干货|掌握机器学习数学基础之优化下[1](重点知识)
推荐阅读时间:8~15min
主要内容(下划线部分):
接上篇博文:干货|掌握机器学习数学基础之优化[1](重点知识)
1、计算复杂性与NP问题
2、上溢和下溢
3、导数,偏导数及两个特殊矩阵
4、函数导数为零的二三事
5、方向导数和梯度
6、梯度有什么用
7、梯度下降法
8、牛顿法
方向导数:在之前讲偏导数的时候,相信很多人已经看出,偏导数求的都是沿着坐标轴的变化率,不管多少维也好,都只是求的变化率,那现在问题来了,如果我想求在某个方向而不是沿着坐标轴方向的变化率怎么求呢?那方向导数,简单来说,就是我们指定任意一个方向,函数对对这个任意方向的变化率.

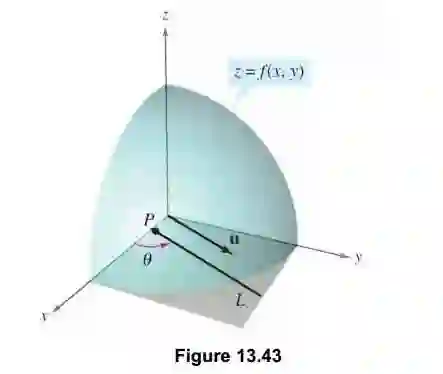

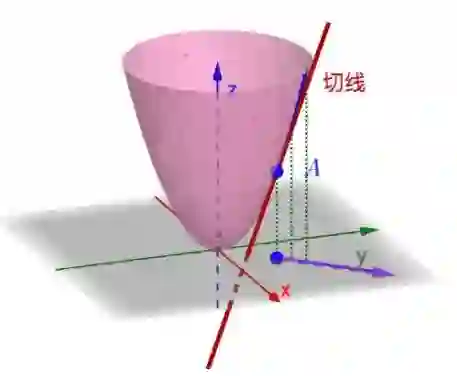
或者说,如下图,我们知道在一维的时候,函数的导数就是在某点对应切线的斜率,那么对于函数f(x,y)的 点在这个方向上也是有切线的,其切线的斜率就是方向导数。当然,注意这个切线是任意的,这里我们要限定其方向,也就是图中中的矢量y的方向。
梯度:是一个矢量或者说是一个向量,其方向上的方向导数最大,其大小正好是此最大方向导数。
梯度的理解很重要,很重要,很重要!下面解决两个问题,梯度怎么求和梯度有什么用?
怎么算?--(介绍一种比较简单之间的方法)
方向导数可以如下的方法算:

简单的讲,假如你在一座山上,蒙着眼睛,但是你必须到达山谷中最低点的湖泊,你该怎么办?然后我们想到一个简单的方法,在每走一步时,都是走那个离谷底最近的那个方向,那怎么求才能使得每一步都下降更大的高度,这个时候我们就完全可以用梯度来帮助我们,就可以完成任务啦!

当然了,我们是在写机器学习数学基础呐,你会说下山有什么用,我们看这篇文章又不是为了下山的。Emmm...别急,下面我们就讲梯度的大用处
不知道讲清楚没有,这两个概念非常重要,下面的优化算法的前提就是梯度,要重点理解

注意:这里只是假设,不用知道这个目标函数就是平方损失函数等等,然后肯定有人问既然要最小化它,那求个导数,然后使得导数等于0求出不就好了吗?Emmmm...是的,有这样的解法,可以去了解正规方程组求解。
说下这里不讲的原因,主要是那样的方式太难求解,然后在高维的时候,可能不可解,但机器学习或深度学习中,很多都是超高维的,所以也一般不用那种方法。总之,梯度下降是另一种优化的不错方式,比直接求导好很多。
梯度下降:我们知道曲面上方向导数的最大值的方向就代表了梯度的方向,因此我们在做梯度下降的时候,应该是沿着梯度的反方向进行权重的更新,可以有效的找到全局的最优解。这个theta的更新过程可以描述为
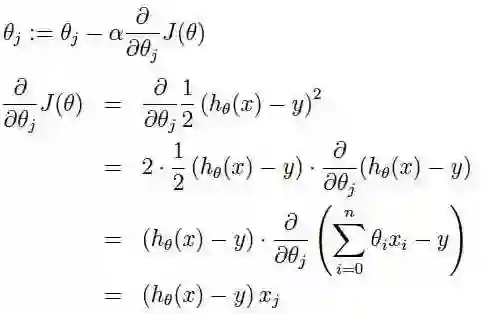
[a表示的是步长或者说是学习率(learning rate)]
好了,怎么理解?在直观上,还是下山,我们可以这样理解,看下图,一开始的时候我们随机站在一个点,把他看成一座山,每一步,我们都以下降最多的路线来下山,那么,在这个过程中我们到达山底(最优点)是最快的,而上面的a,它决定了我们“向下山走”时每一步的大小,过小的话收敛太慢,过大的话可能错过最小值,扯到蛋...)。
转自:机器学习算法与自然语言处理
完整内容请点击请点击“阅读原文”



