学界 | 神奇的面包机!谷歌造出对抗样本的实体版
选自arXiv
机器之心编译
参与:刘晓坤、路雪
近日,谷歌提出了一种生成对抗图像patch的方法,可以欺骗分类器输出任意选定的目标类,甚至可以将patch打印成贴纸(伪装或不伪装)应用到任意的现实场景中。看了这篇论文,读者们觉得该技术可以怎么应用?欢迎大家留言讨论。
深度学习系统大部分易受对抗样本的影响,这些仔细选取的输入可以导致网络改变输出,而人类肉眼无法发现其区别 [15, 5]。这些对抗样本通常对每个像素进行细微的更改,可以使用很多优化策略发现它们,如 L-BFGS [15]、Fast Gradient Sign Method (FGSM) [5]、DeepFool [10]、Projected Gradient Descent (PGD) [8],以及近期提出的 Logit-space Projected Gradient Ascent (LS-PGA) [2]。其他攻击方法试图修改图像的一小部分像素(Jacobian-based saliency map [11]),或者图像固定位置的一小块 patch [13]。
对抗样本可泛化至现实世界。Kurakin et al. [7] 展示了对抗样本图像在打印出之后,即使在不同光线和方位情况下,对于分类器仍然是对抗的。Athalye et al. [3] 近期展示了可以 3D 打印的对抗物体,在不同的方位和大小情况下都可以迷惑网络。他们把对抗物体设计为正常物体的细微扰动(如,经过对抗性地扰动后乌龟被分类为步枪)。另一篇论文 [13] 展示了通过构建对抗眼镜来愚弄人脸识别软件的情况。最近,Evtimov et al. [4] 使用不同的方法构建被模型错误分类的停车牌,比如打印出像停车牌的大幅海报,或在停车牌上粘一些贴纸。在防御方面也有大量论文研究如何提高图像模型对输入的 L_p 小型扰动的对抗鲁棒性 [8, 12, 16, 2]。
如前所述,大部分之前的研究专注于攻击和防御输入的细微或不易察觉的改变。本文探索如果攻击者不再局限于不易察觉的改变会发生什么。作者构建了一种攻击方式,该攻击不试图用细微的方式改变原有物体,而是生成一个与图像无关、且对于神经网络极其显著的 patch。该 patch 可以被放置在分类器视野中的任意位置,使分类器输出目标类别。由于该 patch 与场景无关,因此它允许攻击者在没有光照条件、照相角度、被攻击的分类器类型,甚至场景中的其他物体的先验知识情况下,创建一个物理世界的攻击。
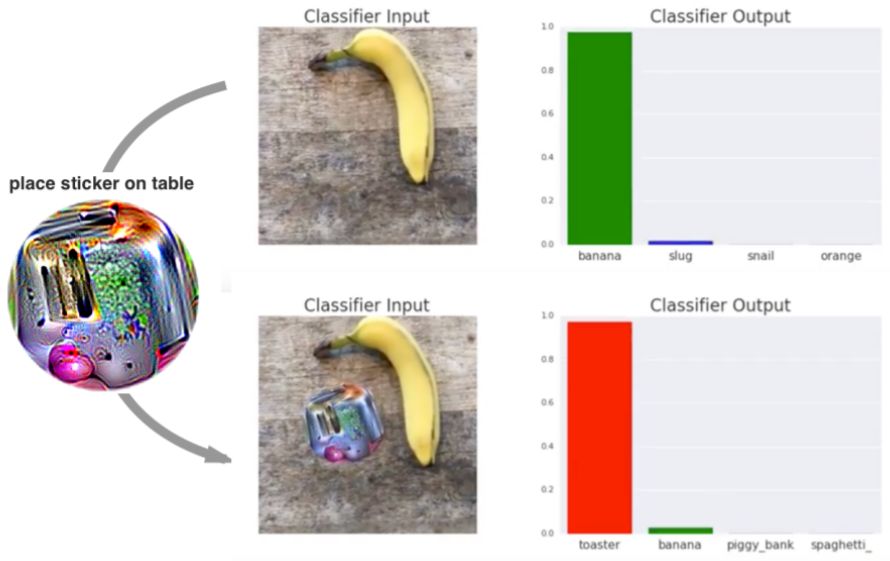
图 1:使用由白箱集成方法生成的物理 patch 对 VGG-16 进行现实世界攻击。把香蕉放在桌面上的照片输入 VGG-16 时,网络输出「香蕉」类的信度为 97%(第一行)。如果把一个目标类为「烤面包机」的贴纸放在桌子上,分类器输出「烤面包机」类的信度为 99%(第二行)。完整演示视频: https://youtu.be/i1sp4X57TL4。
这种攻击方式有重大意义,因为攻击者构建攻击时不需要知道所攻击的图像是什么。对抗 patch 被生成之后,可以在互联网上广泛传播,其他攻击者也可以打印和使用。此外,这种攻击使用了大幅度的扰动,而现存的防御小幅度扰动攻击的技术可能无法泛化到大幅度扰动的攻击。实际上,最近的研究表明在 MNIST 上进行对抗训练的当前最佳模型(相比使用不同的距离度量搜索邻近对抗样本进行训练,或在背景中应用大幅扰动进行训练),面对大幅度扰动攻击时仍然很脆弱。

图 2:patch 应用算子的图示。该算子以 patch、图像、位置和任意的 patch 变换(例如,比例和旋转)为输入,并将变换后的 patch 放到图像的给定位置上。然后该 patch 被训练以优化目标类的期望概率,其中期望值对任意随机的图像、位置和变换都是稳定的。

图 3:各种创建对抗 patch 方法的对比。注意这些成功率是按 patch 位于图像上的随机位置测量的。图中的每个点都是通过将 patch 应用到 400 张随机选择的图像的随机位置而计算的。图中测量了不同图像面积占比的的对抗成功率,每个比例都是在 400 张图像上独立地测试的。
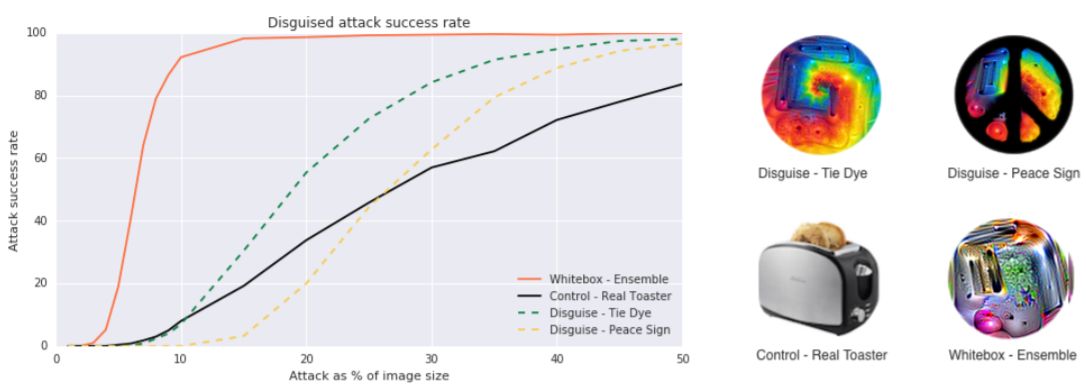
图 4:各种不同伪装的 patch 的对比。研究发现可以将 patch 进行伪装,并很大程度上保持其欺骗分类器的能力。

图 5:可打印的对抗 patch 的贴纸。为了得到最好的攻击效果,需要按上图所示保持贴纸在 20 度以内的垂直对齐。该 patch 通过白箱集成方法生成。研究观察到该 patch 某种程度上可迁移到第三方 Demitasse 应用(该 patch 并没有专门设计用于欺骗这个应用)。然而,为了有效地攻击,该 patch 的尺寸需要比图 1 中展示的 patch 更大,这正是第三节中描述的对模型的白箱攻击。
论文:Adversarial Patch

论文链接:https://arxiv.org/abs/1712.09665
摘要:我们提出了一种在现实世界中创建通用、鲁棒、针对性的对抗图像 patch 的方法。该 patch 是通用的,因为它们可用于攻击任何场景;是鲁棒的,因为它们在多种图像变换中都是有效的;是有针对性的,因为它们可以令分类器输出任意目标类。这些对抗样本可以被打印出来,添加到任意的场景、照片,并展示给图像分类器;即使 patch 很小,也能导致分类器忽略场景中的其它物体,输出选定的目标类。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com
点击「阅读原文」,在 PaperWeekly 参与对此论文的讨论



