怎么在视频标注上省钱?这里有一个面向视频推荐的多视图主动学习
机器之心发布
IJCAI 2019 已于 8 月 10 日至 16 日在中国澳门隆重召开,本届大会共收到 4752 篇有效提交论文,收录 850 篇,接收率为 17.9%。据机器之心了解,阿里文娱摩酷实验室共有 5 篇论文被接收。

链接:https://www.ijcai.org/proceedings/2019/0284.pdf
一、 背景
视频推荐系统在视频网站的个性化推荐任务中扮演着重要角色。在基于内容的视频推荐算法中,针对每一个用户-视频对,推荐模型都会给出一个预测值,表示用户观看这个视频的可能性。然后根据此预测值的大小对视频进行排序推荐 [1]。
在基于内容的推荐算法中,对视频内容进行合理的表征至关重要。视频含有视觉、文本等多个视图。视频的视觉视图是视频的帧,而视频的文本特征是视频的文本信息,例如标题、标签等等。相对于低级别的视觉特征而言,文本特征含有较多的语义信息,能够更好的表征视频的内容。因此大多数视频推荐系统都通过来自视频文本信息的特征来表示视频内容。
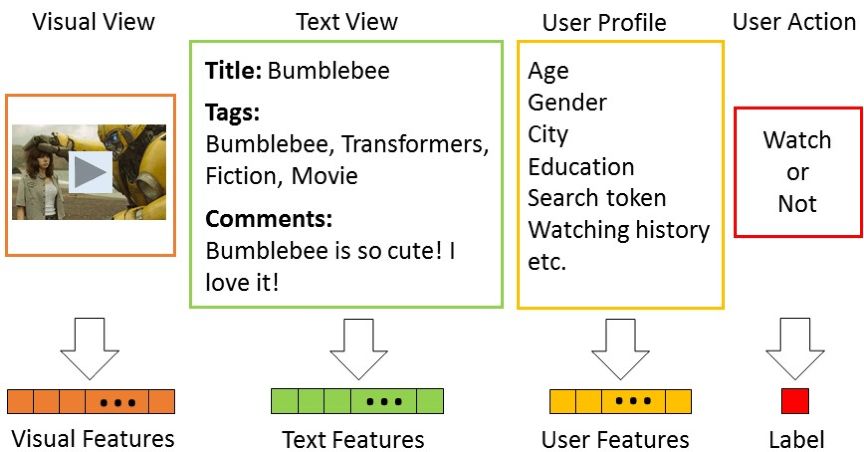
图 1 含有多个视图的视频数据
图 1 是一条用户观看记录的主要组成部分。其中,视频的文本特征和用户特征联结起来,输入到分类器中,而标记则被当作监督信息来训练分类器。视觉特征由于其低级别的语义信息难以被建模而被舍弃。
随着移动设备的普及,视频的制作和传播更为便捷,用户生成内容(UGC, user generated content)在视频数据库中占了很大的比重。这些视频的文本信息是用户在上传的时候自己给出的。有的用户不愿意给出太多的内容描述,导致可用的文本信息较少;而有的用户会给出错误的标签甚至是具有欺骗性的标题。这些情况导致了大量视频的文本信息质量较差。而要想训练一个有效的模型,训练数据的质量至关重要。因此,就需要人为地对视频的文本信息进行较为精细化的标注,从而提升训练数据的质量。然而,视频的标注过程费时费力,对海量视频数据进行标注必然会导致高昂的标注代价。
本文通过主动学习的方法,选择对模型训练最有帮助的视频进行文本信息的标注,能够在一定程度上降低视频标注代价。
二、 方法
1. 主动学习
监督学习算法在训练过程中往往需要大量有标记的训练数据。但是在现实中,数据的标记并不是天然存在的,而需要人来进行标注。数据的标注代价有时是极为昂贵的。标注 ImageNet 这样大规模的数据集会花费高昂的时间和人力成本。此外,对于医学及生物信息学等专业领域而言,只有具备专业知识的人才才能够胜任这样的数据标注工作,标注成本也会很高。主动学习是减小数据标注代价的有力工具。
主动学习是一个迭代的过程,它不断地从未标注数据中选择那些标注以后对当前模型性能提升而言,潜在收益最大的样本,将这些样本交给专家(oracle)去标注,以扩大训练集合并训练新的学习器 [2]。主动学习中最为重要的是选择标准的制定,有效的选择标准能够通过较少的查询次数快速地提升模型性能。
2. 视觉到文本的映射
主动学习中往往需要将未标注数据输入当前模型进行一次预测,以计算模型对样本的不确定程度。在视频推荐任务中,模型是基于文本特征训练的;而未标注视频的文本特征需要查询以后才能获得。这意味着,对于未标注视频而言,我们无法用现有模型对其标记进行预测从而计算不确定度。注意到,视频的视觉特征可以通过预训练的深度神经网络直接提取 [3],因此不需要耗费人工代价。因此,本文通过一个从视觉特征到文本特征的映射函数,来估计真实的文本特征,根据这个估计的文本特征来计算未标注视频的信息量大小。这个映射函数记为 V2T(Vision to Text Mapping Function)。
将已标注视频的视觉特征作为输入,文本特征作为目标,可以训练一个初始的 V2T 模型。直接最小化如下的重构误差来训练这样的映射函数:
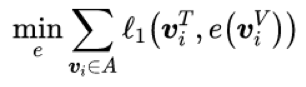
其中,e 为 V2T 映射函数,A 为已标注视频集合,v_i^T 为真实文本特征,e(v_i^V) 为根据视觉特征估计的文本特征。
考虑到在初始阶段,只有少量的已标注视频,V2T 模型 e 的效果势必不如人意。注意到对于所有的用户-视频对,他们的标记总是存在的。受到文献 [4] 的启发,本文利用这些标记信息来辅助 e 的训练。
假设 f 为推荐算法用的分类模型。由于分类模型 f 是从文本特征到标记空间的映射,因此在 f 已知的情况下,也可以反过来根据已有的标记信息来优化生成的文本特征。具体地,对于一个用户记录,视频的视觉特征记为 v_i^V,用户特征记为 u_j,用户行为标记为 y_ij。\hat{v}_i^T 表示由 V2T mapping 生成的文本特征的估计。假定 f 是可靠的,如果预测标记和真实标记相去甚远,那么很有可能是由于 V2T mapping 恢复出来的文本特征\hat{v}_i^T=e(v_i^V) 不准确所导致的。基于这个想法,本文通过最小化以下的经验损失来优化 V2T mapping:
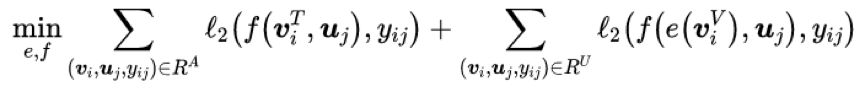
其中第一部分表示对已标注视频的分类损失。第二部分是对未标注视频的分类损失,通过最小化这一项,映射函数会更新它的权重以确保分类模型根据 e(v_i^V) 得到的预测标记和真实的用户行为标记保持一致,从而优化 e。
最后通过一个超参数\lambda 将这两部分结合起来:
第一项要让已标注视频的预测文本特征和真实文本特征尽可能一致,主要负责优化 e。第二项要让已标注视频的预测观看标记和真实观看标记尽可能一致,主要负责优化 f。第三项则是要保证对于未标注视频,根据估计文本特征预测的观看标记和真实的观看标记尽可能一致,旨在将真实的观看标记当作监督信息来辅助 e 的训练。模型的框架参见图 2。
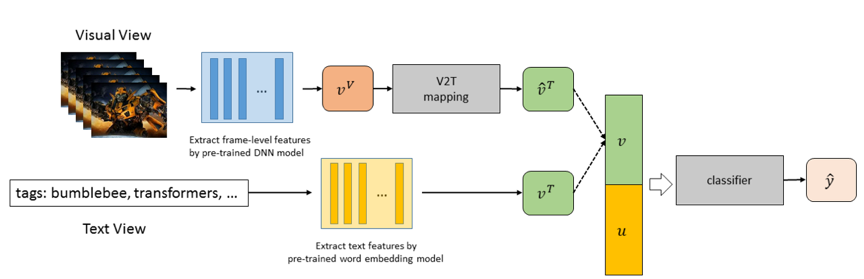
图 2 模型框架
3. 查询选择标准
为了从未标注视频中选择最具信息量的样本,我们设计了新的适用于视频推荐任务的样本查询准则。
首先,本文考虑了不一致性准则。对于一个未标注视频而言,存在多条与之相关的用户观看记录。如果在这些记录中,大部分观看标记都被预测错误,那么很有可能是估计的文本特征不准确。因此,这些视频的文本信息更需要被查询。具体地,不一致性定义如下:
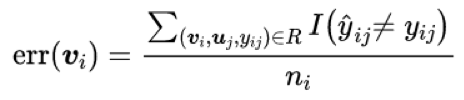
其中,n_i 表示与视频 v_i 相关的用户记录数量,分子表示标记被预测错误的记录数量。这个值越大,表示生成的文本特征越差,这个视频也就越需要被查询。
其次,本文还考虑了视频的观看频率。有的视频比较热门,而有的视频比较冷门。查询一个被很多用户观看过的视频,可以为分类模型的训练增加更多的训练数据,模型的提升效果也更明显。我们将观看频度归一化到 [0, 1] 之间得到第二个指标 freq_i。
我们简单地将两部分相乘来计算一个视频的信息量大小:
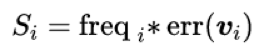
三、 实验
作者在优酷推荐数据集上做了实验来验证算法的有效性。
这个数据集包含三个子数据集。下图是不同选择方法的学习曲线。所用的指标是模型在测试集上的 AUC。
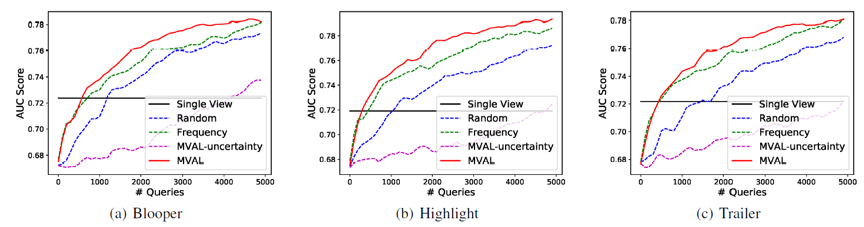
可以发现,如果使用视觉特征,即使用上全部的数据,AUC 还是会很低。只用 frequency 指标也会比 random 要好,这说明查询 popular 的视频是有用的。本文提出的 MVAL 方法在三个数据集上都具有最好的性能。
较长的视频往往要花费更多的时间来标注,因此,作者还考虑了代价敏感的主动学习选择策略。将此前提到的信息量除以视频的时长作为代价敏感的主动学习样本选择策略。横坐标由原来查询过的视频数量变为查询过的视频时长。
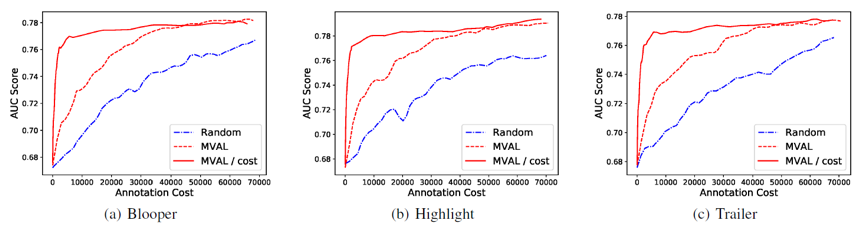
从图中可以看出,代价敏感的主动学习方法能够进一步节省标注代价。
四、 结论
该论文提出了一种新的主动学习框架,在这个框架中,查询对象是样本的一个缺失的视图而非传统的标记。针对这种多视图的主动学习问题,论文提出了 MVAL 算法,充分利用了廉价的视觉信息以及标记中的监督信息,综合考虑了不一致性和频率两个查询指标。实验证明,MVAL 能够有效节省视频推荐任务中的数据标注代价。
参考文献:
[1] Peng Cui, Zhiyu Wang, and Zhou Su. What videos are similar with you?: Learning a common attributed representation for video recommendation. In Proceedings of the ACM International Conference on Multimedia, MM'14, pages 597–606, Orlando, FL, USA, November 2014.
[2] Burr Settles. Active learning. Synthesis Lectures on Artificial Intelligence and Machine Learning, 6(1):1–114, 2012.
[3] Joonseok Lee, Sami Abu-El-Haija, Balakrishnan Varadarajan, and Apostol Natsev. Collaborative deep metric learning for video understanding. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, KDD 2018, pages 481–490, London, UK, August 2018. ACM.
[4] Sheng-Jun Huang, Miao Xu, Ming-Kun Xie, Masashi Sugiyama, Gang Niu, and Songcan Chen. Active feature acquisition with supervised matrix completion. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, KDD 2018, pages 1571–1579, London, UK, August 2018. ACM.
阿里巴巴 IJCAI&KDD 论文分享会将于 8 月 24 日在北京举行,报名请点击「阅读原文」。



