谷歌推出多轴注意力方法,既改进ViT又提升MLP
机器之心报道
在卷积神经网络和 ViT 竞争计算机视觉领域霸主时,谷歌:我取二者所长,提出一种两全其美的方法。
自从 2012 年 AlexNet 问世以来,卷积神经网络一直是计算机视觉的主要机器学习架构。最近,受自然语言处理启发,注意力机制已逐渐纳入视觉模型。这些注意力方法增强了输入数据的某些部分,同时最小化了其他部分,以便网络可以专注于数据最重要的部分。
视觉 Transformer (ViT) 为计算机视觉模型设计创造了一个完全没有卷积的全新领域。ViT 将多个图像 patch 视为单词序列,并在顶部应用了 Transformer 编码器。当在足够大的数据集上进行训练时,ViT 在图像识别方面表现出惊人的性能。
虽然卷积和注意力都足以获得良好的性能,但它们都不是必需的。例如,MLP-Mixer 采用简单的多层感知器 (MLP) 来跨空间位置混合图像 patch,从而形成一个全 MLP 架构。就训练和推理所需的准确性和计算之间的权衡而言,它是现有 SOTA 视觉模型的有力替代方案。然而,ViT 和 MLP 模型都难以扩展到更高的输入分辨率,因为计算复杂度随图像大小呈二次增加。
现在,来自谷歌的研究者提出一种新的多轴方法,简单有效,改进了原有的 ViT 和 MLP 模型,可以更好地适应高分辨率、密集的预测任务,并且可以自然地适应不同的输入大小,具有高灵活性和低复杂度。
基于新提出的方法,谷歌的研究者还为高级和低级视觉任务建立了两个主干模型。第一个模型在论文《MaxViT: Multi-Axis Vision Transformer》中详细介绍,该模型显著提高了多个高级视觉任务的 SOTA 水平,包括图像分类、目标检测、分割、质量评估和生成。该论文已被 ECCV 2022 接收。

MaxViT 论文地址:https://arxiv.org/pdf/2204.01697.pdf
GitHub 地址:https://github.com/google-research/maxvit
第二个主干模型 MAXIM 是一个类似 UNet 的架构,在多个低级图像任务上实现了有竞争力的性能,包括去噪、去模糊、去雾、去雨和低光增强。该论文已被 CVPR 2022 接收。

MAXIM 论文地址:https://openaccess.thecvf.com/content/CVPR2022/papers/Tu_MAXIM_Multi-Axis_MLP_for_Image_Processing_CVPR_2022_paper.pdf
GitHub 地址:https://github.com/google-research/maxim
下图展示了使用 MAXIM 逐帧对图像去模糊的效果:

方法概览
多轴注意力(multi-axis attention)将 ViT 中使用的全尺寸注意力分解为两种稀疏形式:局部注意力和(稀疏)全局注意力。如下图所示,多轴注意力包含块注意力(局部)和网格注意力(全局)。块注意力工作在非重叠窗口内(即中间特征图中的小 patch),以捕捉局部模式;而网格注意力工作在一个稀疏采样的均匀网格上,用于长程(全局)交互。网格注意力和块注意力窗口的大小可以当作超参数进行控制,以实现线性计算复杂度。
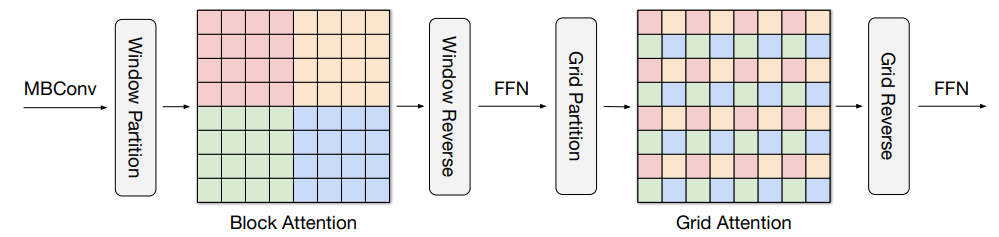
多轴注意力执行图,图中相同颜色的像素一起出现。
这种低复杂度的注意力可以显著提高其在许多视觉任务中的应用,尤其是在高分辨率视觉预测方面,比 ViT 中使用的原始注意力显示出更强的泛化性。谷歌基于这种多轴注意方法构建了两个主干实例——MaxViT 和 MAXIM,分别用于高级任务和低级任务。
MaxViT
在 MaxViT 中,谷歌首先通过连接 MBConv 和多轴注意力来构建单独的 MaxViT 块(如下如),这个单独的块可以编码局部和全局视觉信息,而不考虑输入分辨率。然后,谷歌在分层体系架构(类似于 ResNet、CoAtNet)中叠加由注意力和卷积组成的重复块,生成同类型的 MaxViT 体系架构。
值得注意的是,MaxViT 与以前的分层方法不同,因为 MaxViT 可以在整个网络中「观察到」全局,甚至在更早的高分辨率阶段,MaxViT 在各种任务中显示出更强的模型能力。
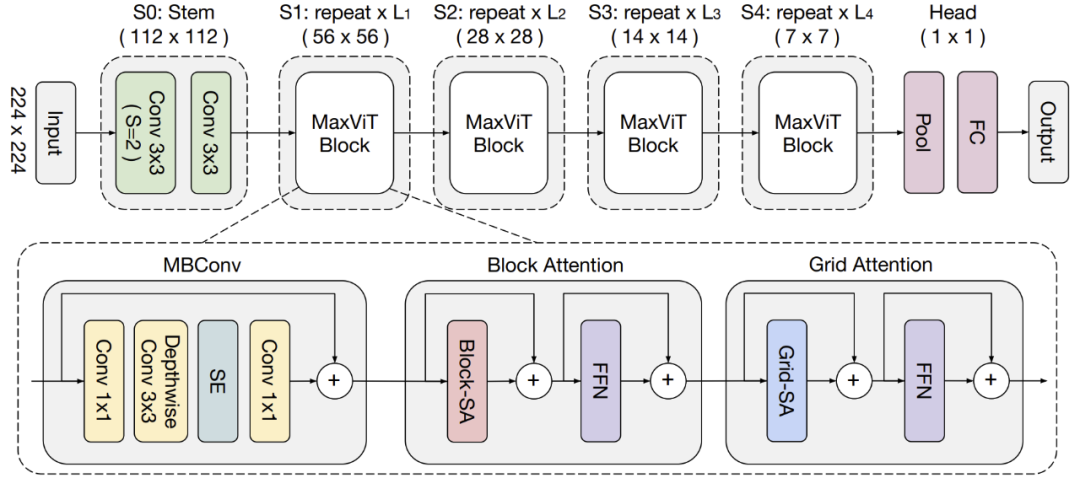
MaxViT 的元架构
MAXIM
MAXIM 是一个通用的类 UNet 架构,专为低级的图像 - 图像预测任务量身定制。谷歌探索了用 gMLP(gated multi-layer perceptron)网络进行局部、全局注意力并行设计方法。此外,MAXIM 的交叉门控块可用于不同输入信号之间的相互作用。该块可以作为交叉注意力模块的有效替代,因为它只使用门控 MLP 操作符与各种输入进行交互,而不依赖于繁重的交叉注意力计算。
谷歌所提出的组件,包括 MAXIM 中的门控 MLP 和交叉门控块,对图像大小具有线性复杂度,使其在处理高分辨率图像时更加高效。
结果
谷歌展示了 MaxViT 在广泛的视觉任务中的有效性。
在图像分类方面,MaxViT 在各种设置下都取得了 SOTA 结果:仅通过 ImageNet-1K 训练,MaxViT 达到了 86.5% 的 top-1 准确率;通过 ImageNet-21K(14M 图像,21k 类)预训练,MaxViT 达到 88.7% 的 top-1 准确率;通过 JFT(300M 图像,18k 类)预训练,MaxViT-XL 实现了 89.5% 准确率。
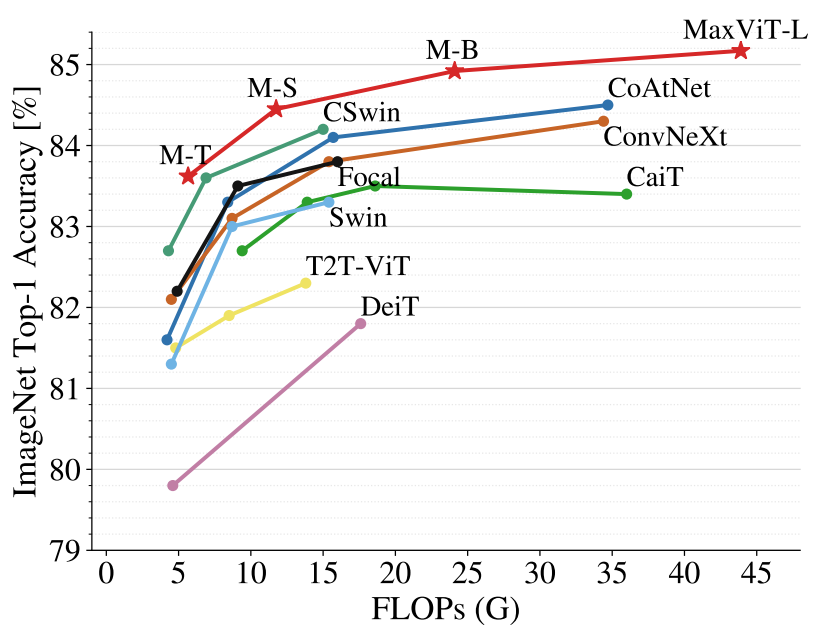
在 ImageNet-1K 上,MaxViT 与 SOTA 模型的性能比较结果。比较参数为 224x224 图像分辨率下的准确率与 FLOP 性能。
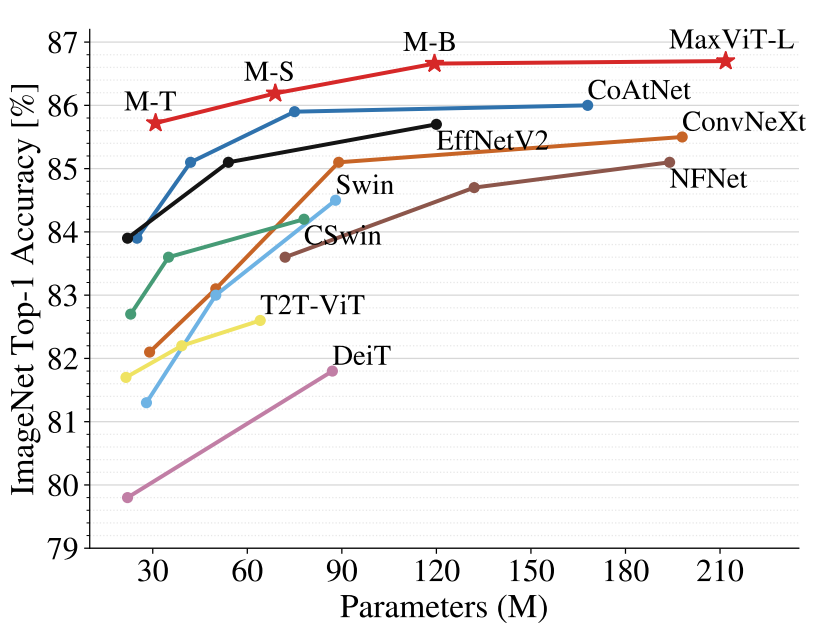
ImageNet-1K 微调设置下的准确率与参数曲线。
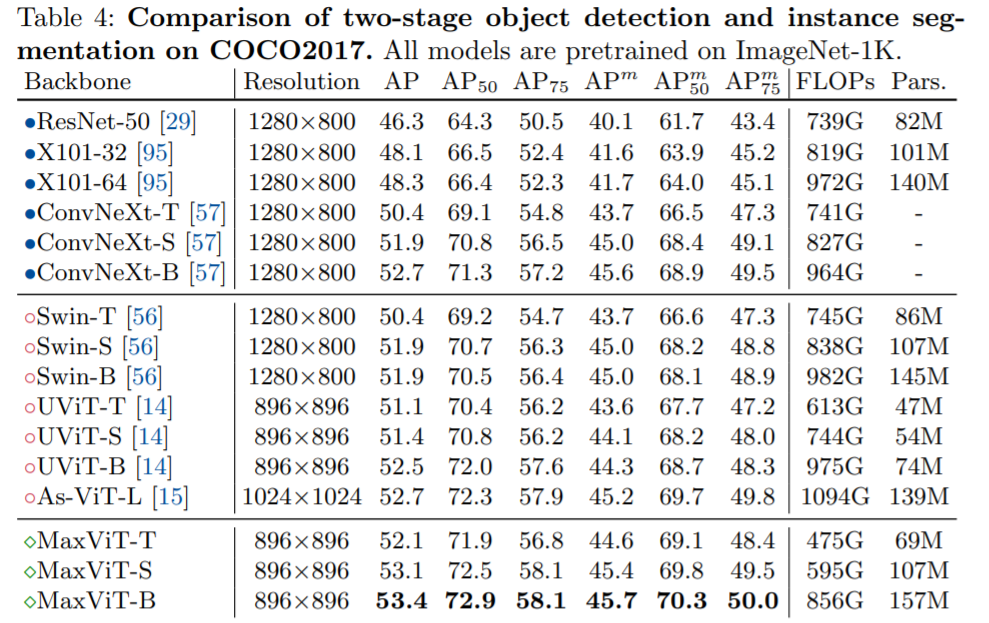
在下游任务中,MaxViT 作为主干可以在广泛的任务范围内提供良好的性能。对于 COCO 数据集上的目标检测和分割,MaxViT 主干实现了 53.4 AP,优于其他基础级模型,而只需要大约 60% 的计算成本。在图像美学(aesthetics)评估方面,MaxViT 模型将目前 SOTA 性能的 MUSIQ 模型提高了 3.5%。
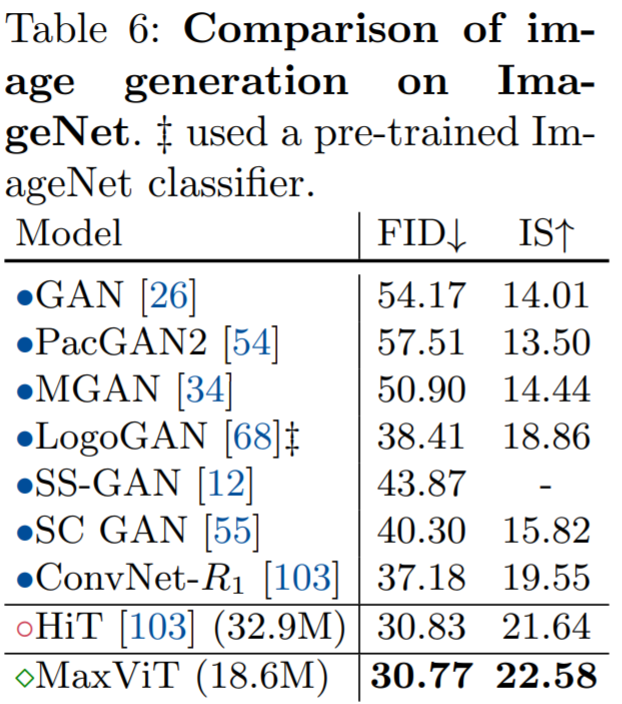
实验还展示了 MaxViT 构建块在图像生成方面的有效性能,在 ImageNet-1K 无条件生成任务上获得了更好的 FID 和 IS 分数,并且参数数量明显低于 SOAT 模型 HiT。
为图像处理任务定制的类似 UNet 的 MAXIM 主干模型在 20 个测试数据集中的 15 个上获得了 SOTA 结果,涉及去噪、去模糊、去雨、去雾和低光增强等多个任务,并且所需参数量和 FLOPs 与竞争模型相当或更少,MAXIM 能恢复图像的更多细节,视觉伪影也更少。

MAXIM 在图像去噪、去模糊、去雨、低光增强任务上的视觉结果。
总结
最近两年的工作表明,卷积网络和视觉 Transformer 可以实现类似的性能。谷歌的新工作则提出了一个统一的设计,它利用了二者的优点——高效卷积和稀疏注意力。MaxViT 可以在各种视觉任务上实现 SOTA 性能,更重要的是,MaxViT 可以很好地扩展到非常大的数据量上。谷歌还展示了另一种使用 MLP 算子 MAXIM 的多轴设计,在广泛的低级视觉任务中实现了 SOTA 性能。
此外,谷歌提出的多轴方法可以很容易地扩展到语言建模,以在线性时间内捕获局部和全局依赖关系。研究团队希望所提方法可以进一步扩展到高维和多模态信号上,并已开源了 MAXIM 和 MaxViT 的代码和模型,旨在推动未来对高效注意力和 MLP 模型的研究。
原文链接:
https://ai.googleblog.com/2022/09/a-multi-axis-approach-for-vision.html
掌握「声纹识别技术」:前20小时交给我,后9980小时……

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com

