CVPR2019爆款论文作者现场解读:视觉语言导航、运动视频深度预测、6D姿态估计
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击文末“阅读原文”立刻申请入群~
转载自公众号Robinly
2019年计算机视觉顶会CVPR前不久刚在美国长滩闭幕。Robin.ly在大会现场独家采访20多位热点论文作者,为大家解读论文干货。本期三篇爆款文章:
1. CVPR满分文章、最佳学生论文奖、结合强化学习和自监督模仿学习的视觉-语言导航方法:
Reinforced Cross-Modal Matching and Self-Supervised Imitation Learning for Vision-Language Navigation
2. 最佳论文荣誉提名、Google Research 基于Youtube“假人挑战”数据集的深度预测研究:
Learning the Depths of Moving People by Watching Frozen People
3. 斯坦福大学几何计算研究组6D姿态及尺寸估计研究:
Normalized Object Coordinate Space for Category-Level 6D Object Pose and Size Estimation

1“最佳学生论文奖”视觉语言导航
CVPR 2019“最佳学生论文奖”论文“Reinforced Cross-Modal Matching and Self-Supervised Imitation Learning for Vision-Language Navigation”,在评审中得到3个Strong Accept,总分排名第一。文章第一作者王鑫现在是加州大学圣巴巴拉分校在读博士生、微软研究院实习生,从事计算机视觉、自然语言处理和机器学习三个领域的交叉研究。以下是他在CVPR大会现场接受Robin.ly访谈的视频实录:
王鑫在美国长滩CVPR2019大会接受Robin.ly专访
Wenli:今天我们邀请到了 CVPR “最佳学生论文奖”获得者, UC Santa Barbara 攻读博士学位的王鑫。首先恭喜你获奖。能不能给我们介绍一下这篇论文?
Xin Wang:
谢谢!这篇论文的主题是视觉语言导航,关于如何在 3D 环境中引导智能体遵循自然语言指令。这是我暑期在微软研究院开展的合作项目。我在回到学校之后继续完善了这项工作,并写成论文提交给了CVPR。
Wenli:你是怎么想到这篇论文选题的?
Xin Wang:
我做视觉和语言相关的研究有两三年的时间了,一直致力于让机器学会描述视觉世界。我的目标是让机器人不仅能够描述静态场景,还能够与物理世界进行交互。我对视觉语言导航的数据集非常感兴趣,觉得这是我真正想做的东西。所以我决定和我的导师以及微软研究院的合作者一起解决这个问题。
Wenli:你的论文对这个研究领域最大的贡献是什么?
Xin Wang:
这项工作的一个局限就是无法准确区分成功的信号。这种信号相当粗糙,只要智能体到达了目的地,就会被视为一次成功的行为,无论在这个过程中是否遵循了自然语言指令。例如,你可以在房间里按照随机的路线到达目的地,仍然可以被视为成功。但这不是我们想要的。我们希望智能体能够在理解自然语言的基础上遵循指示做出行动。我们在这篇文章中提出了一种强化跨模态匹配方法 (Reinforced Cross-Modal Matching),利用一个匹配度评估器来评估原始指令在生成的轨迹中重建的完整度,强化智能体按照指令行动的能力。
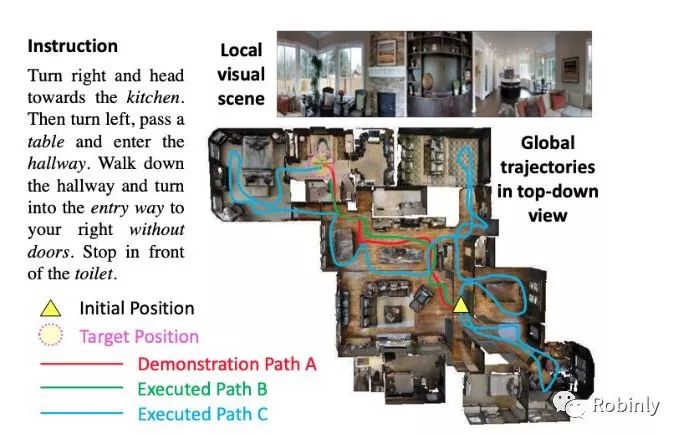
王鑫论文图示,图片来源:王鑫
这项工作的另一个关键挑战是泛化的能力。智能体通常是在一些它见过的环境中进行训练,并在没见过的环境中进行测试。所以它在见过和没见过的环境之间的表现会有非常大的差别。但是对于一些实际情况,例如,我们有一个家用机器人,我们希望这个机器人能够熟悉它所部署的房屋环境。我们因此提出一种自我监督的模仿学习方法,让机器人通过自我监督来探索没见过的环境,从而使它的行为更加适应这些新的环境。这样一来,智能体在见过和没见过的环境之间的表现就会更加接近。
Wenli:你下一步的工作计划是什么?
Xin Wang:
我还会继续在这个重要的方向深入研究,将视觉、语言和机器人技术结合起来,教会机器人观察世界、描绘世界,甚至与世界互动。

王鑫在CVPR2019现场接受Robin.ly采访
Wenli:你毕业后打算进入工业界吗?人们一直在谈论学术界和工业界的不同之处。你认为哪边的资源和环境更有优势?
Xin Wang:
一开始我对工业界更感兴趣,但是最近我改变了想法,也会考虑找一个学术界的职位。我认为如果单纯做研究,学术界是最理想的场所,有更自由的环境。同时我也很喜欢指导学生。
我认为工业界的一大优势是资源和数据。你拥有足够的GPU资源来训练模型,能够获得大量的内部和外部数据,也能跟很多志同道合的人一起工作。我认为这些都非常重要。(完)
论文信息
Reinforced Cross-Modal Matching and Self-Supervised Imitation Learning for Vision-Language Navigation
作者:Xin Wang, Qiuyuan Huang, Asli Celikyilmaz, Jianfeng Gao, Dinghan Shen, Yuan-Fang Wang, William Yang Wang, and Lei Zhang
研究机构:University of California, Santa Barbara,Microsoft Research, Duke University
文章链接:
https://arxiv.org/abs/1811.10092
2 最佳论文荣誉提名:基于“假人挑战”的运动视频深度预测
Mannequin Challenge(“假人挑战”)曾在2016年底风靡网络,它要求视频中被拍摄者要像人体模型一样静止不动、保持一个定格动作,由摄影师通过镜头的移动技巧来进行拍摄。Google Research 利用2000个YouTube的“假人挑战”视频作为训练数据集,创建了能从运动视频中进行深度预测的AI模型,并在CVPR发表了论文“Learning the Depth of Moving People by Watching Frozen People”,获得最佳论文荣誉提名。
该文第一作者Zhengqi Li,是康奈尔大学Noah Snavely教授组的第三年博士生,在Google Research实习期间合作完成了这项研究。他在CVPR 2019 poster session现场为我们介绍了这项研究成果:
这项研究的目标是在摄像机和场景中的人都在随机自由移动的情况下进行密集的深度预测。我们知道经典的几何移动立体算法不能应用于移动中的人,而我们使用数据驱动的方法解决了这个问题。我们从互联网上的一个培训数据源获得了一个名为 Mannequin Challenge 数据集,其中包含了一群人在模仿人体模特的一系列YouTube视频。场景中的所有人都是静态的,有一个手持摄像机在巡视这些场景。针对场景中的静态人物,我们可以使用经典的 Structure from Motion(SfM)和 Multi View Stereo(MVS)算法来获得相机姿态和深度信息。但是互联网视频的内容非常杂乱,包括失真和模糊的镜头,所以我们要先删除数据集中的视频异常帧,用新的数据集来训练我们的模型。
下一步的问题就是如何利用静态的人物来训练模型,并且在推理阶段把这个模型应用于移动的人物身上,但这两种情况是非常不同的。我们能够想到的最简单的办法就是输入单个 RGB 图像,也就是将单个 RGB 帧输入网络,然后回归得到多视图立体深度信息。但是这个方法忽略了 3D 信息在视频序列的相邻帧中的重要性。我们提出的方法是,除了单个 RGB 图像,我们还把运动视差的深度作为附加信息一起输入网络。我们使用 mask-RCNN 算法来计算人类掩膜(human masks)。针对所关注的帧,计算出 t - delta 作为关键帧,再一帧一帧的计算光流信息,然后使用三角测量法将光流转换成深度数据。
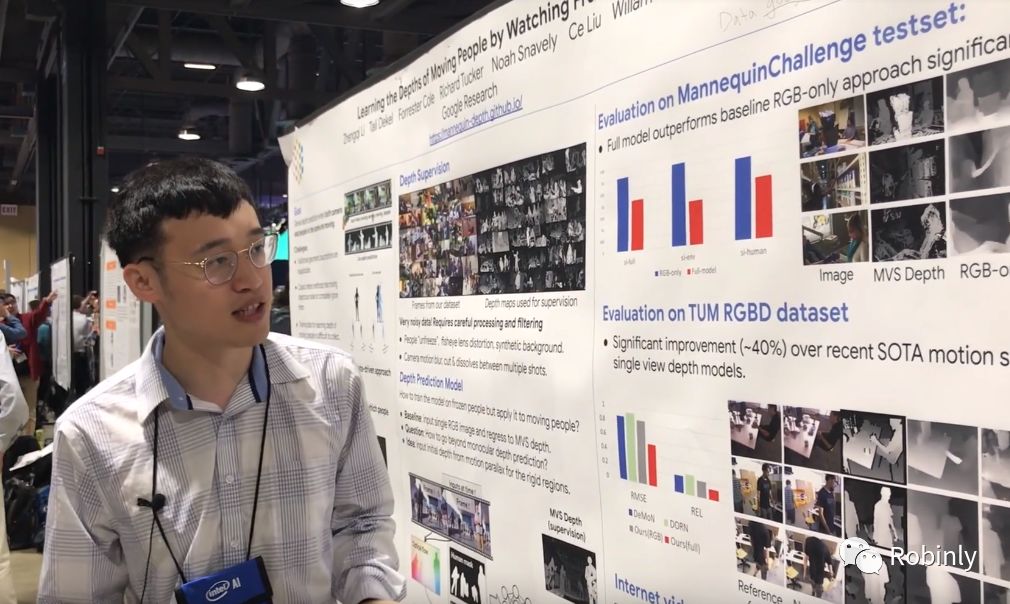
Zhengqi Li在CVPR现场讲解论文Poster
同时,我们还可以计算光流和相机姿态的置信度,再将在运动视差中获得的带有人类掩膜深度的 RGB 图像和置信度数据输入到网络中。我们希望网络能够利用这些额外的信息来更好的预测整个场景的深度。
我们在不同的数据集上测试了这个方法。在 Mannequin Challenge 测试数据集上,我们把完整的模型与只包含 RGB 的单视图深度预测方法进行了比较。结果表明,与单视图深度预测基线方法相比,我们提出的模型能够获得更准确的深度预测结果。在标准TUM RGBD 数据集中,我们测试了摄像机和人物在同一场景中同时移动的情况,还和其他最前沿的移动立体视觉算法,比如 DeMoN,以及单视图深度预测方法 DORN 进行了比较。这些结果都证明了我们的完整模型可以利用刚性场景的运动视差进行预测,其结果明显优于其他基线方法和前沿方法。跟从传感器中获取的真实信息进行定性比较后也可以发现,我们在有人和无人的场景中所获得的结果都比前人所提出的方法要准确得多。

标准TUM RGBD数据集的结果比较,图片来源:Zhengqi Li
我们的深度预测方法还可以应用于增强现实下的各种视觉效果中,比如视频散焦和对象插入,甚至当人和摄像机同时移动时,还能够将人物从场景中移除。

基于深度的视觉效果,图片来源:Zhengqi Li
论文信息
Learning the Depths of Moving People by Watching Frozen People
作者:Zhengqi Li, Tali Dekel, Forrester Cole, Richard Tucker, Noah Snavely, Ce Liu, and William T. Freeman
研究机构:Google Research
文章链接: https://arxiv.org/abs/1904.11111
3 热门文章:斯坦福大学“6D姿态估计”研究
斯坦福大学几何计算研究组关于“6D姿态估计”的论文 “Normalized Object Coordinate Space for Category-Level 6D Object Post and Size Estimation” 在本次CVPR大会也受到广泛关注。Robin.ly邀请第一作者He Wang和第二作者Srinath Sridhar现场解析研究成果。Srinath Sridhar是斯坦福大学的博士后研究员,主要从事计算机视觉、人类技能和人类互动数字化等问题研究。He Wang是斯坦福大学的博士生,研究课题主要是人和物体的交互。
Wenli:能介绍一下这篇论文吗?当初为什么选择这个课题?
Srinath Sridhar:
这个课题在计算机视觉领域被称为“6D 姿态估计问题”,在许多应用领域中都扮演着非常重要的角色。例如,在自动驾驶,机器人以及增强/虚拟现实中,我们需要详细了解对象在环境中的位置,并希望能够赋予计算机理解陌生环境的能力。
He Wang:
我来举个例子。当我们进入一个新环境时,可能会看到许多非常熟悉的物品,例如马克杯和手机。我们很感兴趣的是它们的位置和朝向,了解这些信息有助于更好的操作这些物品,尤其是对于机器人来说。
问题的关键在于,虽然我们对于所有这些物品所属的类别非常熟悉,但是可能从没见过这个具体的物品。比如有一个杯子你从没见过,但是你知道它是一个杯子。而许多依赖于杯子精确模型的经典算法却无法应用在这个它没见过的杯子上。这就是我们从事这项研究的原因。我们想要估算某个物体的 3D 朝向和 3D 位置,并利用 RGB-D 图像,也就是带有深度信息的彩色图像来估算物体的立体尺寸。

给电脑和杯子做立体尺寸,图片来源:Srinath Sridhar、He Wang
Wenli:你们在这篇论文中提出了哪些新的想法?
He Wang:
我认为我们的主要贡献有点。第一个是我们提出了归一化物体坐标空间(NOCS)这种新颖的表征方式。我们试图找到物体的位置,解决实例分割问题,同时估算出 3D 物体大小和 6D 姿态。我们需要一种表征方法将问题统一解决。所以我们提出的核心概念就是对物体的坐标同时进行大小和姿态上的归一化而得出这样一个表征。
我来具体解释一下。以这款手机为例。当相机对准这款手机时,在相机的参考框架中,如果你把观测手机,你会看到这台手机可能在比如说低于相机水平线的两米的位置。这就是我们所说的这个手机在相机世界中的坐标。但如果你位于这款手机自身的正则世界里(canonical world),比如表面上,你会发现手机就位于世界的中心,其中心坐标就是(0,0,0)。并且所有不同手机在归一化物品坐标空间中具有相同的朝向,并且它们的大小通过单位立方体对角线进行了归一化操作。这样一来它们就具有相同的尺寸,相同的方向,并且中心位置坐标都为零。我们的任务是找到相机坐标空间和手机归一化物体坐标空间之间的对应关系,来帮助我们解决 6D 姿态和 3D 尺寸的估算问题。

相机的表征方式,图片来源:Srinath Sridhar、He Wang
Srinath Sridhar:
另外一项创新是使用了深度学习方法来完成这一特定任务。其中的挑战在于我们没有现成的数据集,因为深度学习是在监督数据上运行的,所以我们需要大量的数据来测试我们的方法。
我们开发了一种新的收集数据的方法,称为混合现实方法(Mixed Reality Approach),也叫混合现实数据生成(mixed reality data generation),利用了逆向增强现实的原理。比如我们在宜家展厅里对不同类型的桌子进行了扫描,然后使用计算机图形技术渲染出合成物体(synthetic object),最后将这些物体放置于扫描过的桌子上方。这样就能为每个物体自动添加标签,提供对象的确切位置、姿态和形状之类的信息。利用真实的宜家场景图像作为背景,将计算机图形技术中的合成物体和渲染工具结合在一起,我们生成了超过25万个包含对象位置以及 6D 朝向标记的示例。
Wenli:这些技术可以用于哪些工业界的实际项目?
Srinath Sridhar:
自动驾驶,机器人,增强现实,3D场景理解,这些都是潜在的应用。我们将这些应用视为非常广泛的应用集合。比如让家用机器人去厨房洗碗。每个人都能做到,但是对于机器人来说却非常困难,因为机器人无法判断以前从未见过的物体的位置和朝向。所以我们开发的技术可以用来帮助机器人了解物体的位置。
另一个潜在的应用是增强现实。还是刚才那个例子,你在一个新的环境中看到了以前从未见过的一个物体,你想在上面用增强现实的方法添加颜色,那么你就需要够弄清楚瓶子的 3D 位置以及朝向。
He Wang:
从另一个角度来看,我们可以认为经典的计算机视觉算法更善于操作训练数据中的特定对象,相比之下,人类则有能力将我们的技能泛化到未知的事物上。我们的表征方法正是让这种泛化成为了可能。我们可以将同一类别的所有物体放在归一化物体空间中,然后在这个共享的空间中学习此类物体的特征。这样当我们看到新的此类物体时,就知道这与我们在训练过程中看到的内容非常相似,从而能够相对容易的将在训练过程中学到的技能到测试用例上。所以,我们的方法也可以应用于操作和理解各种日常物品。

Srinath Sridhar(图左)和He Wang(图右)在美国长滩CVPR2019现场
Wenli:你们目前在研究中面临的挑战是什么?
Srinath Sridhar:
一个是数据。我们展示了我们的算法在不同的对象类别上的效果,其中的挑战就是如何将这个算法泛化到更多对象类别。在计算机视觉中,我们每天处理的对象属于1万到3万个类别。所以从6个类别上升到上万类别的规模需要大量的工作。我认为我们还需要一段时间才能做到。所以如果想使用监督机器学习技术来解决这个问题,那么数据将是一个巨大的挑战。
He Wang:
数据挑战实际上还包含另外一个方面。对于我们关注的任务,我们需要使用大量合成对象进行监督。对所有真实场景中的对象进行高成本的 3D 注释非常困难,所以我们选择使用合成对象。但是这会引入一些误差,导致渲染的对象看起来与真实对象之间存在差异。
在这项工作中,我们尝试了使用少量的真实监督数据和来自 Microsoft COCO 数据集的大量弱监督图像(没有姿态等标注)训练我们的网络学习真实图像的特点。计算机视觉领域把这个过程称为域适应(domain adaptation)。我认为要缩合成图像和真实图像之间的差别还有很长的路要走,我们还会继续改进。
Wenli:计算机视觉最近受到了大量关注,学术界目前有很多成功的研究项目。你们认为工业界也在跟进吗?你们跟工业界有合作吗?
Srinath Sridhar:
没错。这个方向近几天确实越来越热门。我参加计算机视觉会议已经有7年的时间了,见证了这个社区的发展。无论是提交和被接受的论文数量还是参会人数都出现了大幅增长。越来越多的人在这个领域投入了大量精力和经费,也获得了不少高质量的研究成果。这些成果蕴含着巨大的商业价值,受到了工业界的支持。所以实际上学术界和工业界之间是存在交流跟合作的,但是这种合作存在着一定的局限性。从数据的方面来说,学术界的数据集可能很难用于商业目的,而商业数据集通常不公开,因此我们无法使用这些数据来改进现有的算法。我们跟一些业内顶级科技公司内部的实验室都保持着长期的合作关系。我们在很多公司都有朋友,跟他们的合作可以说是很愉快的。(完)
论文信息
Normalized Object Coordinate Space for Category-Level 6DObject Pose and Size Estimation
作者:He Wang, Srinath Sridhar, Jingwei Huang, Julien Valentin, Shuran Song, and Leonidas J. Guibas
研究机构:Stanford University, Google, Princeton University, and Facebook AI Research
文章链接:
https://arxiv.org/abs/1901.02970
-完-
*延伸阅读
点击左下角“阅读原文”,即可申请加入极市目标跟踪、目标检测、工业检测、人脸方向、视觉竞赛等技术交流群,更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~

△长按关注极市平台
觉得有用麻烦给个在看啦~



