2019年深度学习自然语言处理最新十大发展趋势(附下载报告)

本文介绍了近日FloydHub 博客上Cathal Horan中自然语言处理的10大发展趋势。


-
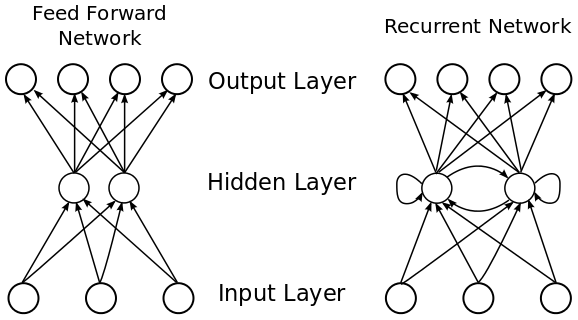
每个词只能嵌入一个词,即每个词只能存储一个向量。 所以" bank "只有一个意思"我把钱存进了银行"和"河岸上有一条漂亮的长凳"; -
它们很难在大型数据集上训练; -
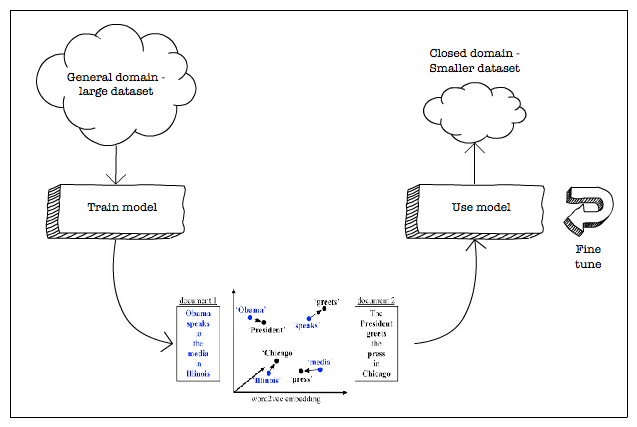
你无法调整它们。 为了使他们适合你的领域,你需要从零开始训练他们; -
它们不是真正的深度神经网络。 他们被训练在一个有一个隐藏层的神经网络上。
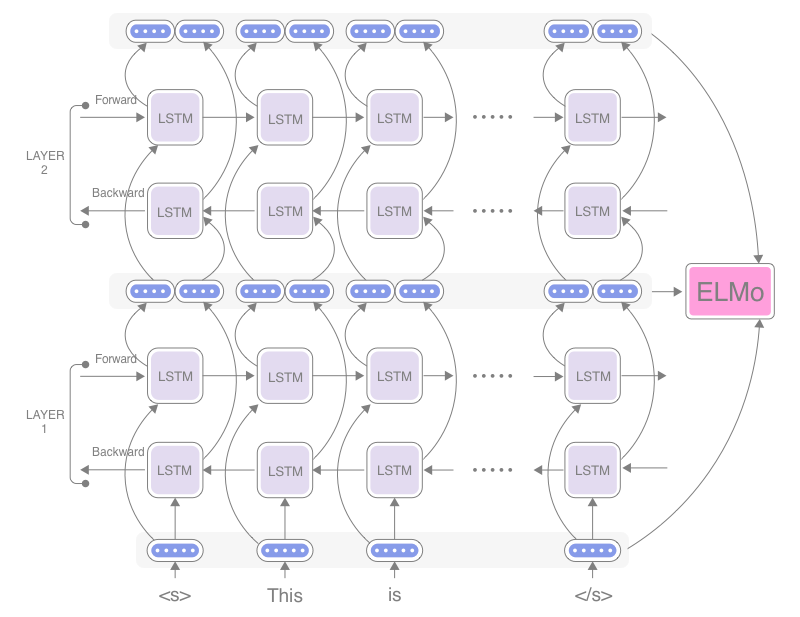
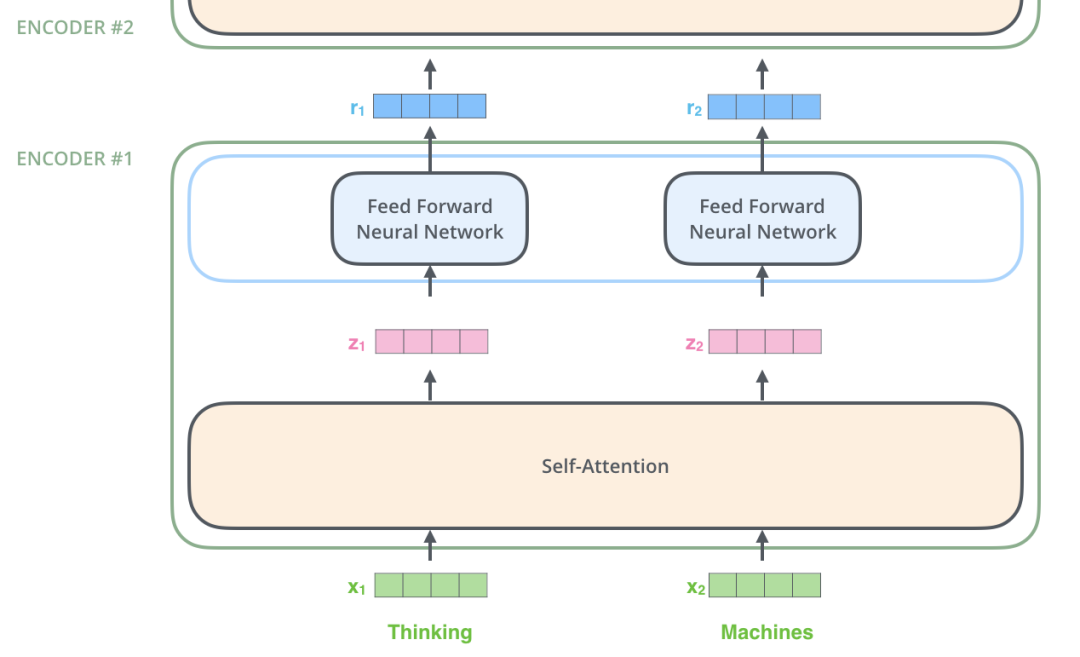



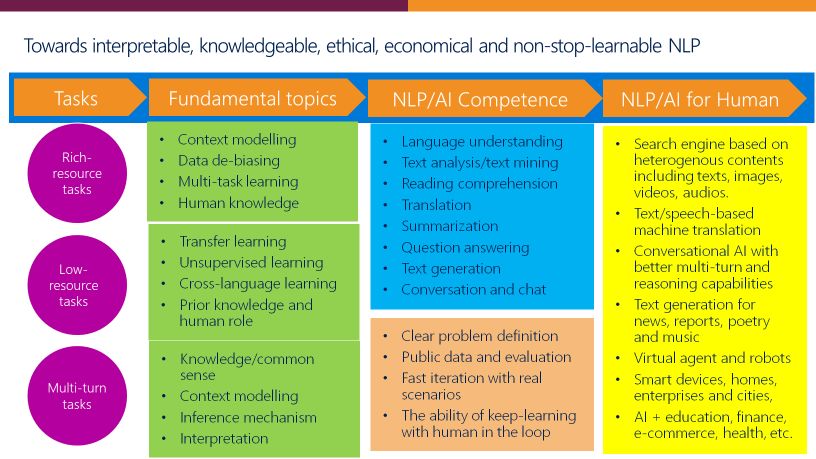

登录查看更多
相关内容

专知会员服务
140+阅读 · 2020年7月10日
Arxiv
6+阅读 · 2018年6月14日
Arxiv
6+阅读 · 2018年2月20日





相关VIP内容
专知会员服务
140+阅读 · 2020年7月10日
相关资讯
相关论文
Arxiv
6+阅读 · 2018年6月14日
Arxiv
6+阅读 · 2018年2月20日