赛尔原创 | WWW20 关键词生成提升电商会话推荐
论文名称:Keywords Generation Improves E-Commerce Session-based Recommendation
论文作者:刘元兴,任昭春,张伟男,车万翔,刘挺,殷大伟
原创作者:刘元兴
论文链接:https://dl.acm.org/doi/pdf/10.1145/3366423.3380232
代码链接:https://github.com/LeeeeoLiu/ESRM-KG
转载须注明出处:哈工大SCIR
0 背景
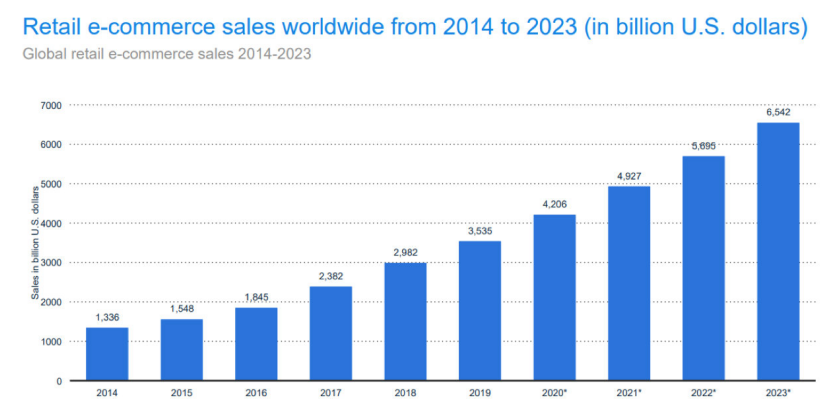
电商平台的崛起改变了人们的购物习惯,越来越多的人习惯在电商平台完成购买需求。根据图1的预测,到2020年底,全球电商销售额将达到4.2万亿美元,占零售总额的16%。因此,预测用户的意图在电商推荐系统中越来越重要[1]。然而由于用户隐私问题和大量用户匿名使用,电商推荐系统通常无法跟踪大部分电商用户的长期用户意图[2]。此外,长期的用户意图跟踪通常会产生粗粒度的结果,这会使推荐不明确[3,1]。用户通常以特定的短期意图访问电商网站或应用,因此我们可以通过其在会话内短期的行为,分析细粒度的购物意图[4]。
1 任务介绍


2 问题及动机
2.1 问题
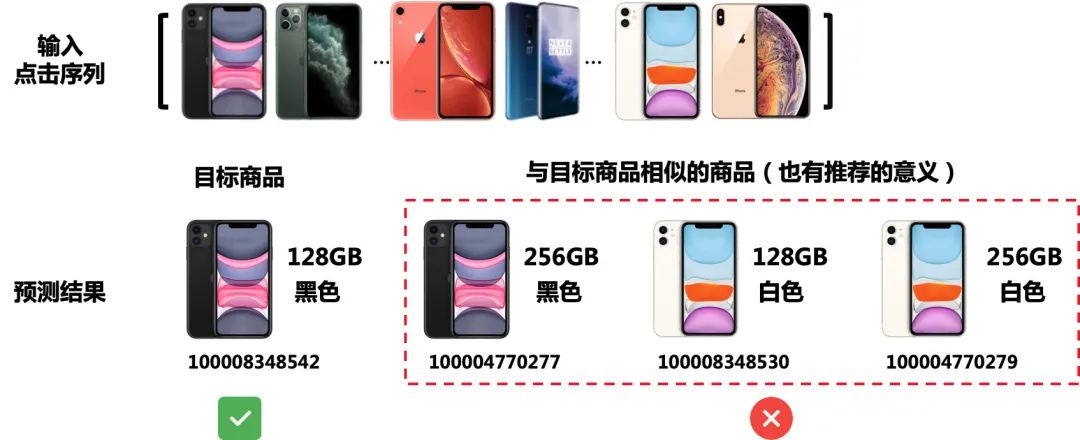
图4 唯一的监督信号会忽略有推荐意义的相似商品
此外,现实电商场景中用户的点击行为非常复杂且难以捉摸,很容易受到电商平台中各种推荐和广告优惠的影响。由于缺乏会话内有关用户意图的监督信息,所有先前的工作都可能受到隐式点击序列中异常点击造成的影响。
2.2 动机

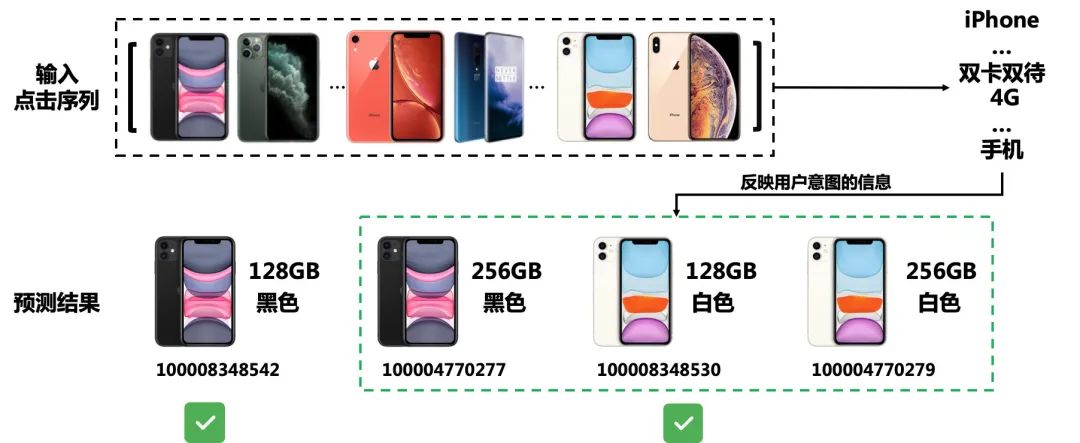
然后,我们设计了一个新的任务,即关键词生成。该任务利用输入的点击序列生成关键词。因此,当我们用多任务学习将基于会话的推荐和关键词生成结合之后,包容性低的问题得到了缓解。以图6为例,不同颜色、不同配置的手机,一定程度上能反映出相似的信息(例如,“iPhone,双卡双待,4G,手机”)。因此,对于推荐系统来说,即使推荐绿框内的三款手机会受到来自目标商品监督的惩罚,但在多任务学习的情况下(当关键词生成任务权重较大时),这三款手机仍可能被推荐系统纳入考虑,推荐的效果会得到提升。其次,因为关键词是按照词频提取的,直接忽略了意外点击的商品的信息。因此,通过引入关键词,也能缓解不可靠点击产生的影响。
3 方法
我们提出带有关键词生成的基于电商会话的推荐模型,简称为ESRM-KG。我们首先介绍概念阐述我们任务的定义。然后,我们分别详细介绍点击预测和关键词生成部分。最后,我们说明模型的整体方法。
3.1 任务定义
与之前基于会话的推荐不同,在本文中我们设计一个新的任务。模型 不只能够产生推荐结果,也能够生成关键词。所以我们定义新任务:
其中 是输入的点击序列、 是产生的推荐结果以及 是生成的关键词。同时受到关键词 和最后一个点击 的监督,模型 能够同时输出推荐列表 和关键词 。

3.2 点击预测
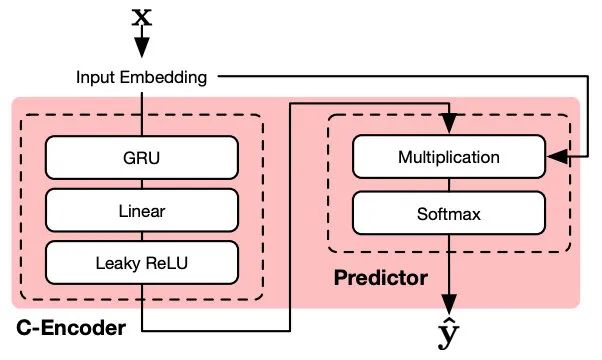
点击预测包含了两个部分:C-Encoder和Predictor,如图8所示。C-Encoder用来学习序列行为的表示。然后Predictor利用C-Encoder编码之后的结果产生推荐列表。
3.3 关键词生成
关于关键词生成,我们采用了Transformer。因为Transformer在文本生成任务中表现出色[10,11,12]。如图9所示,关键词生成部分包含了K-Encoder和Decoder。基于其自注意力机制,K-Encoder可以在当前会话中学习长期依赖的信息。然后,Decoder将信息转换为词概率分布。
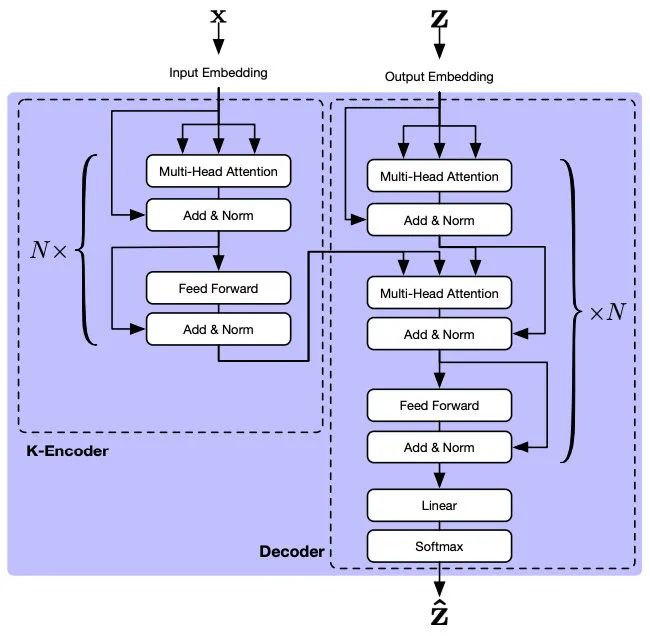
3.4 整体方法
受[3]的启发,我们探索会话的混合表示,来产生更精确的推荐。因为点击预测中的C-Encoder可以学习序列行为的表示,而关键词生成中的K-Encoder在捕获有关当前会话的注意力信息方面做得很好。因此,我们将C-Encoder的输出与K-Encoder的输出拼接,作为会话的混合表示:

我们使用多任务学习框架来训练点击预测和关键词生成组件。
4 实验设置
4.1 数据集
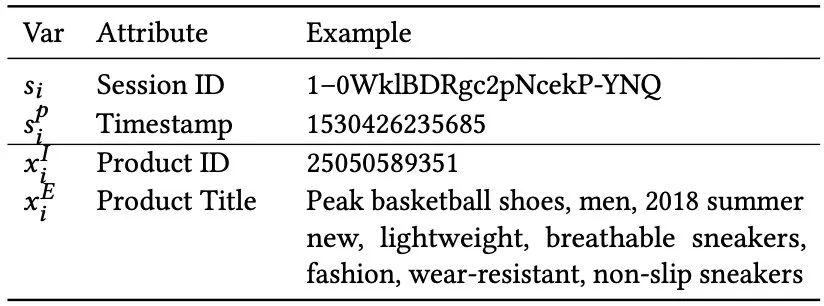
为了验证关键词生成能够提升基于会话的推荐并评估ESRM-KG模型在基于电商会话的推荐中的性能,我们收集了一个大规模的真实世界数据集。首先,我们介绍数据收集的过程。我们从真实的电商平台收集用户在2018年7月1日的点击。然后利用用户点击的表和2018年7月1日的商品信息表求交来过滤没有商品信息的商品。接下来,我们使用LTP[13]对商品标题进行分词。我们得到处理后的点击数据,其中包括会话ID,时间戳,商品ID和商品标题,如表1所示。
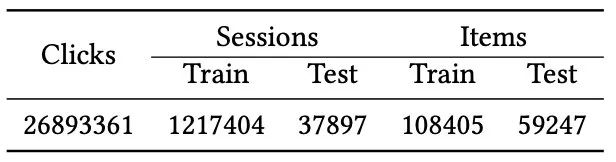
然后,我们进一步处理收集的点击数据以进行实验。我们通过会话唯一的ID将点击数据分成多个会话。参考[3],我们保留了会话长度范围为5到20的会话。然后我们将最后两个小时的会话作为测试集,其余的会话作为训练集。表2提供了我们收集的实验数据集的详细统计信息。
4.2 评价指标
我们采用了Recall@K和MRR@K来评价点击预测。在实验中,K=5, 10, 15, and 20。
在关于关键词生成中,我们采用ROUGE[14]作为评价指标。在我们的实验中,我们使用ROUGE-1(R-1),ROUGE-2(R-2),ROUGE-L(R-L)。
5 实验结果与分析
关于实验,我们设置了六个研究问题:
RQ1:关键词生成可以提升基于会话的推荐的性能吗?ESRM-KG在点击预测中的整体表现如何?
RQ2:在点击预测中,K-Encoder和C-Encoder各自起到了什么作用?哪一个更重要?
RQ3:在多任务学习中,不同权重下的点击预测的性能如何?点击预测的性能会随着多任务学习中的权重的增大而提高吗?
RQ4:关键词的长度是否对点击预测的效果有影响?长关键词能否取得更好的效果?
RQ5:ESRM-KG生成的关键词的质量如何?
RQ6:基于会话的推荐是否有助于关键词生成?
其中RQ1是关于模型的整体效果,用来验证关键词生成能否提升基于会话的推荐的效果。关于RQ2、3、4,我们分别探索了模型不同组成部分对推荐性能的影响。关于RQ5,我们分析了生成的关键词的质量。最后,设置RQ6的的目的是更好地探索关键词生成和基于会话的推荐之间的关系。
5.1 关键词生成对点击预测的影响
RQ1:关键词生成可以提升基于会话的推荐的性能吗?ESRM-KG在点击预测中的整体表现如何?
5.1.1 点击预测的整体性能
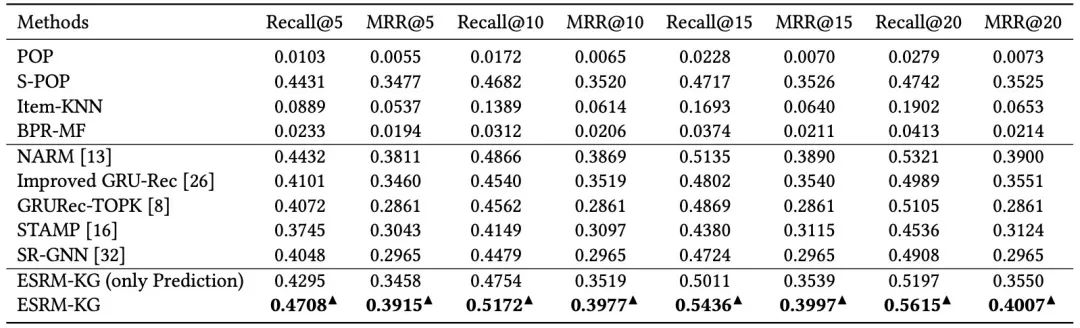
我们发现对于所有K取值的Recall和MRR,ESRM-KG模型始终优于ESRM-KG (only Prediction)。ESRM-KG (only Prediction)表示ESRM-KG模型删除了关键字生成部分。因为NARM在我们的实验中具有最佳性能,我们将NARM设置为主基线,来评估我们方法的整体性能。通过将关键词生成应用于模型,我们发现我们提出的ESRM-KG模型在Recall和MRR方面优于所有基线。我们的模型分别在Recall@5,Recall@10,Recall@15和Recall@20方面比NARM分别提高了6.23%,6.29%,5.86%和5.53%。在MRR方面,我们发现ESRM-KG的表现也相当不错。就MRR@5,MRR@10,MRR@15和MRR@20而言,它比NARM分别增长2.73%,2.79%,2.75%和2.74%。
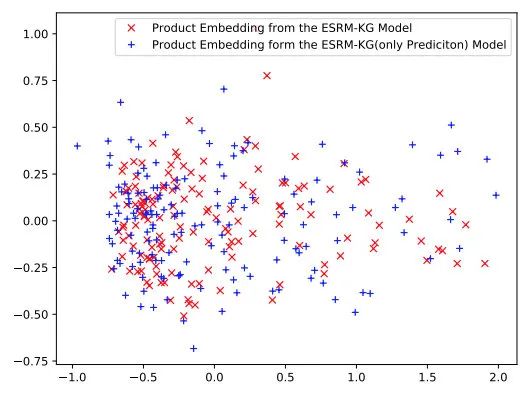
5.1.2 Embedding 可视化
5.1.3 输入和输出的样例分析
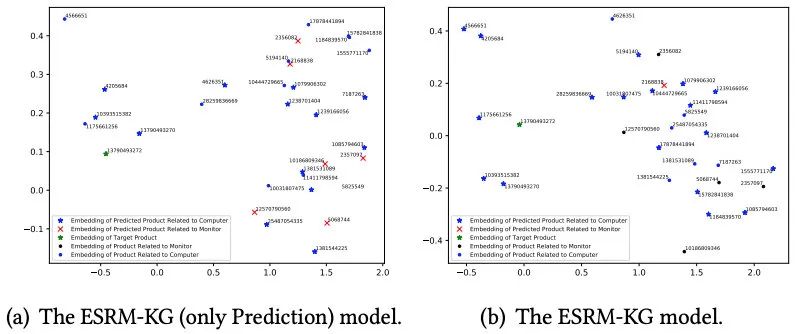
我们展示了模型输入和输出的样例。为了方便观察,我们用商品图片替换商品ID。在输入点击序列中,我们注意到大多数商品与一类商品(即主机)相关。因此,我们将主机当作当前会话的意图。从表4中,我们可以观察到:由于缺少其他信息,意外点击(即输入点击序列中的第10个点击,显示器)会对推荐产生严重的影响。具体而言,在ESRM-KG (only Prediction)模型提供的推荐列表的前20名中,有6种商品与显示器相关。在关键词生成的帮助下,ESRM-KG模型从点击序列中学习到额外的信息。因此,大多数推荐结果与主机有关。此外,通过比较两个模型的推荐列表中目标商品的排名,我们发现ESRM-KG模型推荐效果更好。最后,从ESRM-KG模型生成的关键词中,我们可以观察到ESRM-KG模型在捕获当前会话的意图方面表现良好。

此外,在上述情况下,我们还展示了商品Embedding可视化。如图12所示,我们发现ESRM-KG模型产生的商品Embedding比ESRM-KG(only Prediction) 模型产生的商品Embedding更稠密。根据以上讨论,我们得出结论,关键词生成有助于基于会话的推荐。
5.2 不同编码器对点击预测的影响
RQ2:在点击预测中,K-Encoder和C-Encoder各自起到了什么作用?哪一个更重要?
ESRM-KG(E=encoder)表示点击预测的预测器仅使用编码器中的表示来产生推荐。因此,我们比较了不同编码器结构的性能。如表5所示,我们可以看到C-Encoder和K-Encoder都能在点击预测中取得不错的效果。同时,C-Encoder的性能优于K-Encoder。我们还发现,相对于ESRM-KG(E=K-Encoder)模型,ESRM-KG模型分别在Recall@10,Recall@15和Recall@20方面实现了2.53%,3.03%和3.32%的提高。通过将C-Encoder和K-Encoder结合使用,可以同时提高Recall和MRR。我们认为,K-Encoder在捕获点击项之间的注意力方面表现良好[12]。但是,它缺乏当前会话的全局表示。因此,C-Encoder和K-Encoder的组合可以得到比较好的效果。
表5 不同编码器下点击预测的效果

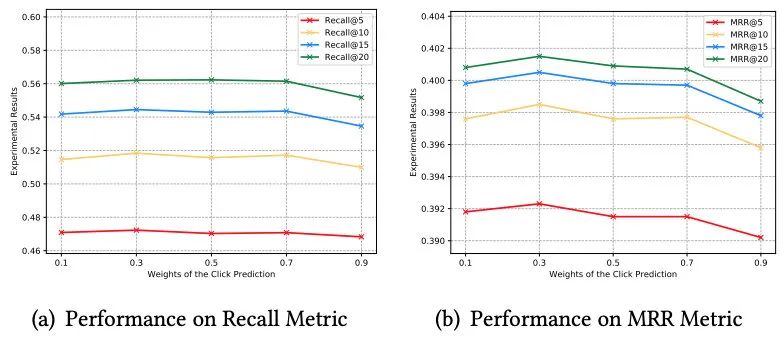
5.3 多任务学习中不同权重对点击预测的影响
RQ3:在多任务学习中,不同权重下的点击预测的性能如何?点击预测的性能会随着多任务学习中的权重的增大而提高吗?
ESRM-KG(W=weight)表示在多任务学习中,点击预测的损失权重是weight。我们探索多任务学习中点击预测损失的不同权重对点击预测的影响。从图15中,我们可以看到:首先,当点击预测的权重为0.9(关键词生成的权重为0.1)时,模型得到的结果最差(无论是在Recall还是MRR上)。我们认为,关键词生成的权重低会导致关键词对当前会话提供的监督无用。其次,就Recall而言,不同的权重(0.9除外)对点击预测结果有轻微的影响。但是,就MRR而言,当权重为0.3时,模型表现最佳。我们推断,当点击预测权重为0.3时,关键词生成可以更好地捕捉会话中用户的需求。因此,目标商品的排名提升了。
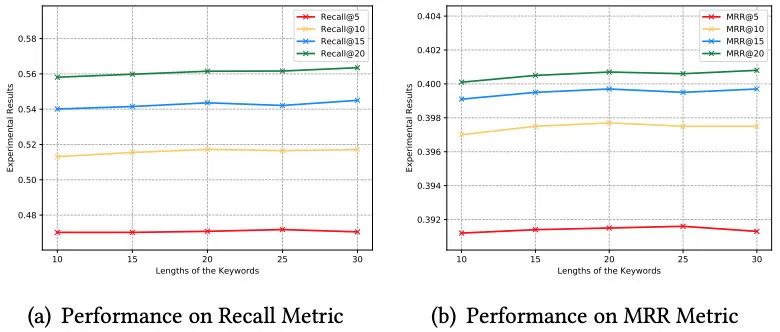
5.4 不同关键词长度对点击预测的影响
RQ4:关键词的长度是否对点击预测的效果有影响?长关键词能否取得更好的效果?
TOP-K表示ESRM-KG(L=top-k)模型。这里的K范围是10、15、20、25和30。如图14所示,就Recall和MRR而言,我们发现TOP-20优于TOP-10和TOP-30。但是,在Recall和MRR上,TOP-10和TOP-15的结果不太好。从这种现象,我们发现,当关键词的长度太小时,它可能会提供不足的信息,这将使关键词生成对推荐的帮助受到很大限制。此外,我们可以看到TOP-30在Recall@15,Recall@20,MRR@15和MRR@20上取得了最佳结果。但是,在Recall@5和MRR@5上,TOP-30不如TOP-25,在Recall@10和MRR@20上不如TOP-20。关于这种现象,我们认为可能导致较长的关键词可能使得ESRM-KG模型倾向于生成关键词。尽管推荐性能在某些方面得到了增强,例如Recall@20,但它也面临目标商品在推荐列表中排名较低的问题。
5.5 生成关键词的质量
RQ5:ESRM-KG生成的关键词的质量如何?
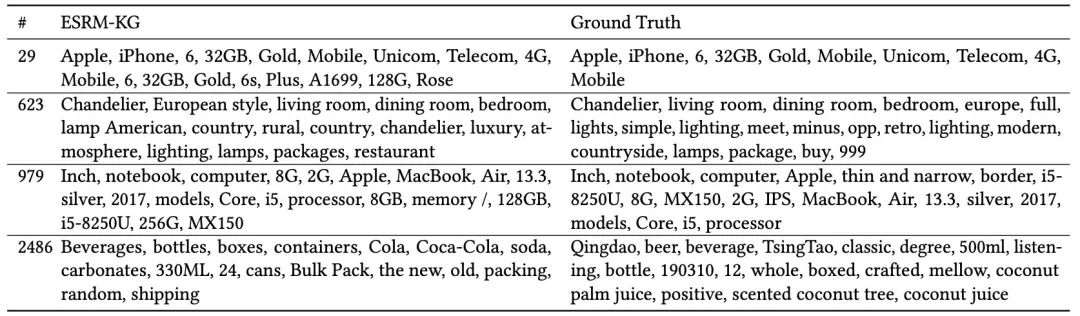
5.6 建议对关键词生成的影响
RQ6:基于会话的推荐是否有助于关键词生成?

ESRM-KG(only Generation)表示ESRM-KG模型删除了点击预测部分。如表7所示,我们发现ESRM-KG(only Generation)模型在所有指标方面都优于ESRM-KG模型。基于这种现象,我们认为基于会话的推荐可能对关键词的生成没有帮助。对于推荐任务,即使预测商品与目标商品非常相似,也仍将被视为负例,受到惩罚。因此,关键词生成可能经常会因基于会话的推荐而遭受“干扰”,性能会下降。
6 结论
在本文中,我们探索了关键词生成对基于电商会话的推荐的影响。我们提出了一种新颖的混合模型,即ESRM-KG,将关键词生成融入到基于会话的推荐中。在大规模的真实世界电商数据集上进行的广泛实验验证了ESRM-KG模型的有效性:首先,我们发现关键词生成在基于电商会话的推荐中显着提高了下次点击预测的效果。然后,我们比较了不同编码器结构的性能。接下来,我们探讨了多任务学习中点击预测损失的不同权重对点击预测的影响。此外,我们还讨论了不同关键词长度的影响。此外,我们还通过样例分析研究了生成的关键词的优缺点。最后,我们探讨了基于会话的推荐对关键词生成的影响。
参考文献
[1] Meizi Zhou, Zhuoye Ding, Jiliang Tang, and Dawei Yin. 2018. Micro behaviors: A new perspective in e-commerce recommender systems. In WSDM. ACM, 727–735.
[2] Dietmar Jannach, Malte Ludewig, and Lukas Lerche. 2017. Session-based item recommendation in e-commerce: on short-term intents, reminders, trends and discounts. User Modeling and User-Adapted Interaction 27, 3-5 (2017), 351–392.
[3] Jing Li, Pengjie Ren, Zhumin Chen, Zhaochun Ren, Tao Lian, and Jun Ma. 2017. Neural attentive session-based recommendation. In CIKM. ACM, 1419–1428.
[4] Maryam Tavakol and Ulf Brefeld. 2014. Factored MDPs for detecting topics of user sessions. In RecSys. ACM, 33–40.
[5] Balázs Hidasi, Alexandros Karatzoglou, Linas Baltrunas, and Domonkos Tikk. 2016. Session-based recommendations with recurrent neural networks. In ICLR.
[6] Qiao Liu, Yifu Zeng, Refuoe Mokhosi, and Haibin Zhang. 2018. STAMP: ShortTerm Attention/Memory Priority Model for Session-based Recommendation. In KDD.
[7] Pengjie Ren, Zhumin Chen, Jing Li, Zhaochun Ren, Jun Ma, and Maarten de Rijke. 2019. RepeatNet: A Repeat Aware Neural Recommendation Machine for Session-based Recommendation. In AAAI.
[8] Yong Kiam Tan, Xinxing Xu, and Yong Liu. 2016. Improved recurrent neural networks for session-based recommendations. In DLRS. ACM, 17–22.
[9] Shu Wu, Yuyuan Tang, Yanqiao Zhu, Liang Wang, Xing Xie, and Tieniu Tan. 2019. Session-based Recommendation with Graph Neural Networks. In AAAI.
[10] Arman Cohan, Franck Dernoncourt, Doo Soon Kim, Trung Bui, Seokhwan Kim, Walter Chang, and Nazli Goharian. 2018. A Discourse-Aware Attention Model for Abstractive Summarization of Long Documents. In NAACL.
[11] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2018. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. CoRR abs/1810.04805 (2018). arXiv:1810.04805 http://arxiv.org/abs/1810.04805
[12] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is All you Need. In NIPS. 5998–6008.
[13] Wanxiang Che, Zhenghua Li, and Ting Liu. 2010. Ltp: A chinese language technology platform. In COLING. 13–16.
[14] Chin-Yew Lin. 2004. ROUGE: a Package for Automatic Evaluation of Summaries. In ACL.







