图像/人脸补全问题的前世今生【附PPT与视频资料】

关注文章公众号
回复"宋林森"获取PPT与视频
视频资料可点击下方阅读原文在线观看
导读
近年来,图像补全问题在应用深度学习技术的条件下已经实现了较好的补全效果,甚至于人眼也难以分辨。故而,该技术也已经成为图像补全问题上的一个研究热点。同时,如何修改对抗生成网络以使其更好的适应图像补全问题来构造更有效的生成模型已经得到了越来越多的关注。人脸补全作为图片补全问题的一个分支,是一种常见的人脸图像编辑技术,它也可以用来编辑人脸属性。生成的人脸图像既可以与原始人脸图像一样精确,也可以与未遮挡人脸图像在内容上保持一致,以使补全的图像看起来具有真实的视觉感受。
作者简介
宋林森,中科院自动化所的一名2018级的研究生,是智能感知与计算研究中心的一员。本科毕业于北京科技大学。目前的主要研究方向为图像补全特别是人脸补全。

正文
1.Introduction
图像补全,即是将图片中缺失的像素补充上, 目的是使得没有看过这原图像的观察者无法察觉出这其实是补全的图像. 有时为了移除图像中的一些物体, 会手动地将这些物体遮挡起来进行补全. 一般来说, 按照补全的难易程度可以将该问题分成两类: (1) 补全较小的区域 —— 细缝, 文字等; (2)补全较大的区域 —— 整块的缺失图片. 如下图所示:

传统的方法通过将信息从缺失位置的外部一步步向缺失区域传播的方法已经可以较好地补全较小的区域, 但是在面对较大的缺失区域时就不灵了, 这时深度学习方法对此类又较大区域缺失的图片补全的较好. 下面介绍几个经典的深度学习的图像补全方法.
2.Method
首先是2016年的Context Encoder[1]方法, 该方法设计了了一个Encoder-Decoder结构的神经网络从遮挡图像的未遮挡部分来推断遮挡部分的信息, 具体的网络结构如下图所示:
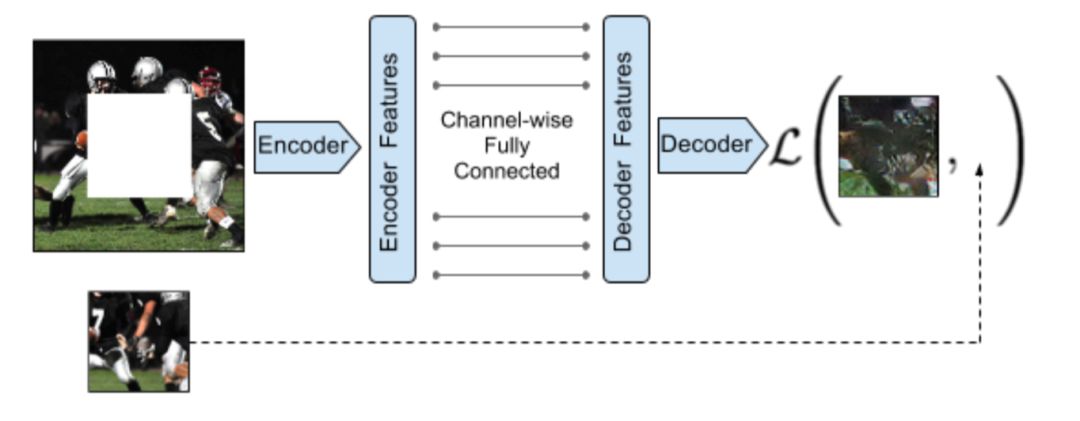
该方法的损失函数的设计包含生成图片真伪性的判别损失以及缺失区域的按像素的重建损失. 该方法生成的图片整体上看生成的效果还可以, 但是仔细观察补全区域就会发现其效果比较差了. 所以人们增加设计了针对补全区域的判别器.
Globally and Locally Consistent ImageCompletion[2]就是增加设计了针对补全区域的判别器的一种网络, 具体的结构如下:
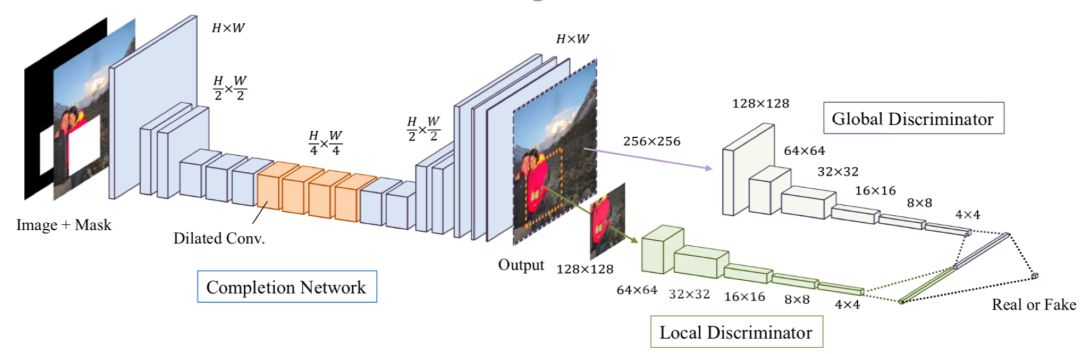
该方法的损失函数包含全局与局部判别损失以及重建损失, 不仅在补全区域的细节方面生成的比较好, 而且还可以通过巧妙地设计损失处理不规则的遮挡区域. 一些效果如下图:

为了更好的利用图片中的冗余信息, 一些利用Attention的方法来增强图像补全效果的方法也相继提出来了. Generative image inpainting with contextual attention[3]就是先利用神经网络补全图片后, 再在未遮挡区域寻找与遮挡区域中相似的图片块, 整体的网络结构如下:
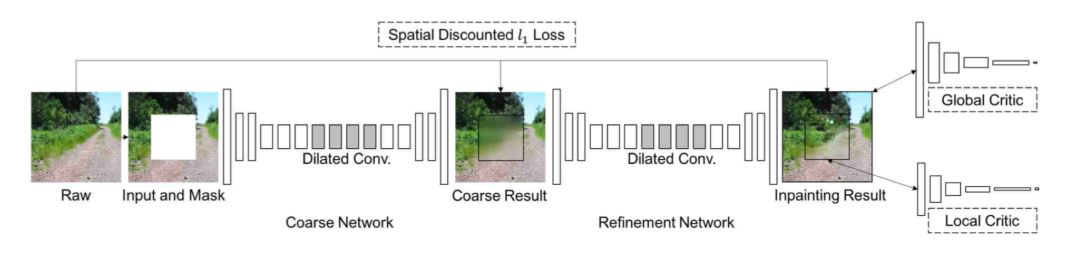
该方法的精髓在于其中的refinement network. 具体的说, 该方法将卷积看成模版匹配过程, 通过foreground(遮挡区域)与background(未遮挡区域)的patch卷积来在background中寻找与foreground的patch相似的patch. 如下图所示
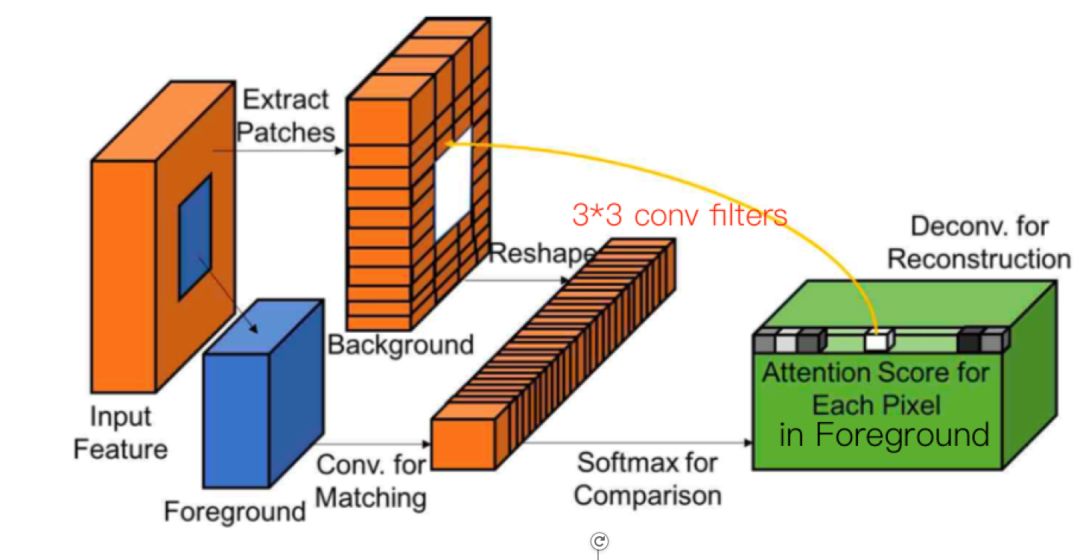
该方法使用卷积的方法计算patch的相似度, 不仅编程变得容易了, 而且利用享有框架计算相似度的时间也减少了.
在使用深度学习方法进行图片补全的时候, 一般将缺失的区域使用白色或者是随机噪声来填充, 再使用卷积层来提取上下文特征以及后续的补全. 白色/随机噪声本来没有有效信息, 对它们与有效的信息不加区别的卷积并不合理, 这样的补全结果会出现一些副作用, 如下图所示:

为了解决这一副作用, Nvidia提出了Partial Convolution[4]通过修改卷积操作来改进图片补全, 具体而言, Partial Convolution的计算公式如下:

式中的W是卷积核, X是一个卷积核上对应的图片内容, M是一个卷积核上的含遮挡信息的Mask矩阵, 元素只含0,1; 右边的m’就是每层更新Mask矩阵的方法. 该方法的一些补全效果如图:

上述的Partial Convolution方法虽然不全效果好, 但是随着网络层数的增加, 器Mask矩阵中的遮挡的部分会越来越萎缩, 到最后每一层的Mask矩阵就认为没有遮挡了, Free-Form Image Inpainting with Gated Convolution[5] 则在此基础上进行了改进, 将Partial Conv方法的Mask更新改为从图片中学习, 并不再将Mask中元素的值固定为0,1而是取自[0,1]. 二者的比较见下图:
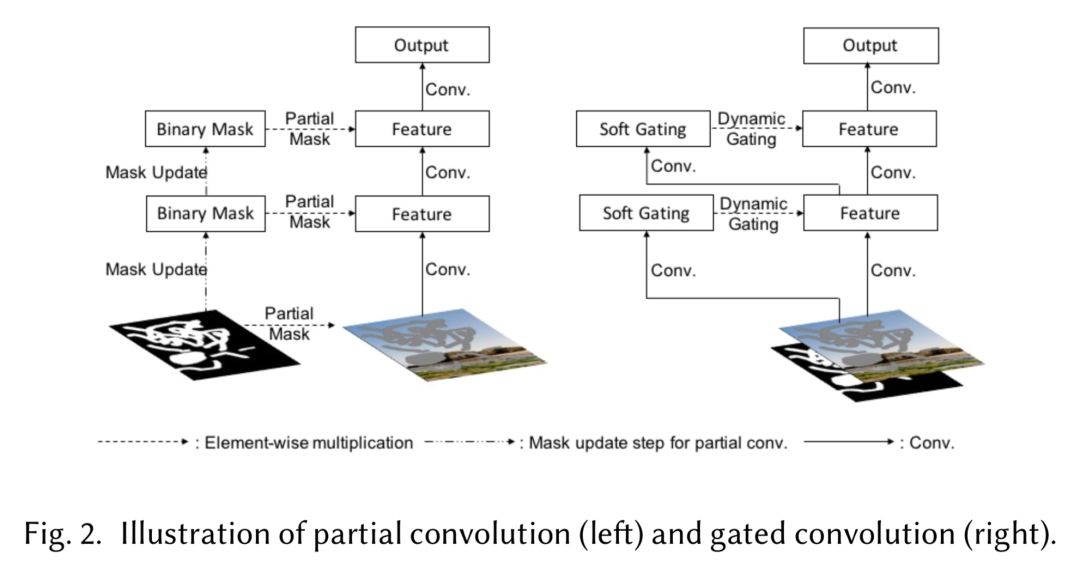
这的一提的是该方法不仅补全的效果好, 还支持user-guided image inpainting. 如下图:

3.Take Home Message
现在的图片补全方法主要以GAN为基础
现阶段热点问题: 高分辨率图片, 复杂不规则遮挡的补全
4.Reference
[1] Pathak, Deepak, et al.2016. Context encoders: Feature learning by inpainting. In CVPR
[2] Iizuka, Satoshi, EdgarSimo-Serra, and Hiroshi Ishikawa. 2017. Globally and locally consistent imagecompletion. In SIGGRAPH
[3] Yu, Jiahui, et al.2018. Generative image inpainting with contextual attention. In CVPR
[4] Liu, Guilin, et al.2018. Image inpainting for irregular holes using partial convolutions. In ECCV.
[5] Yu Jiahui et al. 2018.Free-Form Image Inpainting with Gated Convolution. arXiv preprintarXiv:1806.03589
SFFAI讲者招募
为了满足人工智能不同领域研究者相互交流、彼此启发的需求,我们发起了SFFAI这个公益活动。SFFAI每周举行一期线下活动,邀请一线科研人员分享、讨论人工智能各个领域的前沿思想和最新成果,使专注于各个细分领域的研究者开拓视野、触类旁通。
SFFAI目前主要关注机器学习、计算机视觉、自然语言处理等各个人工智能垂直领域及交叉领域的前沿进展,将对线下讨论的内容进行线上传播,使后来者少踩坑,也为讲者塑造个人影响力。
SFFAI还将构建人工智能领域的知识树(AI Knowledge Tree),通过汇总各位参与者贡献的领域知识,沉淀线下分享的前沿精华,使AI Knowledge Tree枝繁叶茂,为人工智能社区做出贡献。
这项意义非凡的社区工作正在稳步向前,衷心期待和感谢您的支持与奉献!
有意加入者请与我们联系:wangxl@mustedu.cn

历史文章推荐:


