来源:Stanford
编辑:LRS
【新智元导读】斯坦福基础模型研究中心仅仅成立两个月就站在了风口浪尖上,各个领域的学者都对基础模型的研究产生质疑,这究竟是「真理」还是斯坦福的一步「臭棋」,只能交给时间去检验。最近实验室的主任华人Percy Liang发了一篇文章回应,基础模型只是研究的第一步,他的目标是更美好的未来。
八月,斯坦福大学的研究人员在arxiv上传了一篇报告,宣布人工智能的新时代已经到来,一个建立在巨大的神经网络和数据海洋之上的时代。
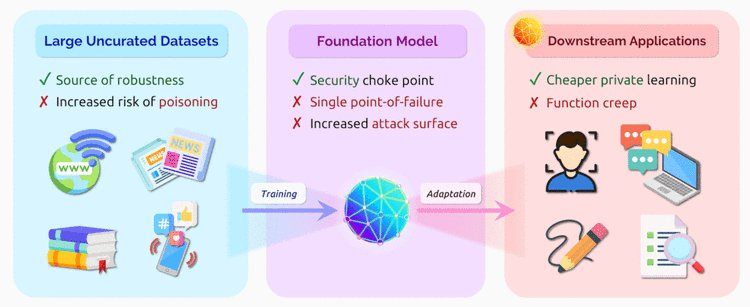
依托于超大规模的预训练模型,例如,BERT、DALL-e、GPT-3,各种下游任务的性能都得到了飞速的发展。这类模型斯坦福也将其称为「基础模型」,即这些模型是不完整的,但它对于落地应用来说是必不可少的。
在论文中,斯坦福还宣称将建立一个基础模型研究中心CRFM(Center for Research on Foundation Models),主要研究和开发这类基础模型。
这篇论文一出,顿时引起了社会各界的反对声音,有学者认为这类研究是“骗经费的“,还有人认为“深度学习不值得”。学术界的主要观点似乎是深度学习确实很好用,但是浪费如此大的资源来研究,实在是一件不划算的事。
针对这种观点,CRFM的主任、华人Percy Liang于10月18日发表了一篇文章,表达了对基础模型的一些反思。
在建立基础模型研究中心后,社会各界引起了广泛反响,我们不光应该讨论一下基础模型为什么这么重要,也需要反思一下为什么社会上的回应。
Percy Liang希望最近发布的关于基础模型的报告,以及建立的斯坦福大学基础模型研究中心(CRFM)作为斯坦福人类中心人工智能研究所(Stanford Institute for Human-Centered AI, HAI)的一部分,并举办了一个研讨会以促进全社会对话。
这项工作在社会上受到了广泛的关注,一些人公开讨论了他们的想法,我们认为开放式话语对于构建正确的规范、最佳实践和围绕基础模型的更广阔的生态系统是必要的。
首先回答一个问题,什么是基础模型(Foundation models)?
基础模型的定义为在广泛的数据(通常使用大规模自监督算法)上训练的模型,该模型可以适用于广泛的下游任务。这些模型基于迁移学习的理念以及深度学习和大规模应用的计算机系统的最新进展,能够证明他们具有通用性,并能够大大提高了广泛下游任务的性能。
鉴于这种潜力,我们可以看到基础模型的范式已经发生变化,其中许多跨领域人工智能系统将直接建立或整合基础模型。
基础模型鼓励均质化(homogenization),也就是说同样的几个模型能够作为其他实际应用的基础被重复使用。
但这种整合是一把双刃剑,虽然集中化可以让研究人员集中精力在一小部分模型上来提高稳健性,减少偏差。但集中化还会将这些模型的单一故障点无限放大,并可能会对无数下游应用程序造成诸如安全风险、社会偏见等危害。并且随着越来越多的AI应用被开发出来,基础模型在当前的实践下都表现出明显和重大的社会风险。
CRFM主要负责基础模型的发展,并且是一种「负责任」的发展,研究中会特别关注不平等、滥用、环境影响、法律框架、规模伦理和经济后果。这些社会考虑能够进一步告知我们对技术基础的讨论,主要涵盖模型(包括数据、架构、目标、系统、评估、理论),及它们对人工智能领域(机器人、视觉、推理)的影响,以及它们在各个学科(法律、医疗、教育、生物医学)中的应用。
报告中还概述了现有做法应该如何改变:如提出数据管理协议、尊重隐私、标准评估范式、干预和补偿不公正的机制以及管理基础模型的规范。一般来说,在这个过程中,谁控制这一发展趋势,都将会影响基础模型的发展,以至影响更广泛的生态系统和社会。
报告的出发点在于,基础模型的当前轨迹不是不可避免的。基础模型可以(而且越来越应该)接触到实际应用中,在感知、互动、真实世界中交互、获取常识物理模型、心理理论以及获取植根于这个世界的语言是人工智能的重要组成部分,所有这些都需要基础模型提供技术支持。
此外,应用落地还可以通过将基础模型与AI中的其他方法结合来实现:PIGLeT 就是一个例子,它使用预训练的语言模型和语言的物理动力学模型来编码语言形式。也就是说基础模型不只是大型语言模型,基础模型还可以使用图像、视频和其他感官和知识库数据进行训练。报告中也强调应用落地对于基础模型如何在计算机视觉和机器人学中发展至关重要。
并且目前基础模型的发展通常没有集中在人身上,而是集中在资源上。在基础模型的发展过程,CRFM的目标是识别和提升人在整个生态系统的基础模型中的作用。人们创建的数据支持基础模型,开发基础模型,适应基础模型的具体应用,并与所得到的应用程序交互。
更广泛地应该强调数据主题、创建者、策展人和管理者、基础模型提供者、下游应用开发者、参与共同设计的硬件和软件开发者、恶意行动者、边缘群体,以及领域专家、患者、诉讼当事人和学生等等。
在研讨会上还特别强调了多样性,例如,代表性多样性、制度多样性和学科多样性是必要的,但这些多样性还远远足以使人们集中于比目前在基础模型发展中更大的程度。在许多意义上的多样性,包括方法和途径,是健康研究社区的精髓。
CRFM的社区反映了这一点:因为这将会是具有不同学科背景的基础模型的主题,并且所有人也在追求与基础模型正交、互补或矛盾的研究。
例如,虽然基础模型在数据结构中是典型「自下而上」的研究,但诸如因果网络、概率程序和正式系统等方法却是「自上而下」的。
虽然这两种研究模式似乎不兼容,但我们认为这些方法可以互相协同。
自顶向下方法中的推理通常由于难以解决逆问题而难以计算,但是基础模型可以提供有助于推理的快速建议。基础模型可以提供一种的快速、自动、初步的推理,该系统可以与其他方法集成,用于慢速、分析、审议推理。
总之,CRFM的报告和更广泛的研究议程中的目标是提供一个测量基础模型来识别他们的长处和弱点。通过提请注意这些模式,我们试图强调这些模式的巨大成功和迅速采用,同时也强调其存在的缺陷、持续的局限性以及社会关注的原因。
最终的目标是帮助人类社会塑造一个更好的未来,让这些模型得以开发、部署,并影响到它们所处的更广泛的生态系统。
参考资料:
https://crfm.stanford.edu/2021/10/18/reflections.html
![]()