谷歌大脑和DeepMind联合发布离线强化学习基准,将各种RL研究从线上转为线下

新智元报道
新智元报道
来源:arxiv
编辑:白峰
【新智元导读】离线强化学习方法可以帮我们弥合强化学习研究与实际应用之间的差距。近日,Google和DeepMind推出的RL Unplugged使从离线数据集中学习策略成为可能,从而克服了现实世界中与在线数据收集相关的问题,包括成本,安全性等问题。
为什么需要离线强化学习
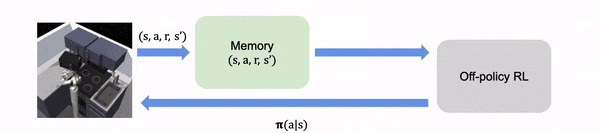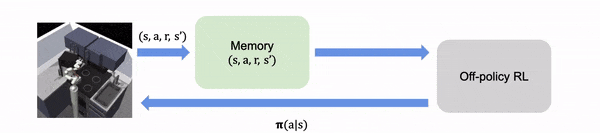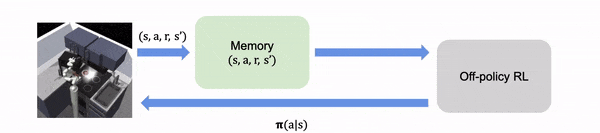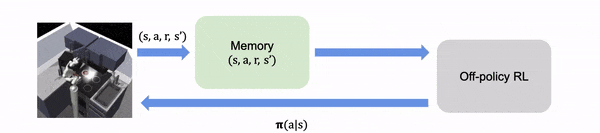 在实时 RL 中,算法在线收集学习经验
在实时 RL 中,算法在线收集学习经验
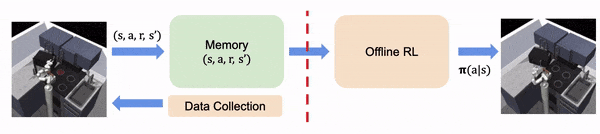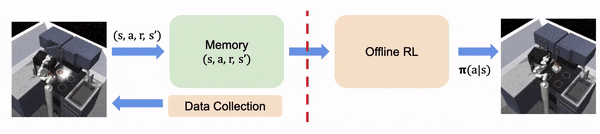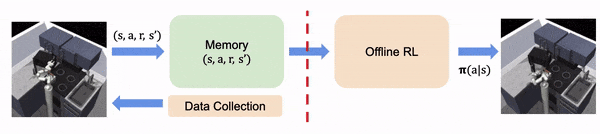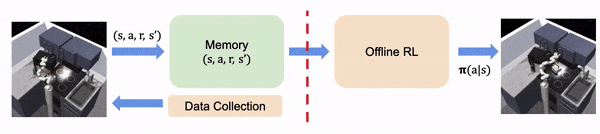 在离线 RL 中,经验都是离线收集
在离线 RL 中,经验都是离线收集
离线强化学习的难点在哪?
之前,对 RL 进行离线基准测试的方法仅限于一个场景: 数据集来自某个随机或先前训练过的策略,算法的目标是提高原策略的性能。
这种方法的问题是,现实世界的数据集不可能由单一的 RL 训练的策略产生,而且这种方法不能泛化到其他的场景。

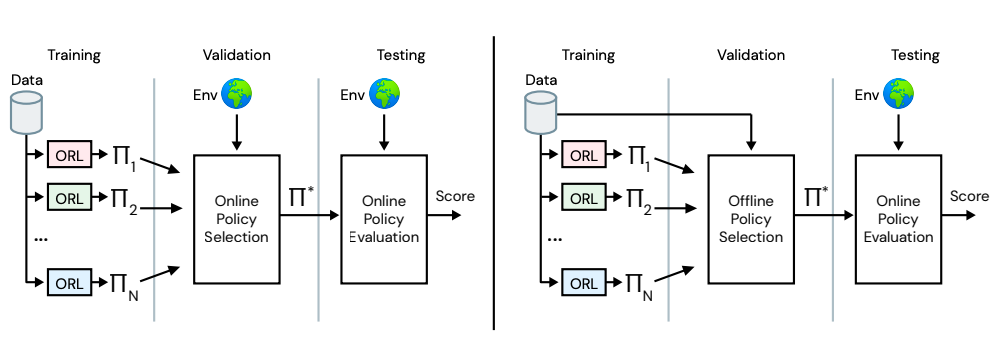
RL Unplugged让离线强化学习成为现实
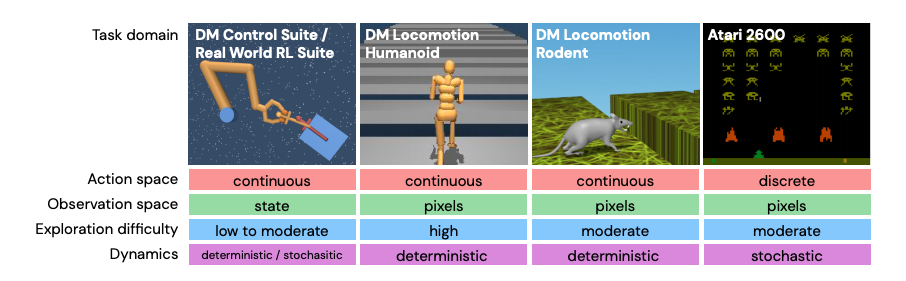
DM Control Suite,是在MuJoCo中实现的一组控制任务。
DM Locomotion,是涉及类人动物的运动任务。
Atari 2600,街机学习环境(ALE)套件,包含57套Atari 2600游戏(Atari57)。
Real-world Reinforcement Learning Suite,包括高维状态和动作空间,较大的系统延迟,系统约束,多目标,处理非平稳性和部分可观察性等任务。
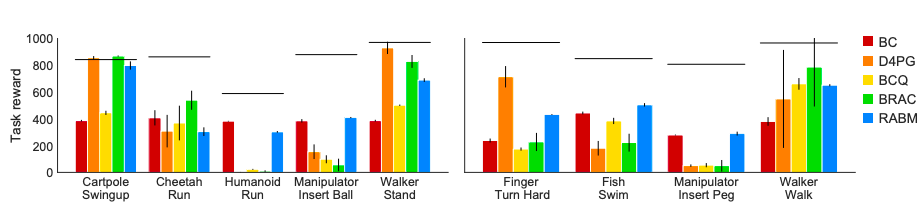

登录查看更多
相关内容
Arxiv
4+阅读 · 2020年2月13日




相关VIP内容
相关资讯
相关论文
Arxiv
4+阅读 · 2020年2月13日