Memory Transformer,一种简单明了的Transformer改造方案

介绍
Transformer在广泛的自然语言处理和其他任务中非常成功。由于具有自我注意机制,可以训练Transformer层以使用在整个序列上聚合的信息来更新每个元素的向量表示,在编码结束时为每个token生成了丰富的上下文表示。但是,在同一向量中组合本地和全局信息有其局限性。全局特征的分布式存储会使其“模糊”,并且获取它们会变得更加困难。Transformer的另一个众所周知的缺陷是注意力跨度的缩放不佳,这损害了其在长序列中的应用。
本文提出并研究了「MemTransformer」(Memory Transformer),一种简单明了的Transformer改造方案,有可能解决上述问题。通过在输入序列的开头添加 [mem] tokens 来增强Transformer,并训练模型看看它是否能够将它们用作通用内存存储。为了评估提出的内存实现的能力,进一步研究了「MemBottleneck」模型,该模型消除了序列元素之间的注意力,从而使内存成为访问序列全局信息的唯一通道。
最近的一些方法试图通过在其体系结构中添加一些类型的内存元素来解决这个问题:
-
「Transformer-XL」
提出「片段级递归机制(segment-level recurrence mechanism)」,引入一个记忆(memory)模块(类似于cache或cell),其中在前段中获得的隐藏状态会受到重视,并进行重用以更好地对长期依赖性进行建模,从而防止「上下文碎片」。
-
「Compressive Transformer」
压缩Transformer保持对过去激活的细粒度内存,然后将其压缩到更粗的压缩内存中。
在Transformer-XL的循环存储方法中,旧存储器被丢弃,从而能够以先进先出的方式存储新存储器。此方法仅考虑新近度,而不考虑可能会丢弃的信息的相关性。
「压缩Transformer」通过添加新的「压缩内存」(而不是丢弃旧内存的粗略表示)来建立在内存概念的基础上。作者尝试使用多种替代功能来压缩,最后选择一种「注意力重建损失」,该「损失」会丢弃网络未参与的信息。压缩内存的使用显示了对不频繁单词建模的巨大改进,并具有网络学习通过压缩机制保留显着信息的经验证据。
最新的具有全局表示的Transformer:
-
「Star-Transformer」 -
「Longformer」 -
...
所有这些架构都减少了对局部或模式注意力的完全自我关注,并将其与稀疏的全局关注瓶颈相结合。例如,Longformer使用选定的标记(例如[CLS]或问号标记)来累积全局信息并将其重新分配给序列的所有其他元素。MemTransformer和MemBottleneckTransformer模型可以看作是此类模型的更一般的极限情况。两者都有可以存储全局信息或本地信息副本的非特定[mem] token。MemTransformer对内存+输入序列具有完全的自我关注。相比之下,MemBottleneck在输入序列和内存之间具有双向注意力,而在序列标记之间没有注意力。
模型
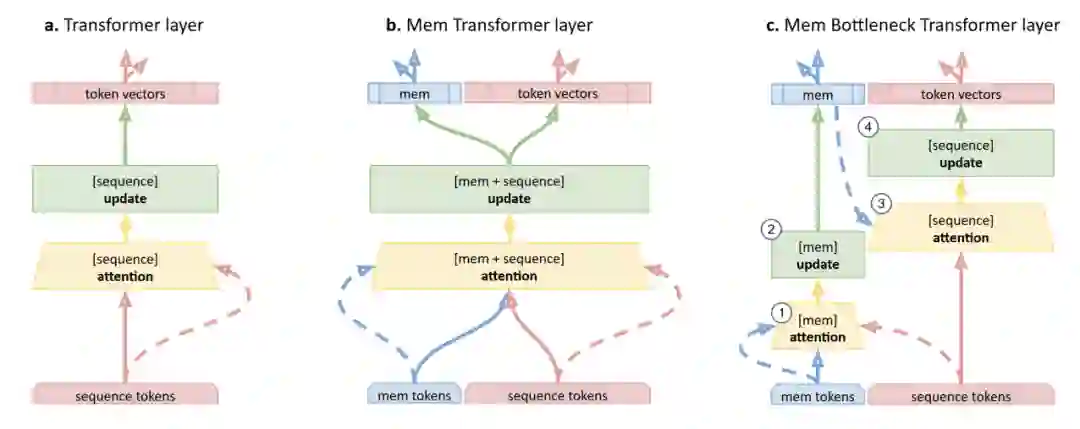
对Transformer体系结构的内存修改。
-
(a)Transformer层。对于序列中的每个元素(实心箭头),自我关注会从所有其他元素(虚线箭头)产生汇总表示。然后,通过一个完全连接的前馈网络层来组合和更新此聚合和元素表示。 -
(b)Memory Transformer(MemTransformer)为输入序列添加专用的[mem]令牌。使用标准的Transformer层处理此扩展序列,而[mem]和输入的其他元素之间没有任何区别。 -
(c)内存瓶颈转换器(MemBottleneck Transformer)使用[mem]令牌,但分隔内存和输入注意流。第一步,更新(mem)令牌的表示(2),同时注意范围(1)覆盖序列的存储段和输入段。然后,仅使用内存注意事项(3)更新(4)输入元素的表示。因此,信息流仅通过存储器分配给元素的表示。
Transformer 结构
原始的Transformer架构的核心是一个scaled dot-product attention:
Transformer采用多头注意力:
然后,具有剩余连接的多头注意子层的输出被标准化。然后是带有剩余连接的标准化前馈子层:
计算自我注意的过程可以看作是两步处理流程(见图1a):
-
「Self-attention」:计算序列中所有元素之间的注意力。 -
「Update:」 对于序列中的每个元素,聚合所有其他元素的加权表示并执行进一步的元素方式转换。
Simple MemTransformer
将m个特殊的[mem]token添加到标准输入(请参见图1b),然后以标准方式对其进行处理。输入向量 成为存储token向量 和原始输入token向量 的拼接。
该修改可以独立地应用于编码器和/或解码器。Transformer 的其余部分与处理扩展输入的多头注意层保持不变。
MemBottleneck Transformer
在MemTransformer中,输入和[mem]token在相同的传统自检和更新处理流程中进行更新。在这种情况下,可能会“照常”更新输入序列元素的表示形式,而无需注意存储器的内容。在此,全局信息可以“对等”方式传播。为了阻止这种分布式信息流以及全局和本地表示的单独存储和处理,在传统的Transformer层中添加了memory bottleneck 步骤。所得的MemBottleneckTransformer具有两阶段的处理流程(见图1c)。
-
「Memory update:」 首先,计算每个内存token与内存 和输入 的完整序列之间的注意力(请参见图1c中的步骤1):
这里的 是AttentionSublayer和 。然后使用从序列中聚合的信息更新内存token表示形式,并使用剩余连接更新内存本身,并执行进一步的元素方式转换(请参见图1c中的步骤2):
-
「Sequence update:」 计算序列与记忆之间的注意力(图1c步骤3):
然后使用仅从内存中聚合的信息更新序列token表示形式,并执行进一步的元素方式转换(图1c中的步骤4):
换句话说,内存“参与”自身和一个序列,而序列仅“参与”内存。这将迫使模型通过内存累积和重新分配全局信息。如果存储器的大小恒定,则对于MemTransformer的计算将按序列 的大小线性缩放,而对于传统的转换器,其缩放为 。
结果与讨论
性能标准
总结
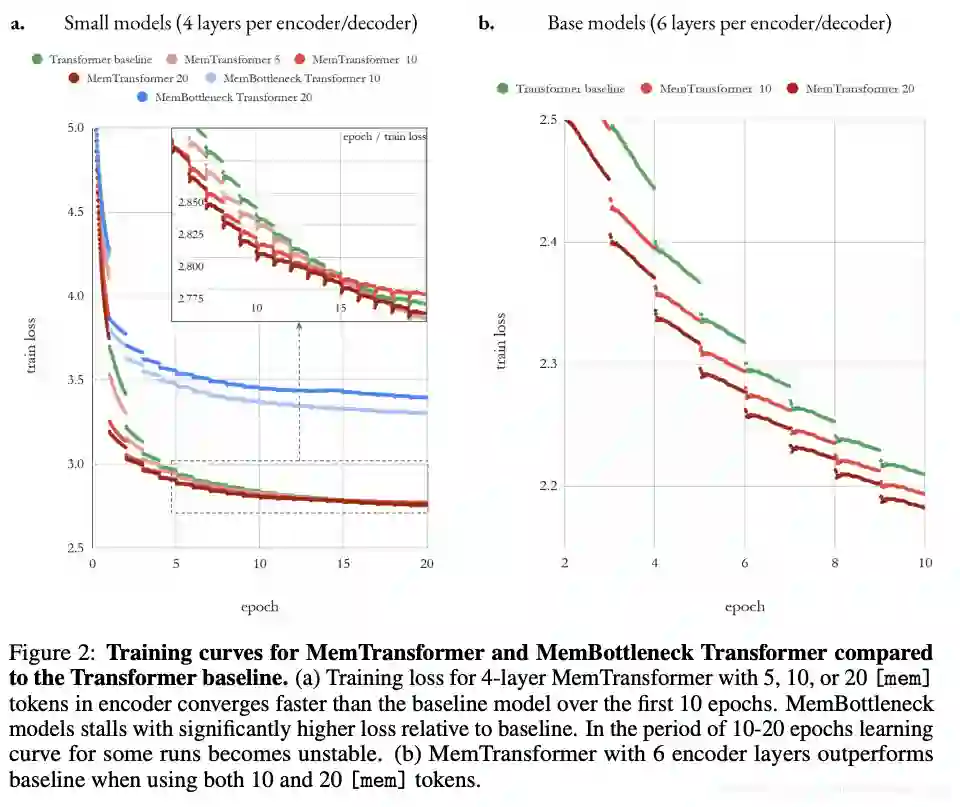
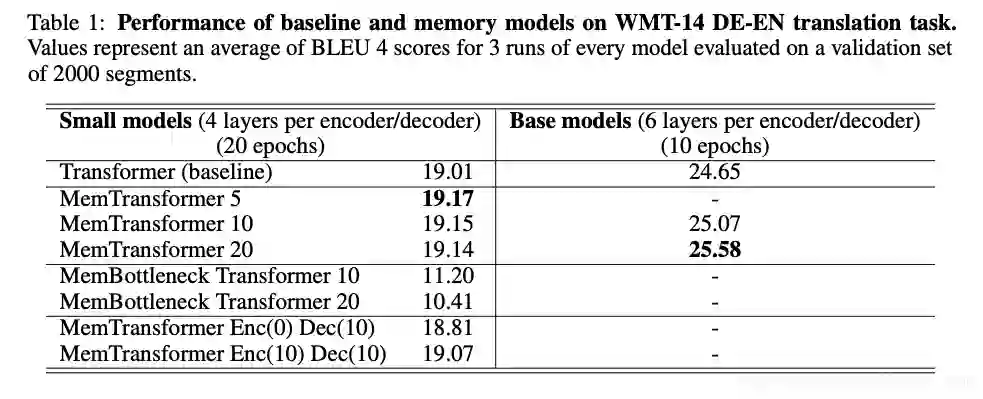
机器翻译质量的比较表明,在MemTransformer中添加通用内存可以提高性能(超过基准)。此外,训练速度和最终质量与内存大小成正比。另一方面,MemBottleneck Transformer的所有自我注意力仅限于记忆,训练后的得分明显较低。
记忆损伤测试表明,训练有素的MemTransformer模型的性能关键取决于记忆的存在。尽管如此,当在推理过程中更改内存大小时,模型学习到的内存控制器只会逐渐降低。这表明控制器具有一定的鲁棒性和泛化能力。
本文内存扩充方法是通用的,可以扩展几乎所有“注意力集中的编码器-解码器”框架。认为MemTransformer与处理长序列的递归机制的组合特别有希望。它也可以应用于依赖多跳推理或计划的任务。在这种情况下,内存应有助于存储和处理解决方案中间阶段的表示形式。
- END -

推荐阅读
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏



