StandardBaseline,其大致流程如下:
使用一个带有ImageNet预训练参数的ResNet50,并改变FC的输出为N,也就是训练集中行人的ID。
随机采样P个身份以及每个人的K幅图片,构成一个batch,并设置P=16, K=4,接着将其resize到256x128,并进行10个像素的zero-padding,接着进行random crop(数据增强)
进行概率0.5的随机翻转,并进行归一化处理(Normalize)
模型输出ReID特征 f 用于计算triplet loss,预测的ID分类p用于计算交叉熵损失,其中triplet loss的margin设置为0.3
使用Adam方法进行优化,一开始学习率为3.5e-4,在40和70个epoch分别降低为原来的10%,共训练120个epoch
TrainingTricks
接下来我们要介绍一些在ReID中十分有效的训练策略,用于提升我们的baseline的精度,让我们一起来看看作者都使用了哪些Trick。
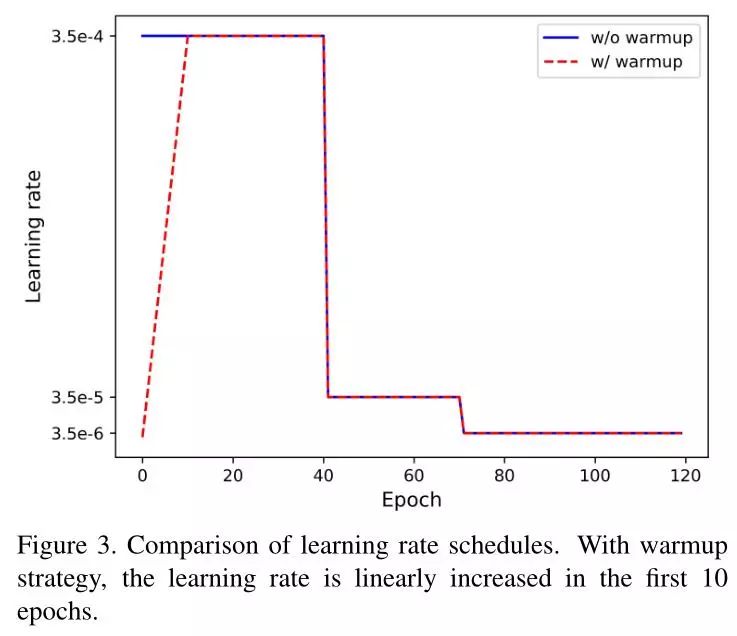
学习率变化策略(Warm up)
参考论文:https://arxiv.org/abs/1608.03983
学习率对ReID的模型有非常大得影响,对于baseline的学习率一开始是一个很大的常量,而经过其他论文提出,Warmup的策略对于行人重识别的模型更加有效,具体是一开始从一个小的学习率经过几个epoch后慢慢上升,如下图红色曲线部分:
具体公式为:
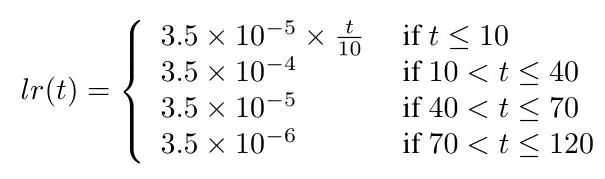
数据增强 Random Erasing
参考论文:https://arxiv.org/abs/1708.04896
这是进行分类问题常见的数据增强方式,对行人检测十分有效!在行人重识别中特别是现实生活中,大部分人体会存在遮挡的情况,为了使模型更具有鲁棒性,我们对每个mini-batch使用REA(RandomErasing Augmentation),REA随机选择一个大小为)的正方形区域,然后对这个区域的像素用一些随机值代替。其中擦除区域面积占比,擦除区域长宽比,,随机概率为0.5,具体算法如下:


Label Smoothing
这也是从分类问题借鉴的一种trick,假设我们网络最后的分类为N,也就是ID的数量。且y为真实的ID标签,而pi为预测的ID分类。则其交叉熵损失为:
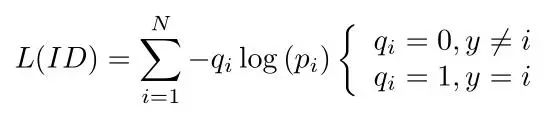
我们在这篇文章中把最后的分类loss叫做ID loss,上面为最常用的Softmaxloss,但是由于标签的形式为One-hot编码的形式,也就是qi只有0和1两个取值,当我们使用Softmax loss进行优化时,模型会不断的优化使得pi为1,但却非常容易造成过拟合。因此label smoothing的思想是对真实标签进行改造,使其不再是One-hot编码。
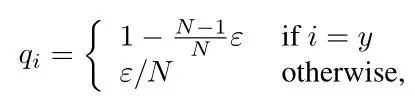
假设N=5,=0.1,假设原来的label为[1, 0,0, 0, 0],经过平滑后变成了[0.92,0.02, 0.02, 0.02, 0.02],这样进行优化时始终与真实标签存在损失,不会使得pi非常接近1,从而降低了过拟合的风险。这么做的原因主要是ReID的测试集的ID并没有在训练集中出现,因此我们需要提高模型的泛化性能,而LabelSmoothing就是一个十分有效的手段。
Last Stride
相关的论文发现在backbone中移除最后一个将采样的操作可以丰富特征的细粒度,作者为了简单方便,直接把ResNet-50的最后一个卷积层的Stride由2变成了1,当输入图片为256x128时,最后一层输出的feature map的尺寸为16x8,而不是原来的8x4。
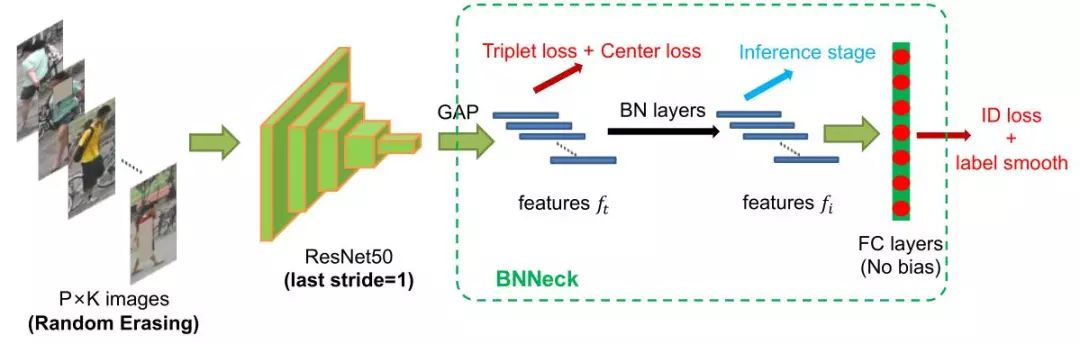
BNNeck
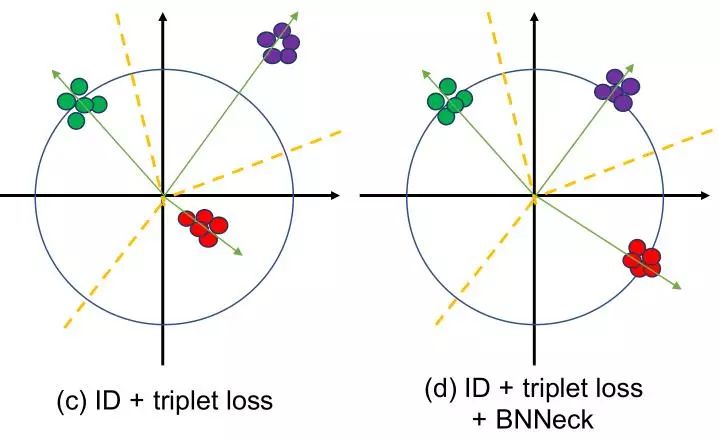
在行人重识别模型中,有很多工作都是融合了ID loss和Triplet loss来进行训练的,但是这种loss函数的目标并不协调,对于ID loss,特别在行人重检测,consine距离比欧氏距离更加适合作为优化标准,而Triplet loss更加注重在欧式空间提高类内紧凑性和类间可分性。因此两者关注的度量空间不一致,这就会导致一个可能现象就是当一个loss减小时另外一个在震荡或增大。因此作者设计了BNNeck用于解决这个问题,如下图:
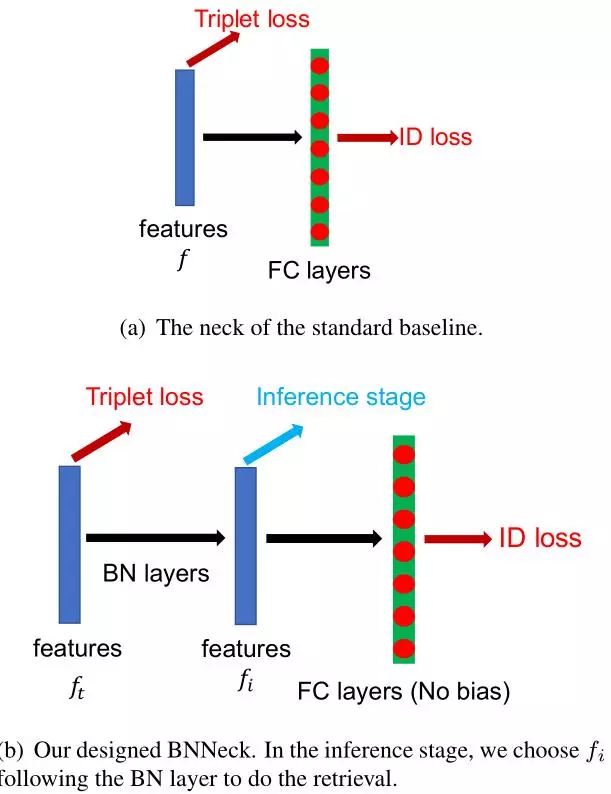
通过神经网络提取特征ft用于Triplet loss,然后通过一个BN层变成了fi,在训练时,分别使用ft和fi来优化这个网络,由于BN层的加入,ID loss就更容易收敛,另外,BNNeck也减少了ID loss对于ft优化的限制,从而使得Triplet loss也变得容易收敛了。因为超球体几乎是对称的坐标轴的原点,BNNECK的另一个技巧是去除分类器fc层的偏差,这个偏差会限制分类的超球面。在测试时,使用fi作为ReID的特征提取结果,这是由于Cosine距离相比欧氏距离更加有效的原因。
Center loss
为了使类内更加的紧凑,作者又加入了人脸识别中提出的CenterLoss, 它在学习到一个类中心的同时会惩罚深度特征和其类中心的距离,这样就弥补了TripletLoss的缺点,我们可以从下图看出,其类间更加紧凑了!
其公式为:
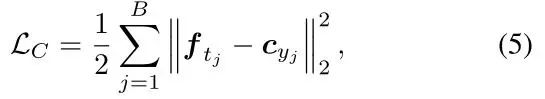
然后我们把三种loss函数进行相加,一起去优化整个网络!
对比试验
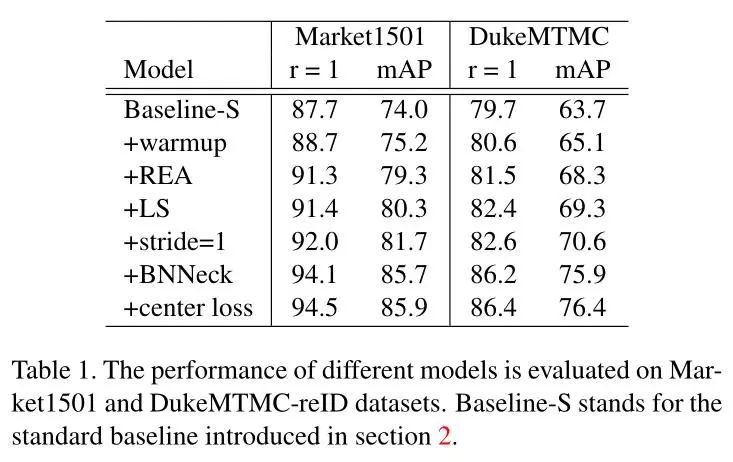
作者首先在同一个数据域下进行试验,分别在Markert1501和DukeMTMC这两个数据集进行训练与测试,结果为
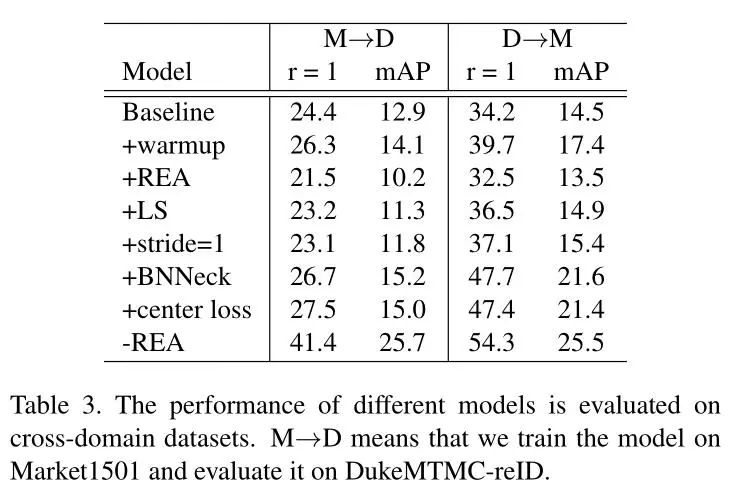
为了展示其鲁棒性,作者又在不同的数据域上进行测试,即使用Market1501训练好的模型在DukeMTMC数据集上验证,得到了如下结果:
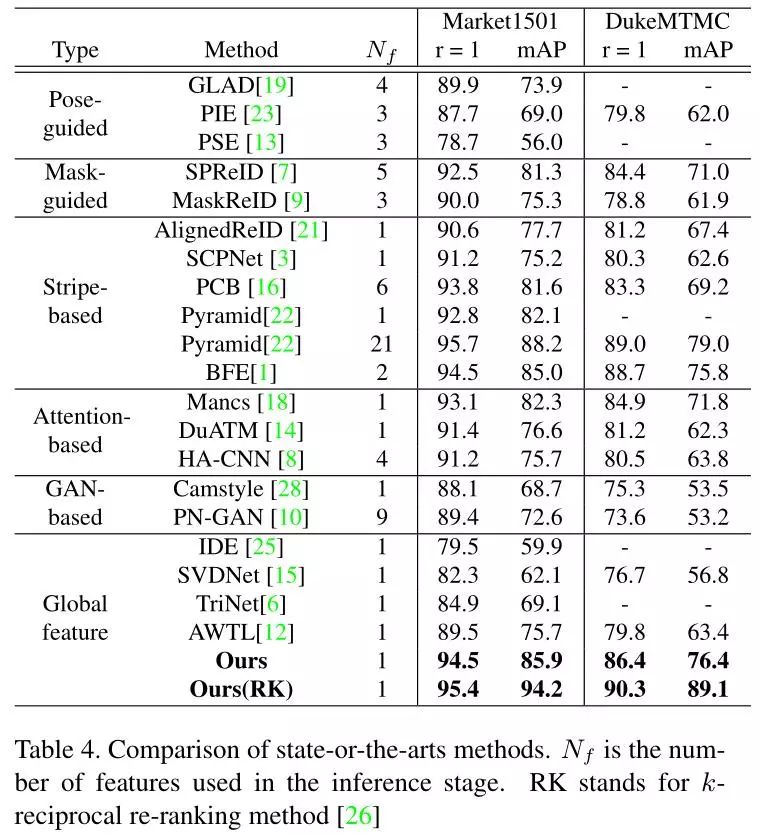
最后与其他模型进行对比:
*延伸阅读
数据集|更大的行人重识别测试集 Market-1501+500k
NIPS 2018 | 行人重识别告别辅助姿势信息,商汤、中科大提出姿势无关的特征提取GAN
CVPR2019 | 03-18日更新13篇论文及代码汇总(包括行人重识别、视频、数据集、姿态估计等)
CVPR2019 | 03-13日更新16篇论文及代码汇总(行人重识别、人体姿态估计、GAN、手写体识别等)
点击左下角“阅读原文”,即可申请加入极市目标跟踪、目标检测、工业检测、人脸方向、视觉竞赛等技术交流群,更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~

觉得有用麻烦给个好看啦~




