Facebook工程师教你什么是随机森林,就算零基础也可以看懂 | 干货
白交 发自 凹非寺
量子位 报道 | 公众号 QbitAI
今天的这篇入门贴,我们就来介绍一下决策树与随机森林。
这篇帖子适合机器学习基础为0的同学~
当然,有基础的同学也可以来看一下,加深一下理解哈!
作者还是此前介绍过的普林斯顿大学毕业,现为Facebook工程师——Victor Zhou。
决策树
在介绍随机森林之前,先来介绍一下决策树。
简单来说,一堆决策树捆绑在一起,就组成了一个随机森林。
我们先来看一组数据集。
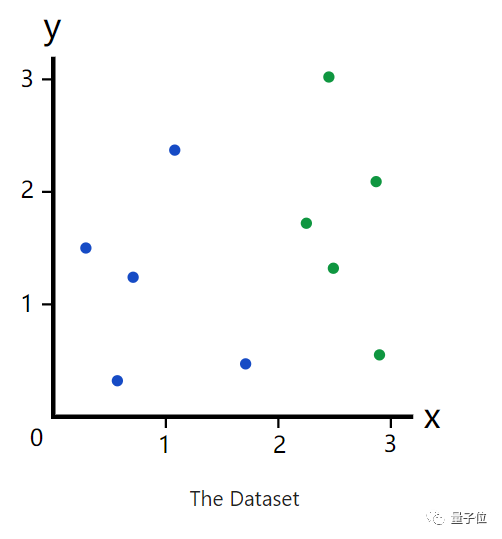
如果给你一个随机的横坐标x,你会觉得是什么颜色的点?
蓝色?绿色?如果你说了其中一个,那你一定是在逗我。
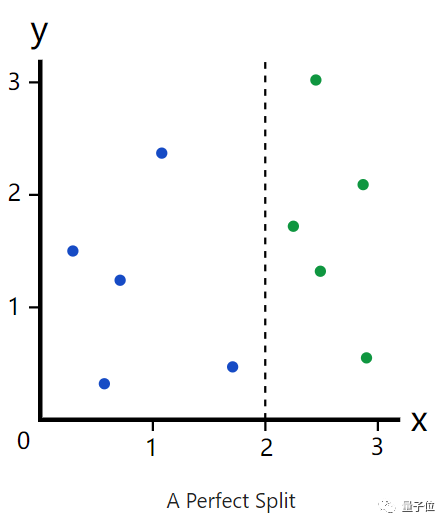
我们看这个图,x=2的这条线似乎成了一个分割线。于是合理怀疑,当x<2的时候,是蓝色,当x>2的时候,为绿色。
那么刚才,你就相当于评估了一个决策树。
决策树就是在给定的数据集的情况下,对新样本进行分类。
而图中已有的蓝色和绿色标记点就相当于我们的数据集,而随机的x,就是新样本,我们正在做的,就是在给新样本进行分类。
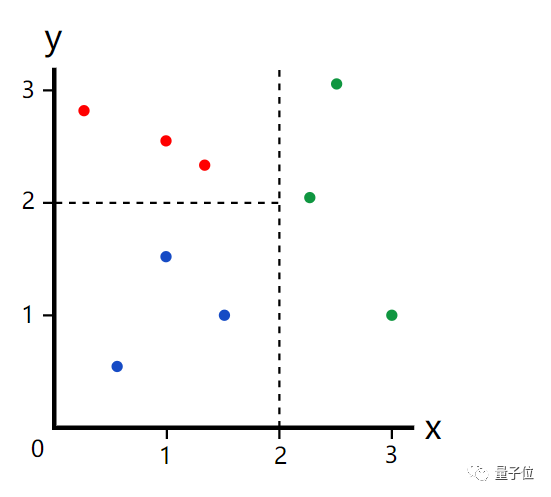
而如果在数据集中添加了一种颜色——红色。
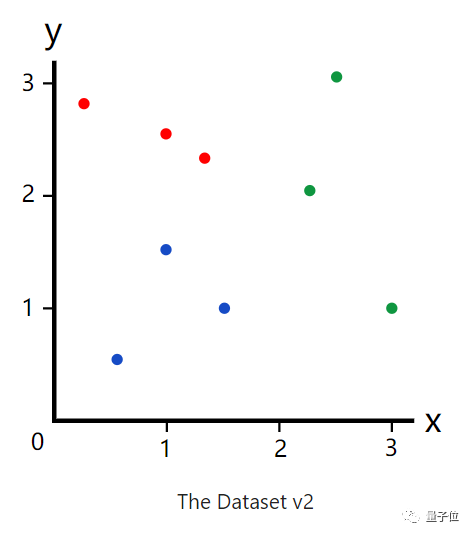
如果我们再按照那种方式分类,结果就会出现误差。在x<2的时候,就无法立即将其分为蓝色或者红色。
于是,就会出现另一个决策点。设定一个y,当y<2时,就为蓝色,反之,就为红色。
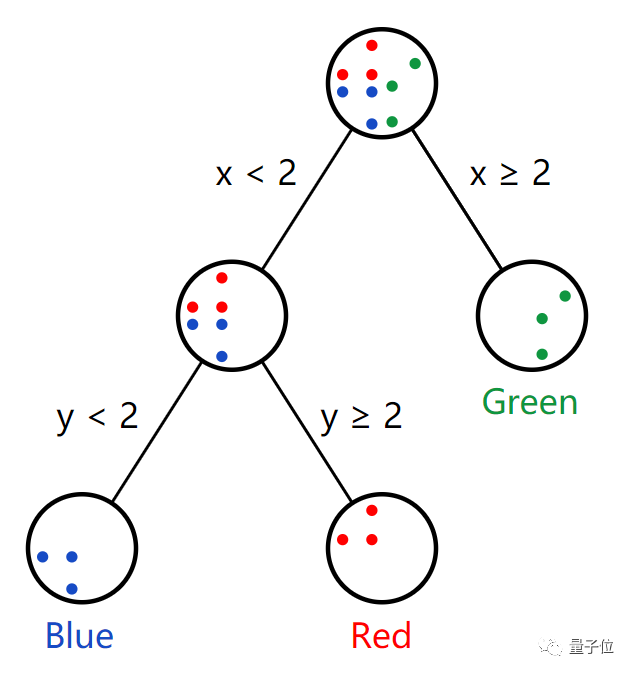
将其分为三类。
这就是决策树背后的基本思想。
怎么样,很简单对吧?接下来,我们就来训练决策树。
训练决策树——确定根节点
将使用上述的包含3类——红绿蓝的数据集。
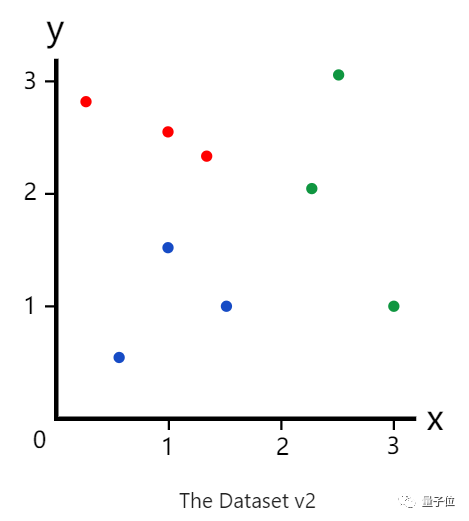
训练决策树的首要任务确定树中的根决策节点。这里有x,y,你可以设定任意一个阈值。
那么我们就设定x阈值(临界值)为2。
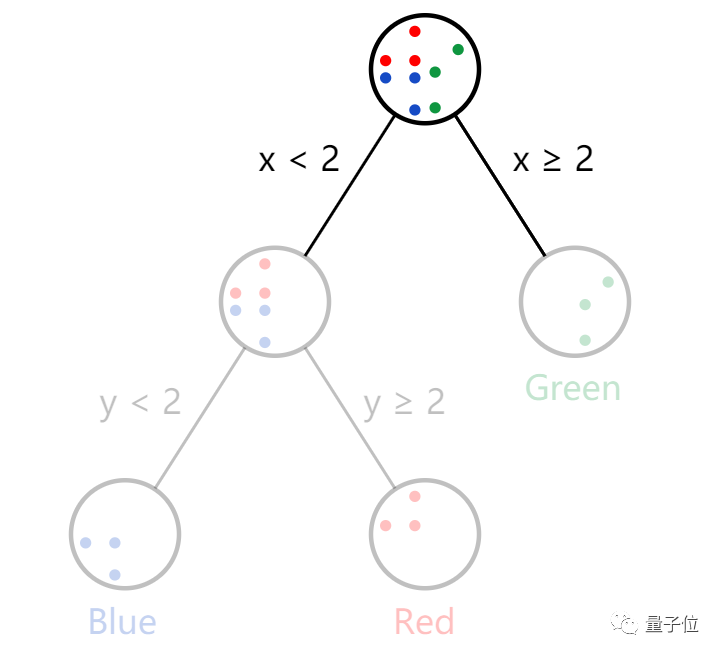
根据结果来看,我们这一个根节点做出了较好的分割,已经尽可能的将不同种类分开来。
绿色的都在右边,不是绿色的都在左边。
但是,我们的目标是找到一个根节点,做到最好的拆分。而如果量化拆分的是否最好,就需要引入一个基尼杂质的概念。
基尼杂质
就按照上述两种颜色——绿蓝来说,若以x=2为分割,那么就将数据集完美的分为两个分支。
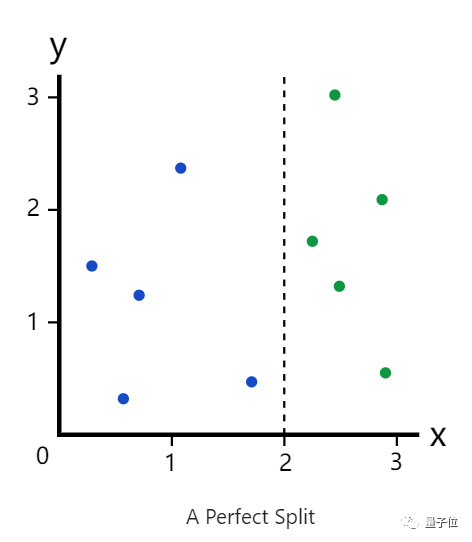

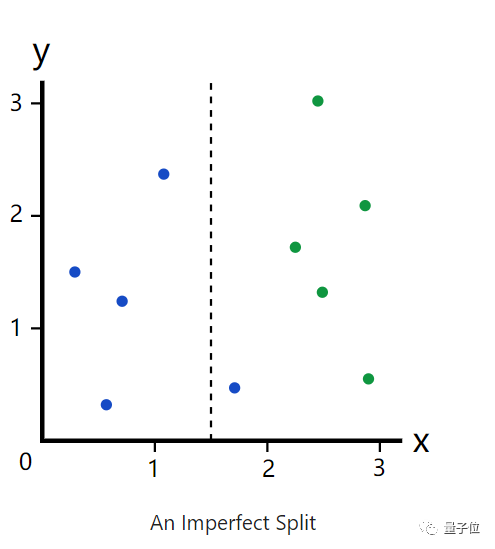
但若是以x=1.5呢?分割就不会那么完美了。
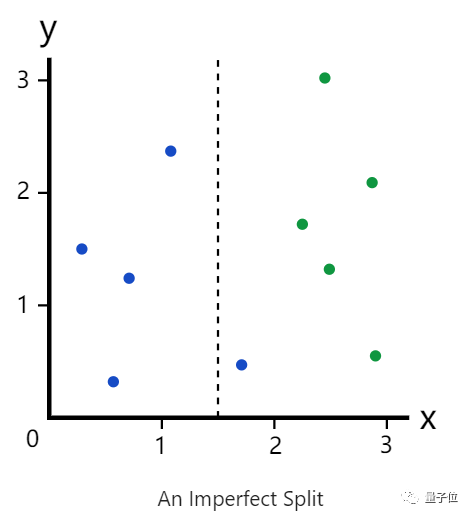

那如果我们对数据点进行了错误的分类(就如上图那个蓝色),发生这种错误的可能性,就是基尼杂质。
我们来举个例子,以上述那个整个数据集为例,计算一下基尼杂质。那么对数据点的判断主要有以下四种。
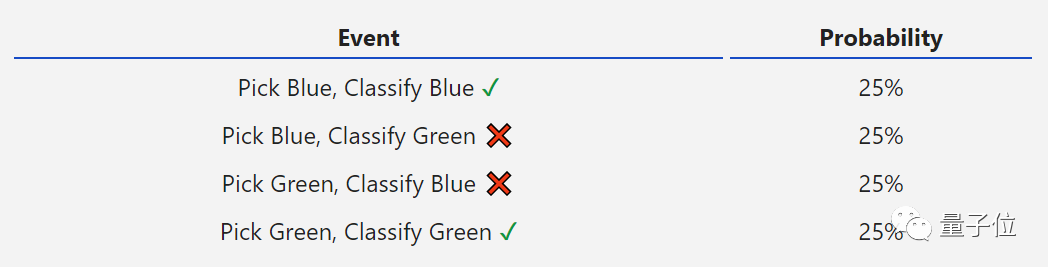
那么其中错误的可能性:25%+25%,所以基尼杂质是0.5。
用公式来表示:
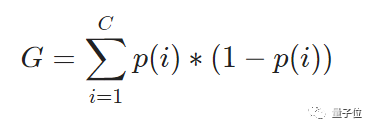
其中G为基尼杂质,C为种类数。
上述例子,就可表示为:
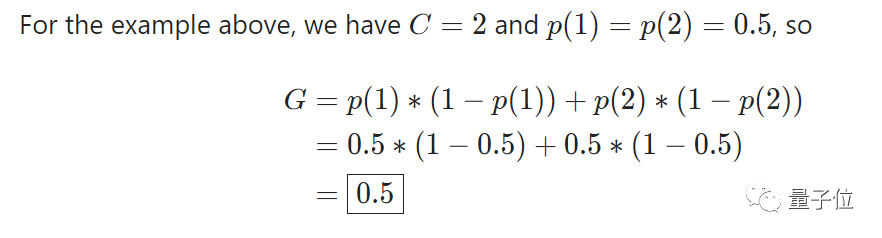
试想,如果以完美拆分的数据集为例。
那么左右分支,基尼杂质都为0。
再以一个不怎么完美的分割为例。
那么左分支,基尼杂质为0。
右分支,计算结果如下:
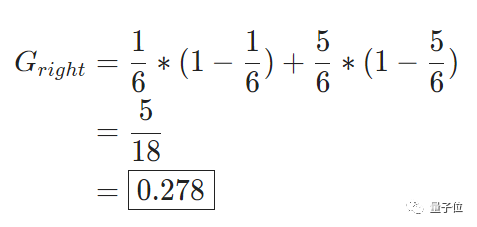
然后在按照每个分支的杂质数量加权,来计算拆分的质量。
这里的左分支有4个元素,右分支有6个元素,那么左边权重为0.4,右边权重为0.6。
那么其拆分质量:0.4*0+0.6*0.278=0.167
我们通过拆分“去除”掉的杂质量为:0.5-0.167=0.333(0.5为整个数据集的基尼杂质)
这个值就称为基尼增益。
我们知道,完美切割的基尼增益为0.5。可见,基尼增益越大,那就说明拆分的越好。
基尼增益
知道什么是基尼杂质、基尼增益之后,我们就来实际算一下以三种颜色的数据集。
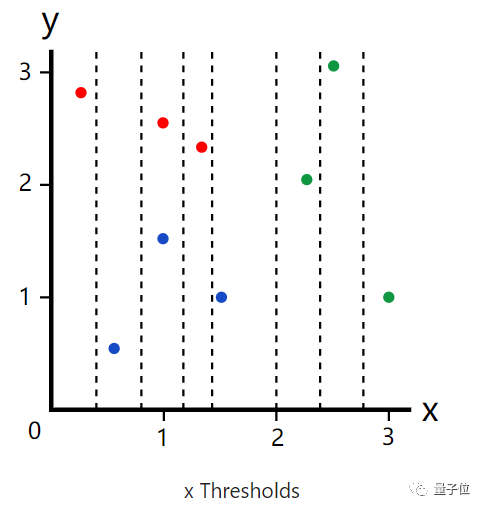
我们如果设定x阈值为0.4,那么就有如下分类。

整个数据集的基尼杂质:
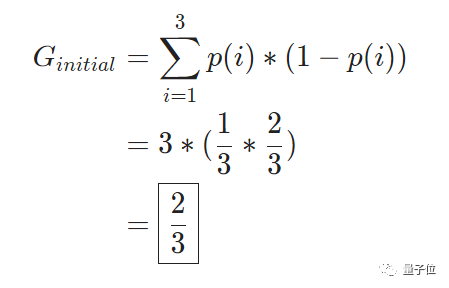
两个分支的基尼杂质:
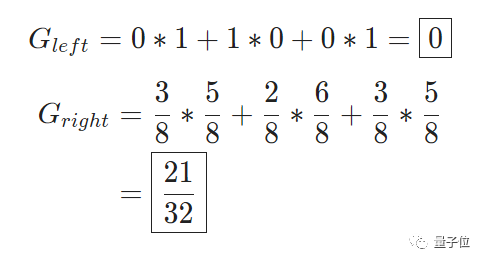
基尼增益:
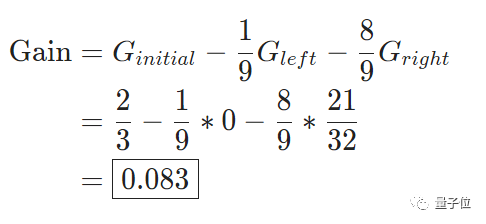
于是,当x取任意可能的阈值时,其基尼增益都可以算出来。结果如下:
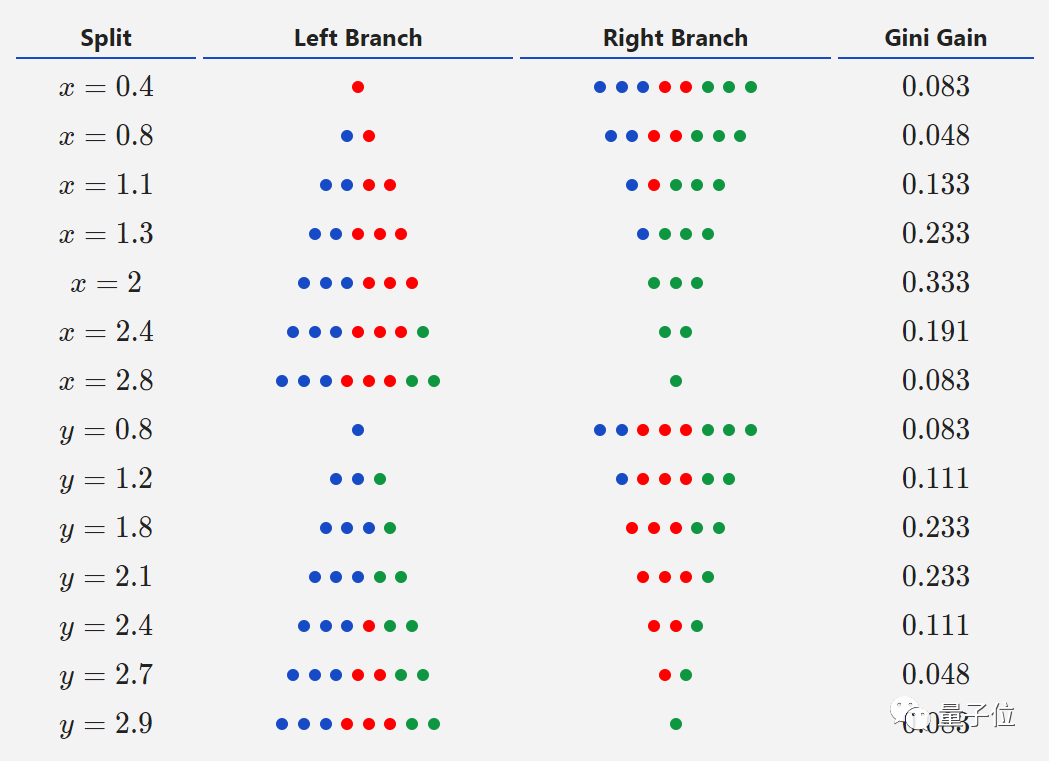
那么从表格中看出,当x=2时,其基尼增益最大,说明此时分割效果最好。
训练决策树——确定第二个节点
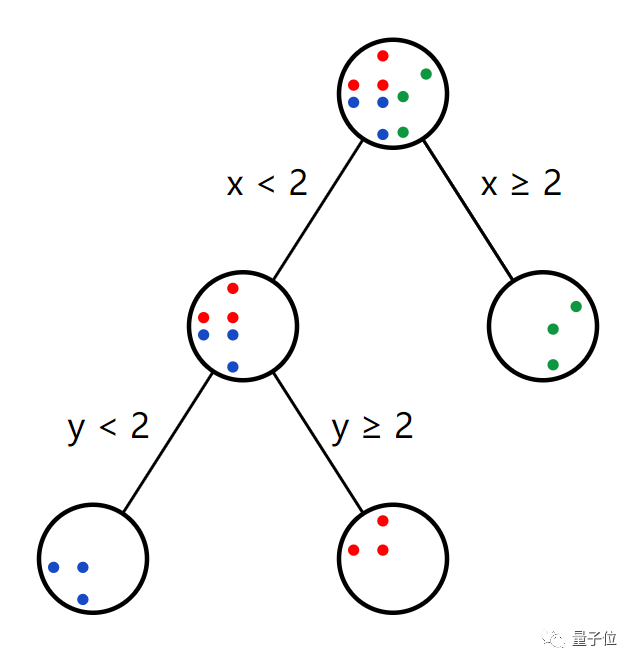
确定根节点之后,我们就马不停蹄的来确定第二个节点啦~
很明显,我们只需要在意左侧分支,然后做同样的事情。
可以意识到,y=2可以实现最好的分割。
这样看来,似乎快要完成了。别着急,还有一步。
如果我们在试着建立第三个决策节点,尝试在右边分支寻找到最好的分割。
但是发现,所有的分割结果都是相同的,基尼杂质为0,基尼增益也为0,说明效果都是相同的。
说明在右侧分支确定节点是没有意义的(但是这个步骤还是很有必要的)。
因此,我们将这个节点称为叶子节点,并将其贴上绿色标签,所有到达这个节点的数据点都贴上绿色的标签。
其余两种颜色同样如此。
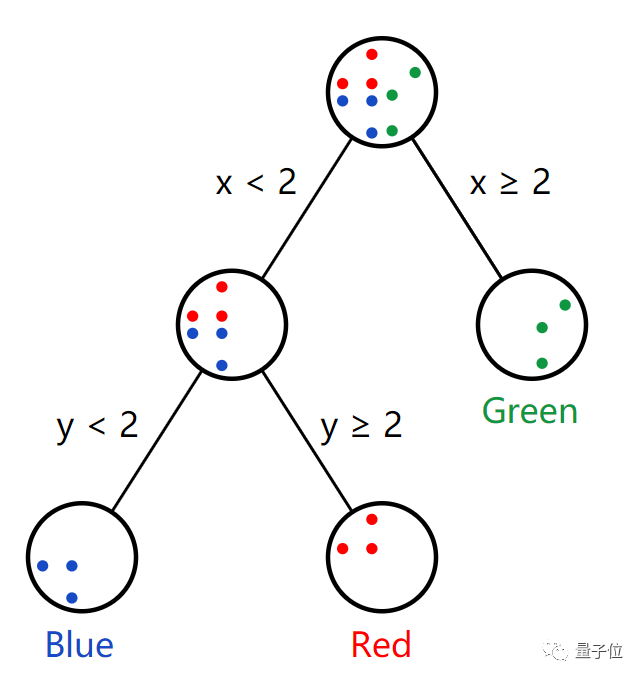
这样,我们就完成了对决策树的训练!
随机森林
前面提到,随机森林就是一群捆绑着的决策树。
这句话说对也对,但是实际上还是有一些区别。
理解随机森林,我们要先理解Bagging。
Bagging(bootstrap aggregating)
什么叫做Bagging?接下来的算法告诉你。
从数据集中均匀、有放回的抽取n个训练数据点,进行替换;
利用n个样本,训练决策树;
重复t次(t也就为决策树的数量)。
随后将各个决策树的预测结果汇总。
如果我们的树是按照类标签(比如颜色),则采用投票的方式,票数多的就是最优选择。
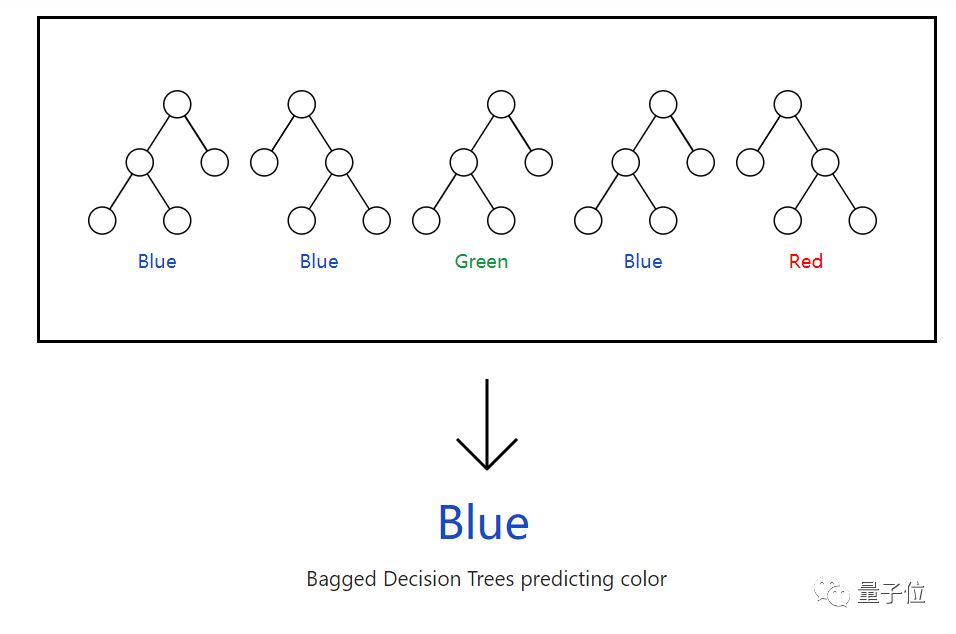
如果我们的树是产生数值(比如预测温度、价格等),则取平均数。
随机森林
Bagged决策树只要一个参数,那就是t——树的数量。
而随机森林则还需要第2个参数,这个参数控制着最佳分割需要的特征数量。
比如,上述例子中,我们只有两个特征x与y,就可以实现最佳分割。
但是真实的数据集要比这个复杂的多,特征也就更多,甚至上千个。
假设我们有一个具有p特征的数据集。每当我们做一个新的决策节点时,就不尝试所有的特征,而是只尝试其中的一个子集。
这样做,就可以为其注入随机性,使单个树变得更加独特,减少树之间的相关性,从而提高森林的整体性能。
好了,随机森林就介绍到这里。详细介绍可戳下方链接~
https://victorzhou.com/blog/intro-to-random-forests/
— 完 —
本文系网易新闻•网易号特色内容激励计划签约账号【量子位】原创内容,未经账号授权,禁止随意转载。
报名 |「隐私计算+AI」技术直播
不了解任何隐私AI技术的情况下,开发者怎样做到只改动两三行代码,就将现有AI代码转换为具备数据隐私保护功能的程序?


量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态
喜欢就点「在看」吧 !




