在这篇文章中,剑桥大学应用数学与理论物理专业博士生孙浩介绍了自己过去三年的强化学习研究历程。
2019 年的 NeurIPS 有幸中了一篇 RL 的文章,那年我刚开始做 RL,首次投稿拿到了三个 7 分。第一次参加学术会议,怂到只敢远远看两眼 RL 圈里久仰大名的大佬们,心想等我再做出一些文章,就好意思去介绍自己的工作了。
2022 年的 NeurIPS 终于又是线下了,被 OpenReject 了两年的人终于也拿到了一个 OpenAccept,冬天在新奥尔良,这几年积攒的悔恨,希望能转化为对这次会议的珍惜。
终于熬过了 NeurIPS 的两周 rebuttal。每天中午起床,跑实验写回复到四点钟睡觉,最后的一天为了调一个在剑桥组里二作(非 RL)文章的大规模实验通了个宵,最后实验也没来得及跑出来。
我于是更加怀念自己在 HK 自由自在做 RL 的那几年,有用不完的机器(虽然写着 shi 一样的 code)总是早早地跑完了实验(然后为自己的 poor writing 以及 boring story 着急)。
从三年前只需要一页纸到如今的 openreview 上辩论厮杀,我心爱的几篇文章已经被拒绝过太多次(以至于我通常称 open review 系统为 openr eject),好多次看着心爱的工作被 reviewer 骂得体无完肤总想要放弃,但最后还是忍不住熬大夜掉一把把头发也要咬着牙把 rebuttal 写了。想想也挺壮烈:你可以拒我,但不能让我对自己的研究失去热爱,我花了心血和时间的心头所爱,是探索也是信仰。
这次过后有些工作应该不会投了(因为很多实验 baseline 需要更新但没时间追了),想借此机会记录下来。回过头来看这些工作,如果最终都停留在 Arxiv,那也真算是成了 Arxiv 民科了。
另外 review 感觉越来越 toxic 了,这一次 review 我就见到了:
1. 让我比较 4 月,5 月,7 月 Arxiv paper 的;
2. 跟我说我没有为算法设计一个环境,在 general case 上表现一般没有说明算法优势的(我们 sample efficiency 高了一倍,asymptotic performance +6/37/50%);
3. 问我 method 中的一个部分是不是发挥了全部作用,质疑我们方法不如 random baseline 的(我们 maintext 中放了这部分的 ablation study)。
这篇小作文的主要目的是记录心路历程,各个 idea 的契机和探索的过程,希望过后某天回过头来看研究刚刚开始的这些工作还可以为当年的 aha moment 欣喜,也算值得。
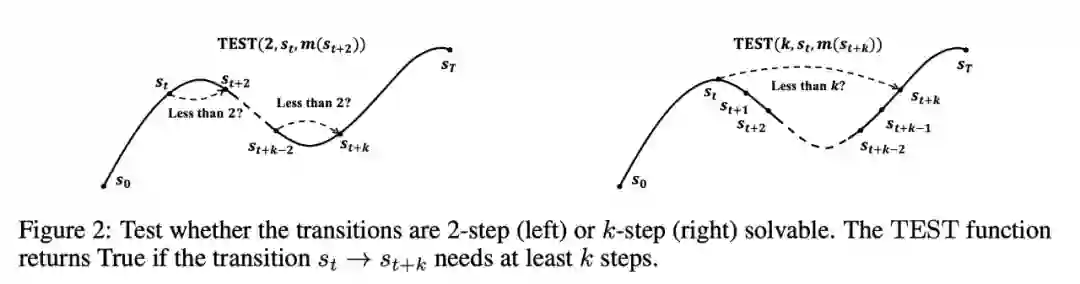
PCHID: 用监督学习解决 GCRL 问题,所有的 GCRL 都可以看作是 state-space 中的 navigation task
论文链接:https://proceedings.neurips.cc/paper/2019/file/3891b14b5d8cce2fdd8dcdb4ded28f6d-Paper.pdf
ESPD: 用监督学习解决更难的 GCRL 问题并且进一步提升效率,state-space navigation task 的目标是缩短 first hitting time
论文链接:https://arxiv.org/pdf/2004.12909.pdf
ZOSPI: 用监督学习解决一般的 RL 问题,通过 zeroth-order sampling 的方法代替 policy gradient 在 continuous control task 中竟然效果拔群 *
![]()
论文链接:https://arxiv.org/pdf/2006.06600.pdf
![]()
论文链接:https://arxiv.org/pdf/2202.04478.pdf
NPSCO: 生成一系列的 diverse policy。
![]()
论文链接:https://arxiv.org/pdf/2005.10696.pdf
MOPA:Safe-RL 的极简化解决方案,通过解决等价的 Early-Termination 解决 Safe-RL 问题
彩蛋:这篇文章里我们用三段论提出用 Meta-RL 的思路来解决一般的强化学习问题,在 DMControl 的任务中刷了榜;后来发现 tianwei 正好做了一篇 POMDP 的工作,和我们的发现非常相似。
![]()
论文链接:https://arxiv.org/pdf/2107.04200.pdf
Reward Shifting: 简单地给 reward function 加一个常数,等价于不同的 Q 网络初始化!
这个思路可以拿来解决 offline conservative exploitation, online curiosity-driven exploration 和 sample-efficient continuous control。
特别地,我们解释了为啥之前的 curiosity driven method 通常都是 policy-based 的,因为 RND 放在 DQN 上会起反作用。
![]()
论文链接:https://openreview.net/pdf?id=CNY9h3uyfiO
-
发现 PCHID 背后的思想已经被人做了并且称为 hindsight,但我用 supervised learning 搞 RL 仍然很 novel 的时候;
-
在 PCL 的阳台上和丁哥打电话,厘清了 PCHID 的动态优化对应的时候;
-
抱着随机过程的书,想明白 state-space navigation 本质上就是缩短 first hitting time 的时候;
-
为了快速迭代,设计的简单 Maze 环境在我尝试了所有 SOTA 算法数月都无法解决(SAC, TD3, PPO 全都试了),然后被 ZOSPI 解出完美方案的时候;
-
和 Reward Shifting 工作里和 yangrui 讨论过后想清楚了 reward shifting 如何等价于初始化,并且验证了关于 RND+DQN 实验结果预期的时候。
【PCHID】- NeurIPS’19 — 用监督学习的范式解决强化学习问题
![]()
这是我开始 RL 旅程之后的第一篇工作,当时八月份刚刚来到 MMLab,对 RL 一无所知,林老师说让我先画上两个月的时间多读文章,了解这个领域。RL 那个时候还没太多资料,网上的文章多数从理论入手,不同的文章里记号也总是乱七八糟。现在想想能把文章的脉络梳理清楚,把 notation 用得前后一致并且每个都标记清楚定义出处,已经很难得了。那个时候看 Policy Based 那些文章分不清 TRPO 里优化的都是些什么东西,看 DDQN 也搞不懂这些玄乎的 Dueling 到底有什么作用,自己比葫芦画瓢写了个 DDPG 结果发现连 Pendulum 都跑不出来。
那是我第一次对 RL 感到绝望(当然后面发现这种绝望经常有,上一次有好像还是在上一次)
十月份周老师从 MIT 回到了 MMLab,感兴趣的方向里也有 RL,那个暑假周老师和 bowen 做了一篇非常喜欢的 navigation 工作,于是我有了第一个 topic:去试着做 navigation 的 RL agent。当时周老师给我看的文章是 value iteration networks,现在隐约还能记得它讲的是如何把一个网络设计得和 value iteration 相对应,然后拿来搞了 grid world 的 navigation。我对网络设计的魔法一无所知,复现这篇工作的时候让我想到好像可以用监督学习的 extrapolation 能力来进行 navigation,于是这篇工作给我在 HK 三年的研究埋下了一颗种子。
经过简单的尝试,我发现用监督学习重复随机探索的路径,可以给 agent 很强的泛化能力——我几乎自己发现了 Hindsight Experience Replay——找到这篇文章的时候我十分失落,一度觉得自己这个 idea 算是被做掉了,感叹生不逢时。事情的转机在于 dive deeper,仔细想来,我一来是用监督学习,二来不是做 relabel,而是用递归的思想来学最优子策略,和山神偶然聊到了一句解析延拓,于是这篇工作拥有了雏形。
后来丁哥带我想清楚了动态优化视角下的对应,稿子成型前我意识到的所有 Goal-Conditioned RL 任务都可以理解为是在状态空间做 Navigation。
现在想来这篇工作真的是种种机缘巧合,让初入 RL 世界的我找到了一个出发点。
【ESPD】: Evolutionary Stochastic Policy Distillation. — 增强版的 PCHID;
【SPLID】:ESPD 的理论补全;
ICLR’22: 【WGCSL】
![]()
PCHID 过后一个自然的问题是:我们能不能替换掉这个 test function?能不能摆脱 Recursive Learning 的束缚?ESPD 给了这两个问题以肯定的回答(事实上只给了后一个问题肯定回答,test function 的替换包括一些理论基础是后来 zhihan 在去年的暑假完成的。)
这篇文章的思路其实在 PCHID rebuttal 的时候就基本完成了,投稿 2020 年初的 ICML 的时候某种意义上是糟了黑手。一月份完成的投稿,在 review 期间被问为什么没有 cite / 对比 Sergey Levine 组在 2019 年十二月底在 ICLR 上被 OpenReject 的工作(这篇就是后来的 GCSL:https://openreview.net/forum?id=ByxoqJrtvr&referrer=%5Bthe%20profile%20of%20Dibya%20Ghosh%5D(%2Fprofile%3Fid%3D~Dibya_Ghosh1))
事实上我们后来进行了对比,performance 领先 GCSL 一大截。
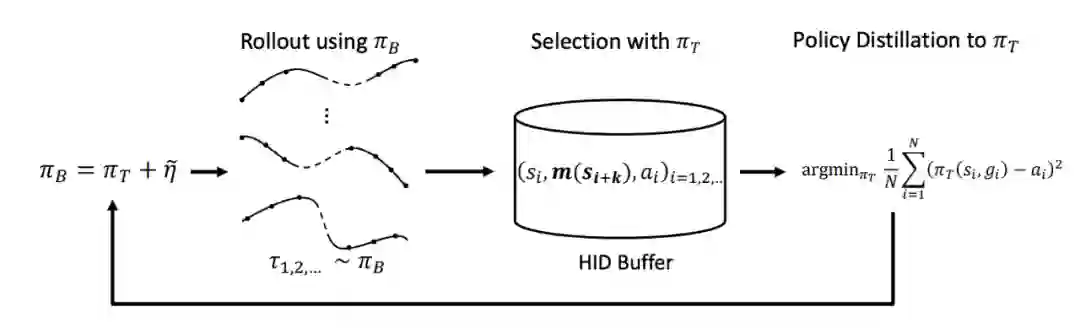
ESPD 更重要的 insight 是:在用监督学习完成 RL 任务的时候,我们没有 value function,事实上在进行的是一种序关系的寻找:如果我们总能找到一个策略使得它比之前的策略效果好,那么就可以通过监督学习的方式让我们的策略网络逼近这个新的策略。---—这种基础思想也是 TRPO/PPO 所采用的。
基于这种 “有一个 behavior policy 进行(随机)探索”, 另一个“policy network” 进行监督学习的范式,我给它起了个名字叫做“Evolutionary Stochastic Policy Distillation”, 前半部分 ES 是说通过随机探索寻找到更好的策略,这是进化算法的思想,后半部分 PD 表明了学习方法是监督学习。
【ZOSPI】:在 ESPD 之后,很自然的一个问题是是否可以把这种思路推广到更一般的 RL 任务中?
![]()
ZOSPI 直接进行全局最优 Action 的寻找
在 ESPD 和 PCHID 里,我们解决的是 Goal-Conditioned RL,这类任务另一种名字叫做“reward-sparse tasks”,也就是只在完成任务的时候有个奖励。也因此,它等价于「在 state space 中做 navigation」—— 找到 goal point,到达这个 goal point 就是所有需要做的事情。因此,我们对更好的 policy 的寻找事实上就是在缩短状态空间中的首达时(first hitting time)。
在这个过程中,我们只有一个 policy network,而没有 value network——因为在这种问题中,value network 能提供的价值很少(当时是这么想的,事实上这也不对,比如 HER 里面的 value network 还是能学到东西的,只是在特别的 reward 设计下——这也给了后来 reward shifting 一篇文章以启发,这个留作后话)。
但是在更一般的任务中,我们不是为了达到某种状态,而是要不断优化策略,达到更高的 cumulative reward (sum over different states in sequence)。
那么如何把 ESPD 这种监督学习,进化策略的思想推广到诸如 MuJoCo Locomotion 这些一般任务中呢?
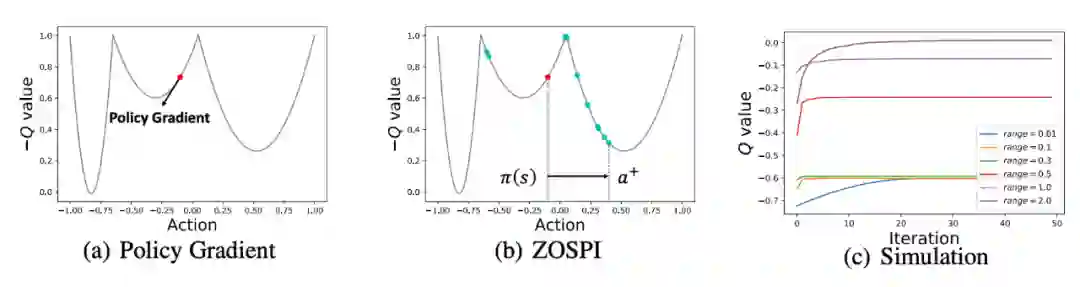
我们给出的答案是:通过零阶优化,直接在动作空间中寻找 value network prediction 值最大的点,进行全局的 exploitation!
基于这个思想,我们提出了 ZOSPI,它是一种通过 Zeroth- Order Optimization 代替 Policy Gradient 的方法,最大的优势在于可以不依赖于 value network 的局部信息,而是全局地寻找最优点。然后,对这些找到的 high-value actions 进行监督学习。
除了全局探索的优越性之外,由于我们的策略优化基于监督学习,可以很自然地兼容许多 Policy Gradient 方法无法适用的“拓展插件”,比如可以用混合密度网络 Mixture Density Networks,可以用 Non-Parametric 方法例如 Gaussian Processes,在此基础上更可以引入 UCB Exploration,等等。
这篇文章完成在 20 年中旬,第一次在自己创造的 diagnostic 环境中调出能找到全局最优解的策略的那天我开心极了——它正是我的 ZOSPI。这种解决了难题的快乐远远超过为了某种方法设计一个环境,然后在这个环境上把其他方法都搞崩。于我而言,这样的 Aha-Moment 是探索和研究最大的快乐。
讽刺的是,这个让我获得了巨大开心的环境后来成为 ZOSPI 被拒稿的理由:最初我们把这个 diagnostic 环境放在 Main Text,reviewer 愣是不信其他方法都不 work(提交了 code),说这个环境不能说明问题。于是我们把它放进到了 appendix,maintext 只留了 mujoco。
又来了一位审稿人说 MuJoCo 已经成为了 RL 的 MNIST,已经完全得到解决(这显然是个错误的论断),不能当作 benchmark(与此同时大量连 MuJoCo 五个环境跑不完的文章比比皆是)。
这次 NeurIPS 这篇投稿再次被拒,拒稿理由是:我们的环境不是为方法特别设计的,无法凸显方法的优越性。而事实上我们取得了超过两倍的 sample efficiency 改进。
我在 open review 回怼了这个审稿人,说我们不想做为了锤子找钉子的事情。
如果在 SAC 和 TD3 优化过的环境上和它们正面刚,不能证明有效,而是要找到一个环境证明方法有效,我不知道这算什么有效。
【NPSCO】:如何寻找到一群充满生物多样性的智能体?
![]()
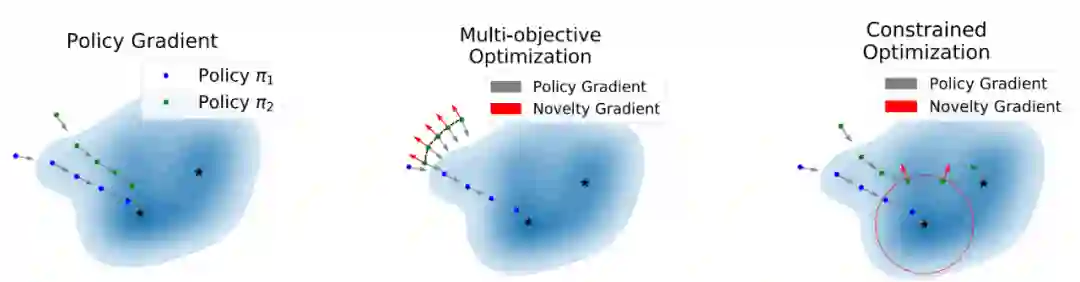
通过 Constrained Optimization 而非 Multi-Objective Optimization,原始任务上的 performance 更能得到保证
最早开始这份工作是注意到一篇 ICML 的投稿,它给 policy learning 引入了一个 diversity reward,从而可以用不同的方法解决同一个任务。
我们的改进主要基于约束优化:如果简单地将这个问题建模成多目标优化,那么这个 diversity reward 很容易喧宾夺主。为了保证在原始任务上的性能,我们提出通过约束优化的方式来进行求解。
这也就引出了另一个更广泛的问题:如何在 RL 中求解约束优化?
【MOPA】:一种在 RL 中求解约束优化的极简化思路
![]()
在 DMControl 上的拓展实验表明,将 Meta-RL 里好用的思路用到普通 RL 里也能增加学习效率
在这篇文章中我们转而关注更一般的 RL 约束优化问题——通常它被 formulate 成安全约束,也即 Safe-RL。在之前的工作中,人们通常用 Constrained MDP 来定义问题,之后通过拉格朗日法进行求解。(最近看了一些 model-based 方法,其实 planning 和传统 control theory 中解决这一问题的思路更优雅简洁有效)。
但对于 Model-Free 方法来说,从 2018 年起兴起的大杀器——TD3/SAC 以及它们背后的 off-policy learning 却一直由于和 CPO 不兼容而没有在 Safe-RL 中施展拳脚。
我们的问题是:是否可以把更高效的 Off-Policy learning 引入 Safe-RL?有没有比 CMDP 更简洁有效的解决思路?
在 MOPA 中,我们给两个问题以肯定的答案:首先,我们从问题定义的角度证明了 CMDP 其实等价于 Early Termitted-MDP。背后的思想是:人们从来不希望通过交通事故学会如何开车,人们只从正确的例子中就可以学会避免交通事故。通过这一等价性,Constrained RL 的问题就被转化成了对应的普通 MDP(带一个吸收态),那么原则上来说,任何的 off-policy 方法都可以拿来用了。比如 TD3。
那么,我们是否可以进一步提升性能呢?由于约束优化问题的复杂性,许多带有 budget 的问题都是 Semi Markovian 的。我们通过一个三段论的逻辑推演提出了用 Recurrent Network 为基础的 Meta-RL 来作为解决方案。
作为验证,我们在十个环境中进行了实验,囊括了不同类型的 SafeRL 任务。
此外,为了验证方法的 generality。我们在 DMControl 上刷了榜,在 16 个任务中,我们使用同一组参数,只有三个没有得到改进 —— 谁说在 RL 里 network 的设计不重要?
Recurrent Model is All You Need!!!
有趣的巧合是 Tianwei 在 ICML’22 一篇与 Benjamin, Ruslan 合作的关于 POMDP 的工作有相似的发现(https://arxiv.org/pdf/2110.05038.pdf )
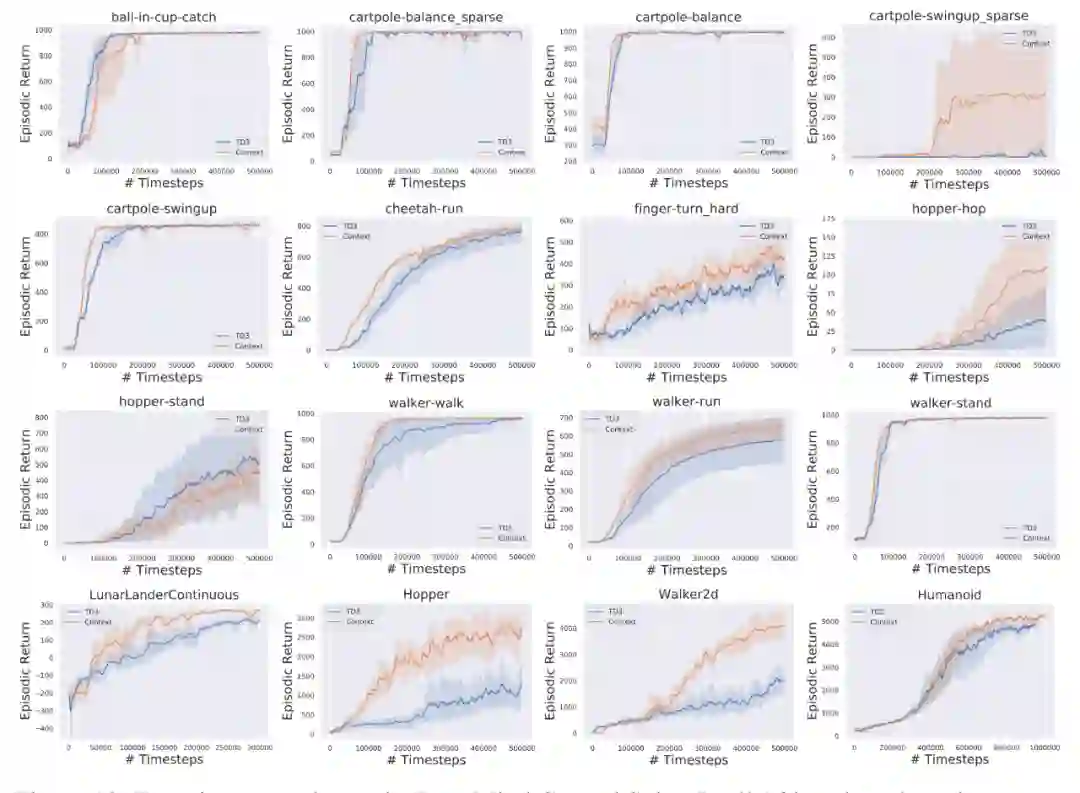
【Reward Shifting】-NeurIPS22:简单的 reward 线性变换能给我们带来什么?
![]()
给 reward 减去 constant 带来 better exploration,加上 constant 带来 better exploitation
最早是在做 PCHID 的时候,我发现 PPO 在 FetchReach 上的性能非常依赖于 reward 的值:用 + 10 和 0 做成功的 reward 会有巨大的 performance 差异。
后来在我们研究 Constrained-RL 的时候,在 Humanoid 这个环境中也观察到一个有趣的现象:如果我们去掉 Alive Constraint(center of mass 无需高于某一 threshold),智能体极难学出跑步的动作,作为公平的对比,我们给 constrained task 也去掉了 alive bonus(不然的话二者的 reward mechanism 不一样,无法公平对比)。结果发现去掉了每步 + 5 的 reward bonus 之后,1M performance 直接从 5k 涨到了 8k。
为了解答这个问题,我调研了各种 reward shaping 的文章,但没有工作给出 principal 的 reward shaping 指导,也没有人解释过类似的问题。我于是最开始将这个 topic 定成了 Coach-RL,某种意义上是训练一个 Coach Network 给 Policy Network 一个 reward,以进行学习的加速。
后来还是和 YR 讨论的时候真正的想通了:这里重要的不是给某个环境找到一个最优的 reward,而是一个重要而极容易被忽略的 insight:将 reward 整体进行 shift(也即每一步都加或者减一个常数)等价于使用不同的初始化。
我们简单考虑一个 tabular 的情况:假设某个 hard exploration task 原本设计的 reward 都在 0 左右,那么如果我们给 reward function 减去一个常数(比如 - 100),那么任何被访问过的 state-action pair 都会得到一个非常小的价值估计——这是我们的优化目标决定的——但凡出现在我们 replay buffer 中的 state-action,它们的价值都不会很大,因为他们的价值 prediction 要对着 -100 + next Q 做 regression。
相比之下,那些没有到过的 state-action pair 由于不会出现在 replay buffer 中,在被访问的时候,它们的值应该还是初始化附近(通常来说的网络初始化都在 0 附近),因此,他们的价值要比被访问过的 state-action 高很多,这也就带来了 curiosity-driven exploration 的行为!
值得一提的是,我们这里的 curiosity 主要是由于网络初始化带来的,而不是手动加上的 bonus,这两者存在一个鸡生蛋与蛋生鸡的问题:如果是手动给没去过的点加 bonus,那么首先 agent 要碰巧到达这些点,才能获得 bonus,进而加强对相关区域的探索;而在我们的方法中,curiosity 是由于网络初始化决定的,在到达新的 state-action 之前,由于初始化,这些位置已经获得了很高的 bonus,所以 agent 更有可能直接对它们进行访问,而无需这个 “碰巧走进” 的步骤!
更一般的,我们把类似的思想推广到了 offline RL 的 exploitation 中:和 exploration 中需要减去一个 constant 导致 curiosity- driven exploration 对应的是,如果我们加上一个 constant,网络就会出现 conservative 也就是 exploitation 的行为,这正是 Offline-RL 中所需要的。
这篇工作里最大的快乐是我们在 DQN+RND 上的推广验证,(好像 proof-of-concept 实验 work 的时候是最快乐的)。
在确定了 reward shifting 和 initialization 之间的等价性以后,一个相关的问题是:如何理解之前的 curiosity-driven exploration bonus?例如在 RND 中,一个随机固定网络和另一个可学参数网络之间的差值作为 exploration bonus 被加到原始的 reward 上,这样的 reward bonus 会带来怎样的影响?
根据我们的 insight,这种大于零的 reward shift 会给 value-based DRL 带来 pessimistic exploration,而不是 curiosity,这里又回到了那个 “先有蛋还是先有鸡” 的问题:这种 curiosity bonus 本身会导致不断地重复访问已经访问过的 state-action:因为在 function approximation 中它们的估计值比初始化值高——直到这些 state-action 的价值被不断修正(因为 bonus 会随着访问次数的增加而衰减),才会更多地访问新状态。
这显然和 RND 增强 exploration 的设计初衷是矛盾的,解释了为什么 RND 没有被加在 DQN 而是 PPO 上。实验结果也验证了这一点:原始的 RND + DQN 效果很差,但是如果我们把 RND 的 bonus 设置为负值,就可以发挥显著作用了。
这篇乱七八糟写了也将近一万字,感觉什么都提了一嘴又什么都没讲清楚。
立个 Flag,十月份有机会一定好好把欠下的坑都填了 Orz。
孙浩本科毕业于北京大学,硕士毕业于香港中文大学多媒体实验室,师从周博磊教授和林达华教授,现就读于剑桥大学应用数学与理论物理专业,研究方向为强化学习。
原文链接:https://zhuanlan.zhihu.com/p/565737585
声纹识别:从理论到编程实战
《声纹识别:从理论到编程实战》中文课上线,由谷歌声纹团队负责人王泉博士主讲。目前,课程答疑正在持续更新中。
课程视频内容共 12 小时,着重介绍基于深度学习的声纹识别系统,包括大量学术界与产业界的最新研究成果。
同时课程配有 32 次课后测验、10 次编程练习、10 次大作业,确保课程结束时可以亲自上手从零搭建一个完整的声纹识别系统。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com