研究者希望这篇文章对神经网络架构感兴趣的人有所帮助,特别是那些正在寻找不同角度进行研究的研究者。
深度学习的基本原理可以追溯到几十年前,20 世纪 80 年代 Geoffrey Hinton 等人提出了基于梯度的反向传播学习算法,而 ConvNets 从早期就被应用于手写数字识别等计算机视觉任务。然而,深度学习的真正威力直到 2012 年才显露出来,那年 AlexNet 赢得了 ImageNet 大规模图像分类挑战赛。
之后数据可用性的提高、计算技术的进步和算法的改进使得深度学习持续取得成功。随着最近大型模型的兴起,这一领域的快速发展还没有显示出放缓的迹象。
深度学习不仅对我们的日常生活产生了显著的影响,还改变了机器学习从业者和研究人员的工作流程。新的设计原则不断被提出,例如 ResNet 引入残差连接、 Transformers 采用多头自注意力等。
在算法不断发展的过程中,效率和可扩展性是两个不能忽视的概念,让视觉模型变得既小又大又成为另一需求。
怎样理解既小又大呢?小模型代表对效率的需求,因为视觉识别系统通常部署在边缘设备上;大型模型突出对可扩展性的需求,其可以利用日益丰富的计算和数据来实现更高的准确率。
最近几年这两个方向的研究都取得了卓越成效,产生了许多有用的设计原则被后来的研究所采用。
本文中,来自 UC 伯克利的博士生刘壮(Zhuang Liu)在其博士论文《 Efficient and Scalable Neural Architectures for Visual Recognition 》中,从两个方面展开研究:(1)开发直观的算法以实现高效灵活的 ConvNet 模型推理;(2) 研究基线方法以揭示扩展方法成功的原因。
具体而言,首先,本文介绍了关于密集预测的第一个随时算法研究。然后,该研究将模型剪枝算法与简单的基线方法进行比较来检查模型的有效性。最后研究者提出了这样一个问题,即通过采用 Transformer 中的设计技巧对传统的 ConvNet 进行现代化改造,来测试纯 ConvNet 所能达到的极限,并探索在视觉任务上自注意力机制在 Transformer 中的可扩展性上所起的作用。
![]()
论文地址:https://www2.eecs.berkeley.edu/Pubs/TechRpts/2022/EECS-2022-205.pdf
本文除了提出一个新架构外,该研究还从批判的角度对被认为是微不足道或老式基线的方法或模型进行实证研究,发现当提供正确的技术时,它们具有惊人的竞争力。
刘壮(Zhuang Liu)现在是 UC 伯克利 EECS(电气工程与计算机科学) 的博士生,由 Trevor Darrell 教授指导。此外,他还在 Meta AI Research(原 Facebook AI Research )担任兼职学生研究员。也曾在康奈尔大学、英特尔实验室和 Adobe Research 担任访问研究员或实习生。他于 2017 年在清华大学姚班获得学士学位。
刘壮的研究重点是准确和高效的深度学习架构 / 方法,他对开发简单的方法和研究基线方法特别感兴趣。他还是大名鼎鼎 DenseNet 的共同一作,凭借论文《Densely Connected Convolutional Networks》,摘得 CVPR 2017 最佳论文奖。
![]()
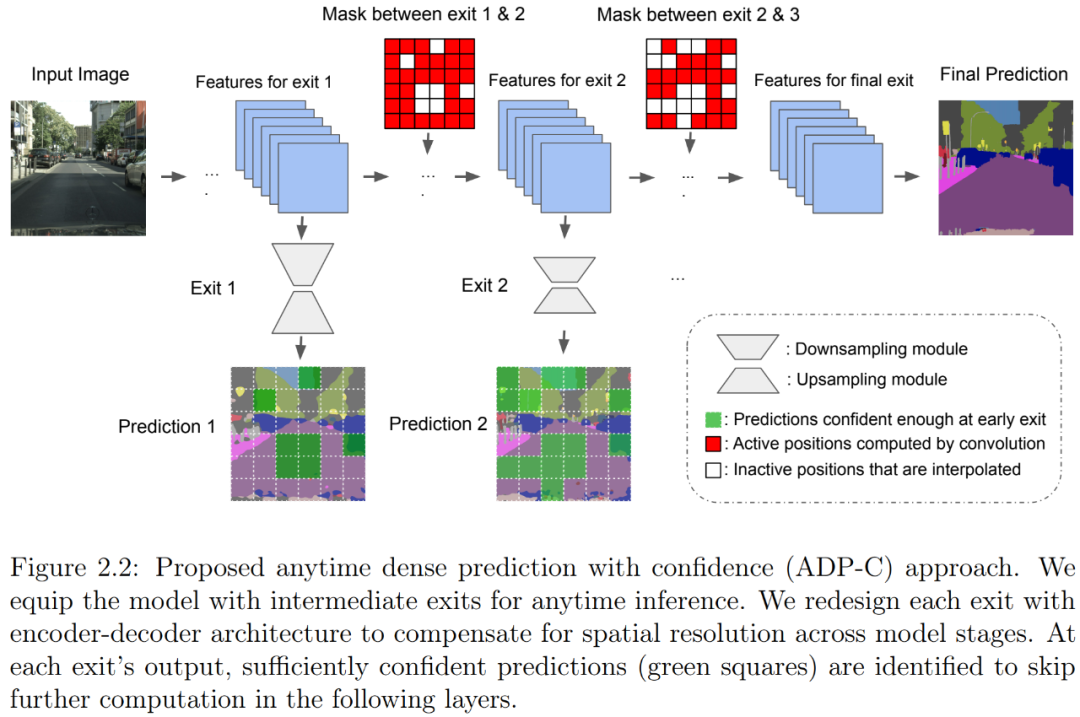
本文介绍了一种随时密集视觉识别方法,它可以让神经网络推理更加灵活。随时推理需要一个模型对随时可能的停止进行一系列预测。先前关于随时视觉识别的研究主要集中在图像分类领域。作者提出了
首个用于随时密集预测的统一和端到端方法
。一连串的 exit 被附加到模型上以进行多个预测。作者重新设计了 exit,以考虑每个 exit 的特征的深度和空间分辨率。
为了减少总计算量并充分利用先前预测,作者开发了一种全新的空间自适应方法,以避免在早期预测已经足够置信的区域上进行进一步计算。这一方法被命名为基于置信的随时密集预测(anytime dense prediction with confidence, ADP-C),它达到了与基础模型相同的最终准确率水平,同时显著减少了总计算量。
![]()
作者在 Cityscapes 语义分割和 MPII 人体姿态估计数据集上评估了所提方法,结果表明,ADP-C 可以在不牺牲准确率的情况下随时进行推理,同时还将基础模型的总 FLOPs 减少 44.4% 和 59.1%。作者还与基于深度平衡网络和基于特征的随机采样进行的随时推理进行比较,表明 ADP-C 在准确率 - 计算曲线上始终占有优势。
![]()
与上章中的自适应计算随时推理方法相比,静态神经网络剪枝方法试图通过与输入无关的方式减少神经网络的计算量。由于自身具有的简单性、有效性以及有时更好的硬件兼容性,这类方法通常在实践中用于缩小模型。在本章中,作者试图
了解静态神经网络剪枝方法成功背后的底层机制
。
典型的剪枝算法是一个三段式的 pipeline,分别为训练(大模型)、剪枝和微调。在剪枝过程中,根据一定的标准对冗余权重进行剪枝,并保留重要的权重,以保持最佳准确率。在这项工作中,作者提出了一些与常见看法相悖的观察结果。对于其检查过的所有 SOTA 结构化修剪算法,
对修剪后的模型进行微调只能得到与使用随机初始化权重训练模型相当或更差的性能
。对于假设预定义目标网络架构的剪枝算法,则可以摆脱整个 pipeline 并直接从头开始训练目标网络。
作者的观察结果对于多个网络架构、数据集和任务是一致的,这意味着:1)通常不需要训练大型、过度参数化的模型来获得高效的最终模型;2)学得的大模型的「重要」权重通常对小型剪枝模型没有用处;3)对最终模型的效率更关键的是剪枝后的架构本身,而非一组继承的「重要」权重。这表明在某些情况下,剪枝可能作为架构搜索范式产生作用。
结果表明,未来结构化剪枝方法的研究中需要进行更仔细的基线评估。作者还与「彩票假设」(Lottery Ticket Hypothesis)进行了比较,发现在最佳学习率下,彩票假设中使用的「中奖彩票」初始化并没有带来随机初始化的改进。
![]()
第四章:A ConvNet for the 2020s
剪枝是一种流行的缩小模型的方法。在上章中,作者通过实证研究证明了结构化剪枝的真正价值不是获得一组特定的权重值,而是识别出一个有用的子架构。在本章中,作者
将注意力转向扩展计算机视觉神经架构
。
一个经典的例子是 ResNets,它提出了残差连接。将没有残差连接的「普通」网络扩展到数十层会导致训练损失增加,更不用说测试准确率变差了。然而,一个具有残差连接的 ResNet 可以扩展到 100 多层,同时改进了训练损失和测试准确率。之后,Vision Transformers 开始显现出比基于卷积的 ResNet 更大的可扩展性。作者试图通过与现代化 ConvNet 的比较,来了解 Transformers 扩展成功的背后是什么。
作者重新检查了设计空间并测试了纯 ConvNet 所能达到的极限,并逐渐将标准 ResNet「升级(modernize」为视觉 Transformer 的设计,在过程中发现了导致性能差异的几个关键组件。作者将一系列纯 ConvNet 模型命名为 ConvNeXt。
ConvNeXt 完全由标准 ConvNet 模块构建,并且在准确率和可扩展性方面,ConvNeXt 取得了媲美 Transformer 的结果
,达到 87.8% ImageNet top-1 准确率,在 COCO 检测和 ADE20K 分割方面优于 Swin Transformer,同时保持标准 ConvNet 的简单性和有效性。
![]()
WAIC黑客马拉松——蚂蚁财富双赛道
行情波动下的金融问答挑战赛
该赛道在财富社区的问答数据基础上,针对每个用户的问题,利用检索、深度学习、自然语言处理等技术,生成出流畅、准确、合理的针对该问题的回答。
AntSQL大规模金融语义解析中文Text-to-SQL挑战赛
该赛道采用金融领域的表格作为数据源,涵盖了基金的产品和属性,提供在此基础上的标注的Query-SQL对,希望选手们能在此基础上训练深度学习模型,将自然语言准确的转换为可查询的SQL语句。
-
-
-
获奖选手受邀参加2022世界人工智能大会WAIC · AI开发者日举行的颁奖典礼 ;
-
优秀选手有机会获得Offer绿色通道,入职蚂蚁财富认知智能团队;
-
邀请好友参赛即可获得
扫地机器人、空气炸锅,欢迎加入钉钉群了解详情。
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com