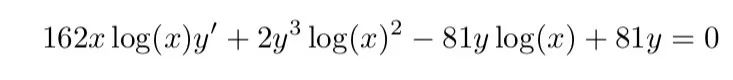![]()
距离用深度学习技术求解符号数学推理问题,或许只差一个恰当的表示和恰当的数据集。
近日,Facebook AI研究院的Guillaume Lample 和Francois Charton两人在arxiv上发表了一篇论文,标题为《Deep Learning for Symbolic Mathematics》。
论文地址:https://arxiv.org/abs/1912.01412
这篇论文提出了一种新的
基于seq2seq的方法来求解符号数学问题
,例如函数积分、一阶常微分方程、二阶常微分方程等复杂问题。
其结果表明,这种模型的性能要远超现在常用的能进行符号运算的工具,例如Mathematica、Matlab、Maple等。
有例为证:
上图左侧几个微分方程,Mathematica和Matlab都求解失败,而作者所提的模型却能够获得右侧的正确结果(这不是个案,而是普遍现象,具体可见后文)。
更有意思的是,这还并不仅仅是它的唯一好处。
由于seq2seq模型的特点,作者所提方法能够对同一个公式得出不止一个的运算结果
,例如如下的微分方程
可以验证一下,这些结果都是正确的,至多差一个常数 c。
我们来看下这样美好的结果,作者是如何做到的。(其实很简单!)
首先需要强调,在过往中,机器学习(包括神经网络)是一种统计学习方法,这些方法被证明在统计模式识别方面非常有效,例如在CV、NLP、语音识别等问题上均已经达到了超过人类的性能。
但机器学习(这里特别强调是神经网络)却不适合去解决符号推理问题,目前仅有少数这样的工作,但主要集中在解决基本的算术任务(例如加法和乘法)上,且实验上证明在这些问题上,神经网络的方法往往表现不佳,需要引入一些已有的指向任务的组件才勉强可行。
相比于以往的各种方法,作者思想独特,
他们认为数学符号计算的过程本质上就是一个模式识别的过程。由此他们将数学(尤其是符号计算)视为一个 NLP 模型问题,符号推理等同于seq2seq的「机器翻译」过程。(真是“机器翻译”解决一切啊)
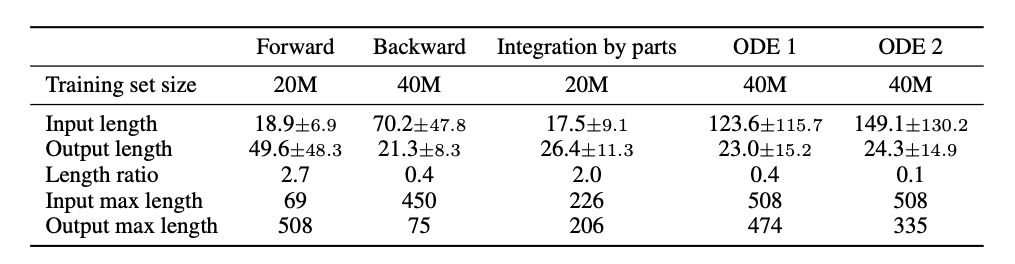
具体来讲,作者在文章中主要针对函数积分和常微分方程(ODE)进行研究。
学过高等数学的我们都有过求积分和解微分方程的痛苦经历,对计算机软件来讲,求解这些问题事实上也同样困难。以函数积分为例,人类在求解过程中主要是依赖一些规则(例如基本函数的积分公式、换元积分、部分积分等);而传统的计算机代数系统则主要是通过从大量具体的案例中进行搜索,例如对用于函数积分的Risch算法的完整描述就超过了100页。
但,回过头,我们思考,
从本质上来讲,求积分的过程不正是一个模式识别的过程吗?当给你一个公式yy′(y^2 + 1)^{−1/2},你会从脑海中牢牢记住的数十、数百个积分模型中寻找出「模式」最为匹配的结果\sqrt{y^2 + 1}。
基于这种思路,作者首先提出了将数学表达式转换为seq2seq表示形式的方法,并用多种策略生成了用于监督学习的数据集(积分、一阶和二阶微分方程),然后将seq2seq模型用于这些数据集,便得出了比最新计算机代数程序Matlab、Mathematica等更好的性能。
作者将数学问题视作自然语言处理的问题,因此首要一步便是将数学公式转化为NLP模型能够处理的形式,即序列(seq)。
![]()
运算符和函数(例如cos、pow等)为内部节点,数字、常数和变量为叶。可以看出这里每一个数学公式都对应唯一一个树结构。
-
-
这里x/0、log(0)等在数学中认为是无效的函数表达式在这里并不会排除在外;
由于树和表达式之间存在一一对应的关系,因此表达式之间的相等性,将反映在它们相关的树上。作为等价关系,由于 2 + 3 = 5 = 12-7 = 1×5,所以这对应于这些表达式的四棵树是等价的。
形式数学的许多问题都可以重组为对表达式或树的运算。例如,表达式简化等于找到树的较短等效表示。
在这篇文章中,作者考虑两个问题:
符号积分和微分方程
。两者都可以归结为将一个表达式转换为另一个表达式。例如在函数积分中,将 cos(x) 的树映射到其解 sin(x)+c 的树。这本质上就是机器翻译的一个特殊实例,而已。
这很显然,机器翻译模型运行在序列(seq)。针对这一步,学过计算机的同学应该都不陌生,作者选用了
前缀表示法
,从左到右,将每个节点写在其子节点前面。例如 2 + 3×(5+2),表示为序列为 [+ 2 * 3 + 5 2]。这里,在序列内部,运算符、函数或变量由特定的标记表示。就像在表达式和树之间的情况一样,树和前缀序列之间也存在一对一的映射。
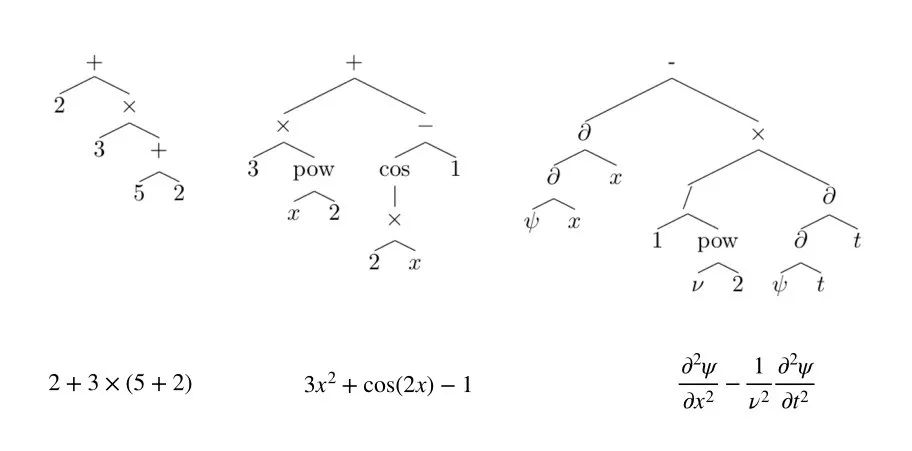
当有了合适的表示之后,另一个重要的事情便是如何生成恰当的数据集。作者采用生成随机表达式的算法(具体这里不再赘述),如果用p1表示一元运算子(例如cos、sin、exp、log等)的集合,p2表示二元运算子(例如+、-、×、÷等)的集合,L表示变量、常数、整数的集合,n 为一棵树的内部节点个数(因此也是表达式中运算子的个数)。可以计算,表达式的个数与n之间有如下关系:
![]()
要训练网络模型,就需要有(问题,解决方案)对的数据集。理想情况下,我们应该生成问题空间的代表性样本,即随机生成要积分的函数和要求解的微分方程。但我们知道,并不是所有的函数都能够积分(例如f=exp(x^2)和f=log(log(x)))。为了生成大型的训练集,作者提出了一些技巧。
在这里我们以积分为例(ODE-1 和ODE-2 数据集的生成方法这里不再赘述,可参见论文)。作者提出了三种方法:
Forward generation(FWD)。
给定n 个运算子的表达式,
通过计算机代数系统求解出该表达式的积分
;如果不能求解,则将该表达式丢弃。显然这种方式获得的数据集只是问题空间的一个子集,也即只包含符号框架可以求解的函数积分;且求积分的过程往往是非常耗时的。
Backward generation(BWD)。
求微分是容易的。因此我们可以
先随机生成积分表达式f,然后再对其进行微分得到 f'
,将(f,f')添加到数据集当中。这种方法不会依赖于符号积分系统。这种方法生成的数据集也有一定的问题:1)数据集中简单积分函数的数量很少,例如 f=x^3 sin(x),其对应的积分式微F=-x^3 cos(x) + 3x^2sin(x) + 6x cos(x) - 6 sin(x),这是一个有15个运算子的表达式,随机生成的概率相对来说会小一些;2)表达式的微分往往会比表达式本身更长,因此在BWD方式所生成的数据集中,积分(问题的解)倾向短于积分函数(问题)。
Backward generation withintegration by parts(IBP)。
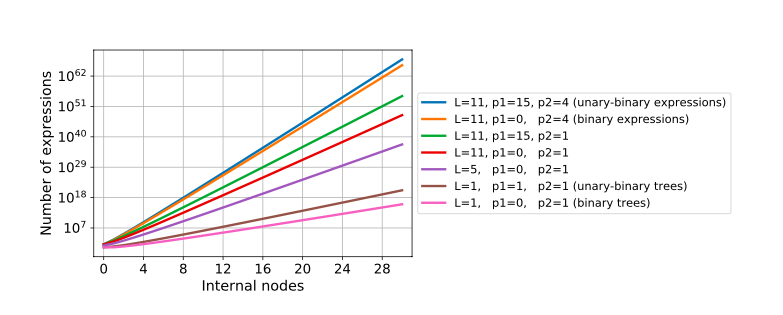
为了克服BWD所存在的问题,作者提出IBP的方法,即
利用分部积分
![]()
随机生成两个函数F和G,如果已知fG和它的积分式已经在数据集当中,那么就可以求解出Fg的积分式,然后把Fg和它的积分式放入数据集。反之也可以求解 fG 的积分式。如果fG和Fg都不在数据集中,那么可以按照BWD的方式求解FG 对应的微分fg。不断迭代,从而获得数据集。
![]()
这里假设了 n= 15,L ={x} ∪ {-5, ... , 5} \ {0}, p2={+,-, ×, ÷}, p1= {exp, lgo, sqrt, sin, cos, tan, sin-1, cos-1, tan-1, sinh, cosh,tanh, sinh-1, cosh-1, tanh-1}。
可以看出
FWD和 IBP 倾向于生成输出比输入更长的样本,而 BWD 方法则生成较短的输出。
与 BWD 情况一样,ODE 生成器倾向于生成比其方程式短得多的解。
补充一点,生成过程中清洗数据也非常重要。这包括几个方面:
1)方程简化。例如将 x+1+1+1+1 简化为x +4
2)系数简化。例如x + x tan(3) + cx +1 简化为 cx +1
这篇文章中所使用的模型比较简单,就是一个seq2seq的模型,当给定一个问题的表达式(seq),来预测其对应的解的表达式(seq)。
具体来说,
作者使用了一个transformer模型,有 8 个注意力头,6层,512维。
(在这个案例中,大的模型并不能提高性能)
在训练中,作者使用了Adam优化器,学习率为10E-4。对于超过512个token的表达式,直接丢弃;每批使用256个表达式对进行训练。
在推断过程中,作者使用了带有early stopping的beam搜索方法来生成表达式,并通过序列长度来归一化beam中假设的对数似然分数。
注意一点,在生成过程中没有任何约束,因此会生成一些无效的前缀表达式,例如[+ 2 * 3]。这很好解决,直接丢弃就行了,并不会影响最终结果。
在机器翻译中,一般采用对人工翻译进行对比的BLEU分数作为指标来评价翻译质量,但许多研究表明,更好的BLEU分数并不一定与更好的表现有关。不过对求解积分(或微分方程)来说,评估则相对比较简单,
只要将生成的表达式与其参考解进行简单比较,就可以验证结果的正确性了
。例如微分方程xy′ − y + x =0的参考解为 x log(c/ x) ,模型生成的解为 x log(c) − x log(x),显然这是两个等价的方程。
由于对表达式是否正确可以很容易地进行验证,因此作者提出如果生成的beam中的表达式中,
只要有一个正确,则表示模型成功解决了输入方程
(而不是只选用得分最高的)。例如当 beam =10时,也即生成 10 个可能的解,只要有一个正确即表明模型成功输出结果正确。
![]()
1)在积分中即使让beam=1,模型的准确性也是很高的。
2)beam=1时,ODE结果并不太理想。不过当beam尺寸增大时,结果会有非常显著的提升。原因很简单,beam大了,可供挑选的选项也就多了,正确率自然会提高。
![]()
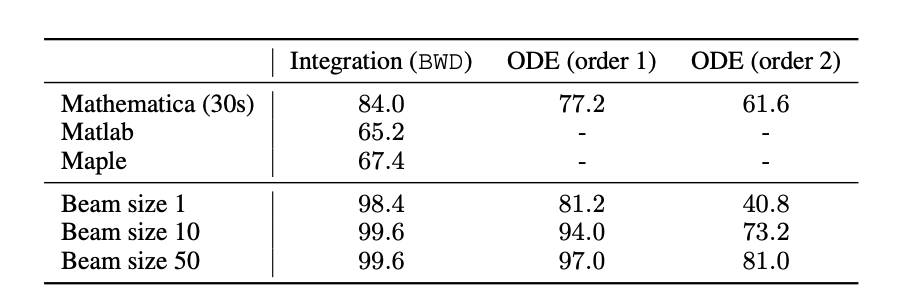
这个表格显示了包含 500 个方程的测试集上,本文模型与Mathematica、Matlab、Maple三大著名数学软件的比较。对于Mathematica,假设了当时间超过30s而未获得解则认为失败(更多时延的对比可见论文原文附录)。对于给定的方程式,本文的模型通常会在不到 1 秒的时间里找到解决方案。
从正确率上可以看出,
本文方法要远远优于三大著名数学软件的结果。
这种方法最有意思的地方出现了。通常你用符号求解软件,只能得到一个结果。
但这种seq2seq 的方法却能够同时给你呈现一系列结果,它们完全等价,只是用了不同的表示方式。
具体案例,我们前面已经提到过,这里不再赘述。
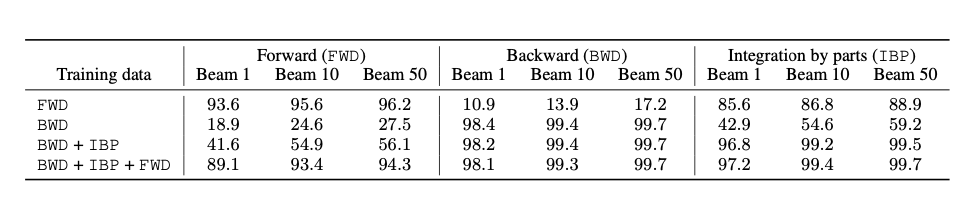
在前面提到的实验结果中,测试集与训练集都来自同一种生成方法。但我们知道每一种生成方法都只是问题空间的一个子集。那么当跨子集测试时会出现什么现象呢?
![]()
1)当用FWD数据集训练,用BWD数据集进行测试,分数会极低;不过好在用IBP数据集测试,分数还行;
2)同样的情况,当用BWD数据集训练,用FWD数据集进行测试,结果也很差;意外的是,用IBP数据集测试,结果也不理想;
3)当把三个数据集结合在一起共同作为训练集时,测试结果都还不错。
1)
FWD数据集和BWD数据集之间的交集真的是非常小
;
2)
数据集直接影响模型的普适性,因此如何生成更具代表性的数据集,是这种方法未来一个重要的研究内容。
1、本文提出了一种新颖的、利用seq2seq模型求解符号数学推理的方法,这种方法是普遍的,而非特定模型;
3、
完全可以将类似的神经组件,内嵌到标准的数学框架(例如现在的3M:Mathematica、Matlab、Maple)的求解器当中,这会大大提升它们的性能
。
锁定AI研习社,AI社区独家直播
![]()
![]() 点击 阅读原文,直达本次直播!
点击 阅读原文,直达本次直播!