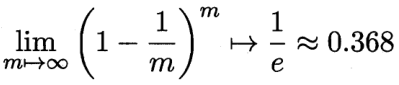傍晚小街路面上沁出微雨后的湿润,和煦的细风吹来,抬头看看天边的晚霞,嗯,明天又是一个好天气。走到水果摊旁,挑了个根蒂蜷缩、敲起来声音浊响的青绿西瓜,一边满心期待着皮薄肉厚瓤甜的爽落感,一边愉快地想着,这学期狠下了功夫,基础概念弄得清清楚楚,算法作业也信手拈来,这门课成绩一定差不了!
想必很多入门阶段的朋友看到这段都会第一时间想起当年被“西瓜书”支配的“恐惧”,“西瓜书”也即是周志华教授2016年出版的《机器学习》一书,因其书籍的封面是西瓜以及书籍内容以如何用各种机器学习的方法挑西瓜缓缓展开的缘故而被众多读者亲切地称为“西瓜书”。
“西瓜书”几乎是人工智能领域研究者和从业者人手一本的入门好书,然而很多人不知道的是早在“西瓜书”之前的2012年,周志华教授就曾出版过一本被称为
“森林书”
的英文专著:《Ensemble Methods:Foundations and Algorithms》。
![]() 由于《Ensemble Methods》在国内非常难买到,本书在豆瓣读书上的参评人数不多,但一小部分有机会读过原著的同学硬生生把分数给到了逆天的10分满星!但是买不到书对于很多读者来说无疑都是一种遗憾。
而好消息是近日“森林书”的中文版《集成学习:基础与算法》已经出版:
那么这本有望成为下一本人手必备的豆瓣满分好书究竟有何魅力呢?
由于《Ensemble Methods》在国内非常难买到,本书在豆瓣读书上的参评人数不多,但一小部分有机会读过原著的同学硬生生把分数给到了逆天的10分满星!但是买不到书对于很多读者来说无疑都是一种遗憾。
而好消息是近日“森林书”的中文版《集成学习:基础与算法》已经出版:
那么这本有望成为下一本人手必备的豆瓣满分好书究竟有何魅力呢?
![]() 周志华,南京大学教授、计算机系主任、人工智能学院院长、欧洲科学院外籍院士、
ACM/AAAS/AAAI/IEEE/IAPR Fellow、CCF会士。主要研究方向为人工智能、机器学习、数据挖掘。
周志华教授在集成学习领域研究多年,Chapman & Hall 出版社在2008年邀约周教授出版专著。该出版社曾出版随机森林发明人Leo Breiman的《Classification and Regression Trees》、自助采样发明人Bradley Efron的《An Introduction to the Boostrap》等名著,于是周教授应邀于2012年出版了《Ensemble Methods:Foundations and Algorithms》一书。
周志华,南京大学教授、计算机系主任、人工智能学院院长、欧洲科学院外籍院士、
ACM/AAAS/AAAI/IEEE/IAPR Fellow、CCF会士。主要研究方向为人工智能、机器学习、数据挖掘。
周志华教授在集成学习领域研究多年,Chapman & Hall 出版社在2008年邀约周教授出版专著。该出版社曾出版随机森林发明人Leo Breiman的《Classification and Regression Trees》、自助采样发明人Bradley Efron的《An Introduction to the Boostrap》等名著,于是周教授应邀于2012年出版了《Ensemble Methods:Foundations and Algorithms》一书。
这本书专注于讲述集成学习这一类先进的机器学习方法,这类方法会训练多个学习器并将它们结合起来解决一个问题,其中的典型代表是Bagging和Boosting。通常,一个结合了多个学习器的集成会比单个学习器更加精确,集成学习方法在很多的实际任务中获得了巨大成功。
在书籍之外周志华教授曾于今年亲自写过一个文笔颇佳的有关Boosting理论探索的故事。
![]() 2003年周志华教授与布瑞曼在欧洲机器学习大会期间探讨Boosting理论问题
1989年,哈佛大学的莱斯利·维利昂特(Leslie Valiant,计算学习理论奠基人、2010年ACM图灵奖得主)和他的学生迈克尔·肯斯(Michael Kearns,后来担任贝尔实验室人工智能研究部主任)提出了一个公开问题:“弱可学习性是否等价于强可学习性?”
这个问题大致上是说:如果一个机器学习任务存在着比“随机猜测”略好一点的“弱学习算法”,那么是否就必然存在着准确率任意高(与该问题的理论上限任意接近)的“强学习算法”?
直觉上这个问题的答案大概是“否定”的,因为我们在现实任务中通常很容易找到比随机猜测稍好一点的算法(比方说准确率达到51%)、却很难找到准确率很高的算法(比方说达到95%)。
出人意料的是,1990年,麻省理工学院的罗伯特·夏柏尔(Robert Schapire)在著名期刊Machine Learning上发表论文,证明这个问题的答案是“YES”!更令人惊讶的是,他的证明是构造性的!
也就是说,夏柏尔给出了一个过程,直接按这个过程进行操作就能将弱学习算法提升成强学习算法。过程的要点是考虑一系列“基学习器”,让“后来者”重点关注“先行者”容易出错的部分,然后再将这些基学习器结合起来。
遗憾的是,这个过程仅具备理论意义,并非一个能付诸实践的实用算法,因为它要求知道一些实践中难以事先得知的信息,比方说在解决一个问题之前,先要知道这个问题的最优解有多好。
后来夏柏尔到了新泽西的贝尔实验室工作,在这里遇见加州大学圣塔克鲁兹分校毕业的约夫·弗洛恩德(Yoav Freund)。凑巧的是,弗洛恩德曾经研究过多学习器的结合。两人开始合作。终于,他们在1995年欧洲计算学习理论会议(注:该会议已经并入COLT)发表了一个实用算法,完整版于1997年在Journal of Computer and System Sciences发表。这就是著名的AdaBoost。夏柏尔和弗洛恩德因这项工作获2003年“哥德尔奖”、2004年“ACM帕里斯·卡内拉基斯(Paris Kanellakis)理论与实践奖”。
AdaBoost的算法流程非常简单,用夏柏尔自己的话说,它仅需“十来行代码(just 10 lines of code)”。但这个算法非常有效,并且经修改推广能应用于诸多类型的任务。例如,在人脸识别领域被誉为“第一个实时人脸检测器”、获得2011年龙格-希金斯(Longuet-Higgins)奖的维奥拉-琼斯(Viola-Jones)检测器就是基于AdaBoost研制的。AdaBoost后来衍生出一个庞大的算法家族,统称Boosting,是机器学习中“集成学习”的主流代表性技术。即便在当今这个“深度学习时代”,Boosting仍发挥着重要作用,例如经常在许多数据分析竞赛中打败深度神经网络而夺魁的XGBoost,就是Boosting家族中GradientBoost算法的一种高效实现。
我们今天的故事就是关于Boosting学习理论的探索。
机器学习界早就知道,没有任何一个算法能“包打天下”(注:著名的“没有免费的午餐”定理,参见周志华《机器学习》,清华大学出版社2016,1.4节)。因此不仅要对算法进行实验测试,更要进行理论分析,因为有了理论上的清楚刻画,才能明白某个机器学习算法何时能奏效、为什么能奏效,而不是纯粹“碰运气”。
1997年,夏柏尔和弗洛恩德给出了AdaBoost的第一个理论分析。他们证明,AdaBoost的训练误差随训练轮数增加而指数级下降,这意味着算法收敛很快。对于大家最关心的泛化性能,即算法在处理新的、没见过的数据时的性能,他们的结论是:AdaBoost的泛化误差
2003年周志华教授与布瑞曼在欧洲机器学习大会期间探讨Boosting理论问题
1989年,哈佛大学的莱斯利·维利昂特(Leslie Valiant,计算学习理论奠基人、2010年ACM图灵奖得主)和他的学生迈克尔·肯斯(Michael Kearns,后来担任贝尔实验室人工智能研究部主任)提出了一个公开问题:“弱可学习性是否等价于强可学习性?”
这个问题大致上是说:如果一个机器学习任务存在着比“随机猜测”略好一点的“弱学习算法”,那么是否就必然存在着准确率任意高(与该问题的理论上限任意接近)的“强学习算法”?
直觉上这个问题的答案大概是“否定”的,因为我们在现实任务中通常很容易找到比随机猜测稍好一点的算法(比方说准确率达到51%)、却很难找到准确率很高的算法(比方说达到95%)。
出人意料的是,1990年,麻省理工学院的罗伯特·夏柏尔(Robert Schapire)在著名期刊Machine Learning上发表论文,证明这个问题的答案是“YES”!更令人惊讶的是,他的证明是构造性的!
也就是说,夏柏尔给出了一个过程,直接按这个过程进行操作就能将弱学习算法提升成强学习算法。过程的要点是考虑一系列“基学习器”,让“后来者”重点关注“先行者”容易出错的部分,然后再将这些基学习器结合起来。
遗憾的是,这个过程仅具备理论意义,并非一个能付诸实践的实用算法,因为它要求知道一些实践中难以事先得知的信息,比方说在解决一个问题之前,先要知道这个问题的最优解有多好。
后来夏柏尔到了新泽西的贝尔实验室工作,在这里遇见加州大学圣塔克鲁兹分校毕业的约夫·弗洛恩德(Yoav Freund)。凑巧的是,弗洛恩德曾经研究过多学习器的结合。两人开始合作。终于,他们在1995年欧洲计算学习理论会议(注:该会议已经并入COLT)发表了一个实用算法,完整版于1997年在Journal of Computer and System Sciences发表。这就是著名的AdaBoost。夏柏尔和弗洛恩德因这项工作获2003年“哥德尔奖”、2004年“ACM帕里斯·卡内拉基斯(Paris Kanellakis)理论与实践奖”。
AdaBoost的算法流程非常简单,用夏柏尔自己的话说,它仅需“十来行代码(just 10 lines of code)”。但这个算法非常有效,并且经修改推广能应用于诸多类型的任务。例如,在人脸识别领域被誉为“第一个实时人脸检测器”、获得2011年龙格-希金斯(Longuet-Higgins)奖的维奥拉-琼斯(Viola-Jones)检测器就是基于AdaBoost研制的。AdaBoost后来衍生出一个庞大的算法家族,统称Boosting,是机器学习中“集成学习”的主流代表性技术。即便在当今这个“深度学习时代”,Boosting仍发挥着重要作用,例如经常在许多数据分析竞赛中打败深度神经网络而夺魁的XGBoost,就是Boosting家族中GradientBoost算法的一种高效实现。
我们今天的故事就是关于Boosting学习理论的探索。
机器学习界早就知道,没有任何一个算法能“包打天下”(注:著名的“没有免费的午餐”定理,参见周志华《机器学习》,清华大学出版社2016,1.4节)。因此不仅要对算法进行实验测试,更要进行理论分析,因为有了理论上的清楚刻画,才能明白某个机器学习算法何时能奏效、为什么能奏效,而不是纯粹“碰运气”。
1997年,夏柏尔和弗洛恩德给出了AdaBoost的第一个理论分析。他们证明,AdaBoost的训练误差随训练轮数增加而指数级下降,这意味着算法收敛很快。对于大家最关心的泛化性能,即算法在处理新的、没见过的数据时的性能,他们的结论是:AdaBoost的泛化误差
![]() 训练误差
训练误差
![]() (
(
![]() 隐去了相对不太重要的其他项),这里的m是训练样本数,T是训练的轮数,
隐去了相对不太重要的其他项),这里的m是训练样本数,T是训练的轮数,
![]() 可以大致理解为基学习器的复杂度。因为AdaBoost每训练一轮就增加一个基学习器,所以
可以大致理解为基学习器的复杂度。因为AdaBoost每训练一轮就增加一个基学习器,所以
![]() 大致相当于最终集成学习器的复杂度。于是,这个理论结果告诉我们:训练样本多些好,模型复杂度小些好。
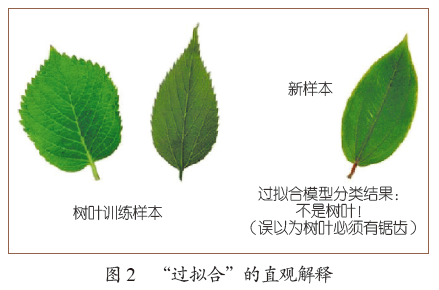
希望训练样本多,这容易理解。为什么希望模型复杂度小呢?这是由于机器学习中存在“过拟合”,简单地说,如果对训练数据学得“太好了”,反而可能会犯错误。例如图2,在学习“树叶”时,如果学习器错误地认为没有锯齿就不是树叶,这就过拟合了。一般认为,产生过拟合的重要原因之一,就是由于模型过于复杂,导致学得“过度”了、学到了本不该学的训练样本的“特性”而非样本总体的“共性”。
显然,夏柏尔和弗洛恩德在1997年的理论蕴义与机器学习领域的常识一致,因此很容易得到大家认可。
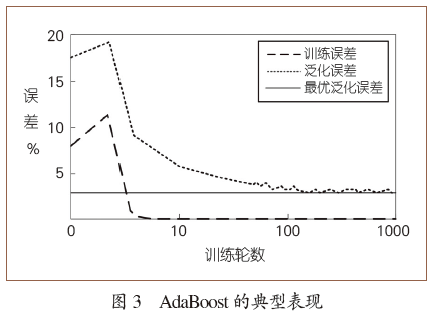
然而,AdaBoost在实践中却呈现出一个奇异的现象:它似乎没有发生过拟合!
如图3所示,在训练误差到达0之后继续训练,虽然模型复杂度在增大,但泛化误差却仍会继续下降。
科学发现中有一个基本方法论:若有多个理论假设符合实验观察,则选取最简洁的。这就是所谓“奥卡姆剃刀(Ocama’s razor)准则”。这个准则在众多学科史上都发挥了重要作用。然而如果审视AdaBoost的行为,却可以发现它是如此与众不同。
如图3中,训练到第10轮和第1000轮时形成的假设(集成学习器)都与“实验观察”(训练数据)一致,前者仅包含10个基学习器、后者包含1000个基学习器。显然,根据奥卡姆剃刀应该选取前者,但实际上后者却更好。
也就是说,AdaBoost的行为表现不仅违背了机器学习领域的常识,从更广大的视角看,甚至违背了科学基本准则!
因此,弄清AdaBoost奇异现象背后的道理,不仅能满足我们的好奇心,还可能揭开机器学习中以前不知道的某种秘密,进而为算法设计打开一扇新门。“AdaBoost为何未发生过拟合?”作为Boosting最关键、最引人入胜的基础理论问题,吸引了诸多知名学者投入其中。
大致相当于最终集成学习器的复杂度。于是,这个理论结果告诉我们:训练样本多些好,模型复杂度小些好。
希望训练样本多,这容易理解。为什么希望模型复杂度小呢?这是由于机器学习中存在“过拟合”,简单地说,如果对训练数据学得“太好了”,反而可能会犯错误。例如图2,在学习“树叶”时,如果学习器错误地认为没有锯齿就不是树叶,这就过拟合了。一般认为,产生过拟合的重要原因之一,就是由于模型过于复杂,导致学得“过度”了、学到了本不该学的训练样本的“特性”而非样本总体的“共性”。
显然,夏柏尔和弗洛恩德在1997年的理论蕴义与机器学习领域的常识一致,因此很容易得到大家认可。
然而,AdaBoost在实践中却呈现出一个奇异的现象:它似乎没有发生过拟合!
如图3所示,在训练误差到达0之后继续训练,虽然模型复杂度在增大,但泛化误差却仍会继续下降。
科学发现中有一个基本方法论:若有多个理论假设符合实验观察,则选取最简洁的。这就是所谓“奥卡姆剃刀(Ocama’s razor)准则”。这个准则在众多学科史上都发挥了重要作用。然而如果审视AdaBoost的行为,却可以发现它是如此与众不同。
如图3中,训练到第10轮和第1000轮时形成的假设(集成学习器)都与“实验观察”(训练数据)一致,前者仅包含10个基学习器、后者包含1000个基学习器。显然,根据奥卡姆剃刀应该选取前者,但实际上后者却更好。
也就是说,AdaBoost的行为表现不仅违背了机器学习领域的常识,从更广大的视角看,甚至违背了科学基本准则!
因此,弄清AdaBoost奇异现象背后的道理,不仅能满足我们的好奇心,还可能揭开机器学习中以前不知道的某种秘密,进而为算法设计打开一扇新门。“AdaBoost为何未发生过拟合?”作为Boosting最关键、最引人入胜的基础理论问题,吸引了诸多知名学者投入其中。
Boosting算法是集成学习算法之一,在《集成学习:基础与算法》一书中,周教授除了对Boosting做了由浅入深的讲述之外还有对Bagging等算法的详细介绍。
这里给出一个在“西瓜书”和“森林书”都出现过的小问题,这个问题是Bagging算法中的自助采样问题。
自助法是基于自助采样法的检验方法。对于总数为m的样本集合,进行m次有放回的随机抽样,得到大小为m的训练集。m次采样过程中,有的样本会被重复采样,有的样本没有被抽出过,将这些没有被抽出的样本作为验证集,进行模型验证,这就是自助法的验证过程。
问:
在自助法的采样过程中,对m个样本进行m次自助抽样,当m趋于无穷大时,最终有多少数据从未被选择过?
在每次采样时,样本未被采样的概率为(1-1/m),那么样本在m次采样始终不被采到的概率为
![]() ,取极限得到
,取极限得到
![]() 给定m个训练样本,第i个样本被选中0,1,2,...次的概率近似为 λ=1的的泊松分布,所以第i个样本至少出现一次的概率为1-(1/e)≈ 0.632。即:对Bagging的任一基分类器,训练时原始训练集中约有36.8%的样本未被使用。
以下从“森林书”摘出一部分具体介绍一下集成学习方法及其应用。
给定m个训练样本,第i个样本被选中0,1,2,...次的概率近似为 λ=1的的泊松分布,所以第i个样本至少出现一次的概率为1-(1/e)≈ 0.632。即:对Bagging的任一基分类器,训练时原始训练集中约有36.8%的样本未被使用。
以下从“森林书”摘出一部分具体介绍一下集成学习方法及其应用。
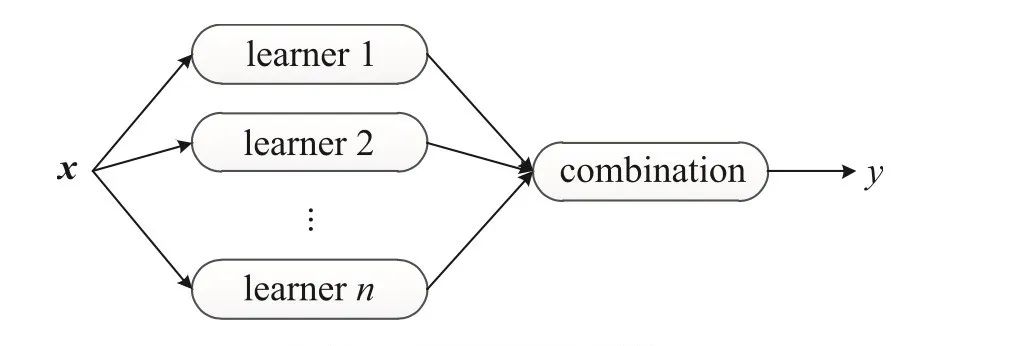
和传统学习方法训练一个学习器不同,集成学习方法训练多个学习器并结合它们来解决一个问题。通常,集成学习也被称为基于委员会的学习(committee-based learning)或多分类器系统(multiple classifier system)。
一个集成由多个基学习器(base learner)构成,而基学习器由基学习算法(base learning algorithm)在训练数据上训练获得,它们可以是决策树、神经网络或其他学习算法。
大多数集成学习方法使用同一种基学习算法产生同质的基学习器,即相同种类的学习器,生成同质集成(homogeneous ensemble);同时,也有一些方法使用多种学习算法训练不同种类的学习器,构建异质集成(heterogeneous ensemble)。在异质集成中,由于没有单一的基学习算法,相较于基学习器,人们更倾向于称这些学习器为个体学习器(individual learner)或组件学习器(component learner)。
通常,集成具有比基学习器更强的泛化能力。实际上,集成学习方法之所以那么受关注,很大程度上是因为它们能够把比随机猜测稍好的弱学习器(weak learner)变成可以精确预测的强学习器(strong learner)。因此,在集成学习中基学习器也称为弱学习器。
由于使用多个模型解决问题的思想在人类社会中有悠久的历史,我们难以对集成学习方法的历史进行溯源。例如,作为科学研究的基本假设,当简单假设和复杂假设都符合经验观测时,奥卡姆剃刀(Occam’s razor)准则偏好简单假设;但早在此之前,希腊哲学家伊壁鸠鲁(Epicurus,公元前 341—270)提出的多释准则(principle of multiple explanations)[Asmis,1984] 主张应该保留和经验观测符合的多个假设。
集成学习领域的发展得益于三个方面的早期研究,即:
分类器结合、弱分类器集成和混合专家模型(mixture of experts)。
分类器结合主要来自模式识别领域。这方面的研究关注强分类器,试图设计强大的结合规则来获取更强的结合分类器,在设计和使用不同的结合规则上积累深厚。
弱分类器集成方面的研究主要集中在机器学习领域。这方面的研究关注弱分类器,试图设计强大的算法提升弱分类器的效果,产生了包括 AdaBoost 和 Bagging 等众多著名的集成学习算法,并且在将弱学习器提升为强学习器方面有深入的理论理解。
混合专家模型的研究主要集中在神经网络领域。在此,人们通常考虑使用分而治之的策略来共同学习一组模型,并结合使用它们获得一个总体解决方案。
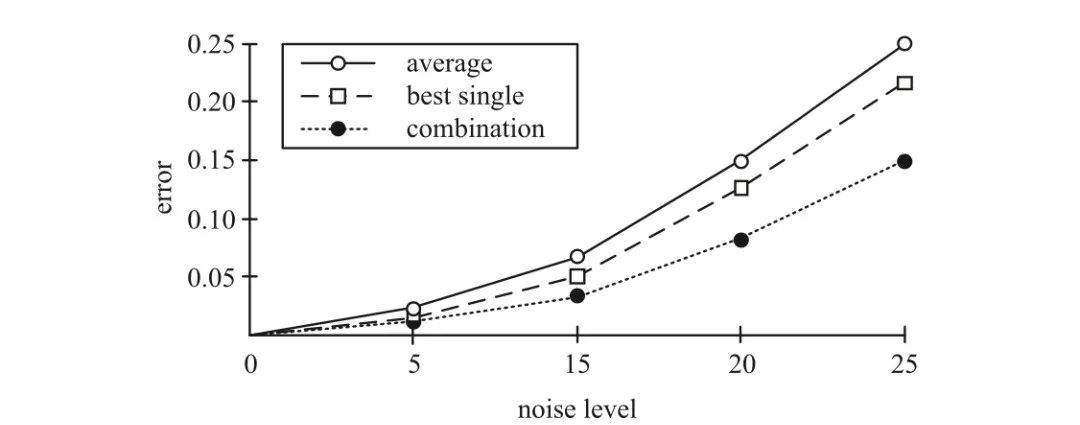
20 世纪 90 年代以来,集成学习方法逐渐成为一个主要的学习范式,这主要得益于两项先驱性工作。其中,[Hansen & Salamon,1990] 是实验方面的工 作, 如下图,它指出一组分类器的集成经常会产出比其中最优个体分类 器更精准的预测;
集成通常比最优个体学习器更准确,其中横坐标为噪声水平(noise level),纵坐标为分类错误率(error),三种对比方法分别为平均法(average)、最优个体法(best single)和结合方法(combination)[Hansen & Salamon,1990]
[Schapire,1990] 是理论方面的工作,它构造性地证明了弱学习器可以被提升为强学习器。
虽然我们所需的高精度学习器难以训练,但弱学习器在实践中却容易获得,这个理论结果为使用集成学习方法获得强学习器指明了方向。
一般来讲,构建集成有两个步骤:首先产生基学习器,然后将它们结合起来。为了获得一个好的集成,通常认为每个基学习器应该尽可能准确,同时尽可能不同。
值得一提的是,构建一个集成的计算代价未必会显著高于构建单一学习器。这是因为使用单一学习器时,模型选择和调参经常会产生多个版本的模型,这与在集成学习中构建多个基学习器的代价是相当的;同时,由于结合策略一般比较简单,结合多个基学习器通常只会花费很低的计算代价。
KDD Cup
作为最著名的数据挖掘竞赛,自 1997 年以来每年举办,吸引了全球大量数据挖掘队伍参加。竞赛包含多种多样的实际任务,如网络入侵检测(1999)、分子生物活性和蛋白质位点预测(2001)、肺栓塞检测(2006)、客户关系管理(2009)、教育数据挖掘(2010)和音乐推荐(2011)等。在诸多机器学习技术中,集成学习方法获得了高度的关注和广泛的使用。例如,在连续三年的 KDD Cup 竞赛中(2009—2011),获奖的冠军和亚军都使用了集成学习方法。
另一项著名的赛事 Netflix Prize由 Netflix 公司举办。竞赛任务是基于用户的历史偏好提升电影推荐的准确度,如果参赛队伍能在 Netflix 公司自己的算法基础上提升 10% 的准确度,就能够获取百万美元大奖。2009 年 9 月 21 日,Nexflix 公司宣布,百万美元大奖由 BellKor’s Pragmatic Chaos 队获得,他们的方案结合了因子模型、回归模型、玻尔兹曼机、矩阵分解、k-近邻等多种模型。另外还有一支队伍取得了和获奖队伍相同的效果,但由于提交结果晚了 20 分钟无缘大奖,他们同样使用了集成学习方法,甚至使用“The Ensemble”作为队名。
除了在竞赛上获得显赫战绩,集成学习方法还被成功应用到多种实际应用中。实际上,在几乎所有的机器学习应用场景中都能发现它的身影。例如,计算机视觉的绝大部分分支,如目标检测、识别、跟踪,都从集成学习方法中受益。
基于 AdaBoost 和级联结构,Viola & Jones [2001,2004] 提出了一套通用的目标检测框架。Viola & Jones [2004] 显示在一台 466MHz 计算机上,人脸检 测器仅需 0.067 秒就可以处理 384×288 的图像,这几乎比当时最好的技术快 15倍,且具有基本相同的检测精度。在随后的十年间,这个框架被公认为计算机视觉领域最重大的技术突破。
Huang et al. [2000] 设计了一套集成学习方法解决姿态无关的人脸识别问题。它的基本思路是使用特殊设计的模型集成多个特定视角的神经网络模型。和需要姿态信息作为输入的传统方法相比,这个方法不需要姿态信息,甚至能在输出识别结果的同时输出姿态信息。Huang et al. [2000] 发现这个方法的效果甚至优于以完美姿态信息作为输入的传统方法。类似的方法后来被用于解决多视图人脸检测问题 [Li et al.,2001]。
目标跟踪的目的是在视频的连续帧中对目标对象进行连续标记。通过把目标检测看成二分类问题,并训练一个在线集成来区分目标对象和背景,Avidan [2007] 提出了集成跟踪(ensemble tracking)方法。该方法通过更新弱分类器来学习由于对象外观和背景发生的变化。Avidan [2007] 发现这套方法能处理多种 具有不同大小目标的不同类别视频,并且运行高效,能应用于在线任务。
在计算机系统中,用户行为会有不同的抽象层级,相关信息也会来自多个渠道,集成学习方法就非常适合于刻画计算机安全问题 [Corona et al.,[2009]。Giacinto et al. [2003] 使用集成学习方法解决入侵检测问题。考虑到有多种特征刻画网络连接,他们为每一种特征构建了一个集成,并将这些集成的输出结合 起来作为最终结果。Giacinto et al. [2003] 发现在检测未知类型的攻击时,集成学习方法能够获得最优的性能。此后,Giacinto et al. [2008] 提出了一种集成方法解决基于异常的入侵检测问题,该方法能够检测出未知类型的入侵。
恶意代码基本上可以分为三类:病毒、蠕虫和木马。通过给代码一个合适的表示,Schultz et al. [2001] 提出了一种集成学习方法用以自动检测以往未见的恶意代码。基于对代码的 n-gram 表示,Kolter & Maloof [2006] 发现增强决策树(boosted decision tree)能够获得最优的检测效果,同时他们表示这种方法可以在操作系统中检测未知类型的恶意代码。
集成学习方法还被应用于解决计算机辅助医疗诊断中的多种任务,尤其用于提升诊断的可靠性。周志华等人设计了一种双层集成架构用于肺癌细胞检测任务 [Zhou et al.,2002a],其中当且仅当第一层中的所有个体学习器都诊断为“良性”时才会预测为“良性”,否则第二层会在“良性”和各种不同的癌症类型间进行预测。他们发现双层集成方法能同时获得高检出率和低假阳性率。
对于老年痴呆症的早期诊断,以往的方法通常仅考虑来自脑电波的单信道数据。Polikar et al. [2008] 提出了一种集成学习方法来利用多信道数据;在此方法中,个体学习器基于来自不同电极、不同刺激和不同频率的数据进行训练,同时它 们的输出被结合起来产生最终预测结果。
除了计算机视觉、安全和辅助诊断,集成学习方法还被应用到多个其他领域和任务中。例如,信用卡欺诈检测 [Chan et al.,1999;Panigrahi et al.,2009],破产预测 [West et al.,2005],蛋白质结构分类 [Tan et al.,2003;Shen & Chou,2006],种群分布预测 [Araújo & New,2007],天气预报 [Maqsood et al.,2004;Gneiting & Raftery,2005],电力负载预测 [Taylor & Buizza,2002], 航空发动机缺陷检测 [Goebel et al.,2000;Yan & Xue,2008],音乐风格和艺 术家识别 [Bergstra et al.,2006] 等。
本书的译者是李楠博士,李楠博士是在南京大学读研期间开始接触集成学习的,当时在导师周志华教授指导下从事选择性集成和集成多样性方面的研究工作。
第一,我最初曾认为集成学习是一系列具有“三个臭屁皮匠顶个诸葛亮”朴素想法的启发式方法,缺乏理论基础,但后来对偏差-方差分解、Boosting间隔理论、集成多样性等课题的学习和研究,使我彻底抛弃了这种想法;更重要的是,这段研究经历所积累的理论知识为我后来快速学习掌握其他机器学习方法提供了莫大的帮助,至今仍受益良多。
第二,机器学习是面向实践的学科,集成学习在实践中的优异效果让人印象深刻。正是这段对集成学习的研究经历,使我掌握了多种构建集成学习的方法和技巧,为后来的实践夯实了基础。
工作期间,多有同事问及集成学习方向的专业书籍,无奈当时国内并无相关专著,而本书专著在国内很难买到,只能作罢。后来,欣闻电子工业出版社够得原著中文版权,并邀请我翻译,便欣然应允。
周志华教授在得知李楠博士担任译者时谈到:
李楠青年才俊,师从于吾,主攻集成学习,勤于钻研、硕果累累;曾获首届百度奖学金,入选IBM博士生英才计划等。2015年
博士毕业后就职于阿里iDST、达摩院,近期加入微软,繁忙工作之余拔冗译著,甚为不易。李楠博士曾兼任苏州大学数学科学学院计算数学系主任,经验丰富,佳译可待。
在本文留言区留言,谈一谈你和集成学习有关的学习、竞赛等经历。
AI 科技评论将会在留言区选出15名读者,每人送出《集成学习:基础与算法》一本。
活动规则:
1. 在留言区留言,留言点赞最高的前 15 位读者将获得赠书。获得赠书的读者请联系 AI 科技评论客服(aitechreview)。
2. 留言内容会有筛选,例如“选我上去”等内容将不会被筛选,亦不会中奖。
3. 本活动时间为2020年8月23日 - 2020年8月30日(23:00),活动推送内仅允许中奖一次。

 由于《Ensemble Methods》在国内非常难买到,本书在豆瓣读书上的参评人数不多,但一小部分有机会读过原著的同学硬生生把分数给到了逆天的10分满星!但是买不到书对于很多读者来说无疑都是一种遗憾。
由于《Ensemble Methods》在国内非常难买到,本书在豆瓣读书上的参评人数不多,但一小部分有机会读过原著的同学硬生生把分数给到了逆天的10分满星!但是买不到书对于很多读者来说无疑都是一种遗憾。

 周志华,南京大学教授、计算机系主任、人工智能学院院长、欧洲科学院外籍院士、
ACM/AAAS/AAAI/IEEE/IAPR Fellow、CCF会士。主要研究方向为人工智能、机器学习、数据挖掘。
周志华,南京大学教授、计算机系主任、人工智能学院院长、欧洲科学院外籍院士、
ACM/AAAS/AAAI/IEEE/IAPR Fellow、CCF会士。主要研究方向为人工智能、机器学习、数据挖掘。
 2003年周志华教授与布瑞曼在欧洲机器学习大会期间探讨Boosting理论问题
2003年周志华教授与布瑞曼在欧洲机器学习大会期间探讨Boosting理论问题

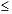 训练误差
训练误差
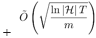 (
(
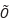 隐去了相对不太重要的其他项),这里的m是训练样本数,T是训练的轮数,
隐去了相对不太重要的其他项),这里的m是训练样本数,T是训练的轮数,
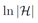 可以大致理解为基学习器的复杂度。因为AdaBoost每训练一轮就增加一个基学习器,所以
可以大致理解为基学习器的复杂度。因为AdaBoost每训练一轮就增加一个基学习器,所以
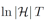 大致相当于最终集成学习器的复杂度。于是,这个理论结果告诉我们:训练样本多些好,模型复杂度小些好。
大致相当于最终集成学习器的复杂度。于是,这个理论结果告诉我们:训练样本多些好,模型复杂度小些好。
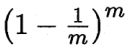 ,取极限得到
,取极限得到