BEVFormer:基于Transformer的自动驾驶BEV纯视觉感知

BEVFormer 很荣幸参与到最近这波 BEV 感知的研究浪潮中,我们从开源社区中受益良多,也希望尽我们所能为社区做出我们自己的贡献,希望未来与社区一道共同构建更加安全可靠的自动驾驶感知系统。

引言
TL; DR:本文提出了一套基于 Transformer 和时序模型在鸟瞰图视角下优化特征的环视物体检测方案,即 BEVFormer。nuScenes 数据集上以 NDS 指标(类似mAP),在 camera only 赛道中大幅领先之前方法。本文旨在介绍我们在设计 BEVFormer 过程中考虑的思路、比较的多种方法、以及下一步可能的研究方向。

论文标题:
BEVFormer: Learning Bird’s-Eye-View Representation from Multi-Camera Images via Spatiotemporal Transformers
https://arxiv.org/pdf/2203.17270.pdf
https://github.com/zhiqi-li/BEVFormer

介绍
最近,基于多视角摄像头的 3D 目标检测在鸟瞰图下的感知(Bird's-eye-view Perception, BEV Perception)吸引了越来越多的注意力。一方面,将不同视角在 BEV 下统一与表征是很自然的描述,方便后续规划控制模块任务;另一方面,BEV 下的物体没有图像视角下的尺度(scale)和遮挡(occlusion)问题。如何优雅的得到一组 BEV 下的特征描述,是提高检测性能的关键。
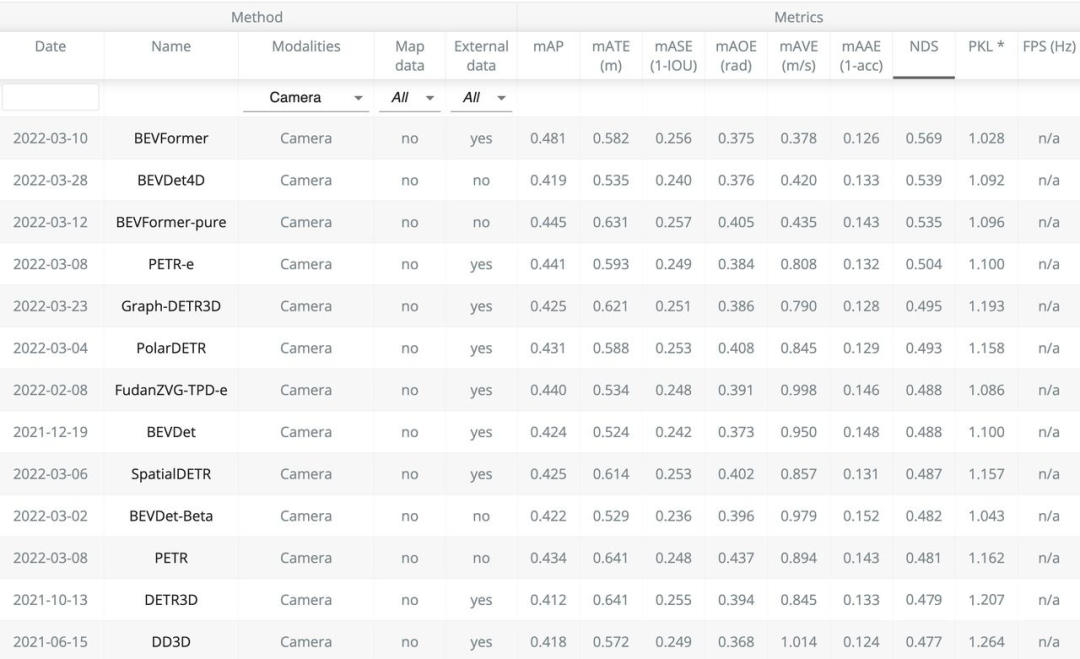
nuScenes自动驾驶数据集因其数据的质量、规模与难度都比之前数据集有大幅提升,而获得了很多研究者的关注。在 nuScenes 3D object detection task 上,目前前 6 名方案都是 2022 年 3 月进行的提交。我们提出的 BEVFormer 取得了 48.1 mAP 和 56.9 NDS,两个指标均超越现有方法 3 个点以上,暂列第一。“低碳版” BEVFormer-pure 仅使用 ResNet-101 与单尺度测试,取得了优于第二名(Swin-B、test-time aug)的 mAP 以及相同的 NDS。具体榜单和 Demo 视频如下。
▲ Demo: BEVFormer,一种全新的环视目标检测方案
本项目最早启发于 2021 年 7 月特斯拉的技术分享会,为此我们还做了几期细致的分享(链接 TODO)。特斯拉展示了基于 Transformer 使用纯视觉输入进行自动驾驶感知任务的惊艳效果,但是它并没有展示其方法的具体实现和量化指标。与此同时,学术界也有许多相关工作旨在利用纯视觉输入来完成自动驾驶感知任务,例如 3D 目标检测或者构建语义地图。我们提出的 BEVFormer 的主要贡献在于使用 Transformer 在 BEV 空间下进行时空信息融合。

BEVFormer方案
3.1 动机
在介绍 BEVFormer 的具体方案之前,先要回答两个问题。
1:为什么要用 BEV?
事实上对于基于纯视觉的 3D 检测方法,基于 BEV 去做检测并不是主流做法。在nuScenes 榜单上很多效果很好的方法(例如 DETR3D, PETR)并没有显式地引入 BEV 特征。从图像生成 BEV 实际上是一个 ill-posed 问题,如果先生成 BEV,再利用 BEV 进行检测容易产生复合错误。但是我们仍然坚持生成一个显式的 BEV 特征,原因是因为一个显式的 BEV 特征非常适合用来融合时序信息或者来自其他模态的特征,并且能够同时支撑更多的感知任务。
2:为什么要用时空融合?
时序信息对于自动驾驶感知任务十分重要,但是现阶段的基于视觉的 3D 目标检测方法并没有很好的利用上这一非常重要的信息。时序信息一方面可以作为空间信息的补充,来更好的检测当前时刻被遮挡的物体或者为定位物体的位置提供更多参考信息。除此之外时序信息对于判断物体的运动状态十分关键,先前基于纯视觉的方法在缺少时序信息的条件下几乎无法有效判断物体的运动速度。
3.2 BEVFormer Pipeline
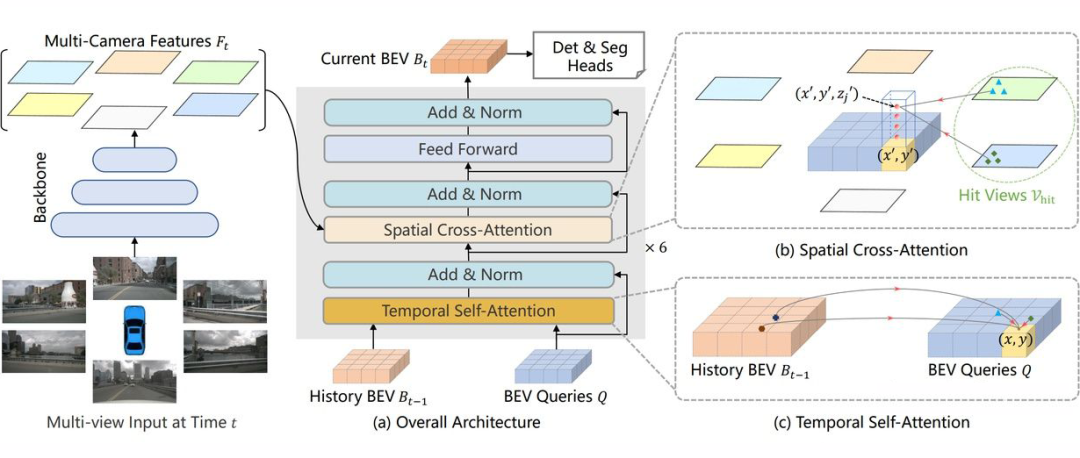
▲ BEVFormer整体框图
3.2.1 定义BEV queries
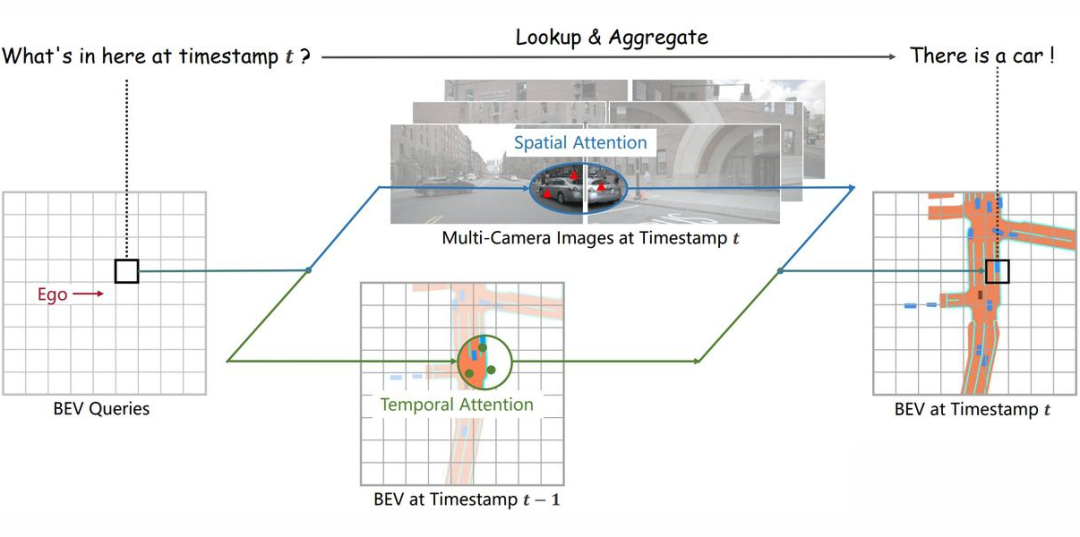
我们定义了一组维度为H*W*C的可学习参数作为 BEV queries, 用来捕获 BEV 特征。在nuScenes 数据集上,BEV queries 的空间分辨率为 200*200,对应自车周围 100m*100m 的范围。BEV queries 每个位于(x, y)位置的 query 都仅负责表征其对应的小范围区域。
BEV queries 通过对 spatial space 和 tempoal space 轮番查询从而能够将时空信息聚合在 BEV query 特征中。最终我们将 BEV queries 提取的到的特征视为 BEV 特征,该 BEV 特征能够支持包括 3D 目标检测和地图语义分割在内的多种自动驾驶感知任务。
3.2.2 Spatial Cross-Attention
如上图(b)所示,我们设计了一中空间交叉注意力机制,使 BEV queries 从多相机特征中通过注意力机制提取所需的空间特征。由于本方法使用多尺度的图像特征和高分辨率的 BEV 特征,直接使用最朴素的 global attention 会带来无法负担的计算代价。因此我们使用了一种基于 deformable attention 的稀疏注意力机制时每个 BEV query 之和部分图像区域进行交互。
具体而言,对于每一个位于(x, y)位置的 BEV 特征,我们可以计算其对应现实世界的坐标 x',y'。然后我们将 BEV query 进行 lift 操作,获取在 z 轴上的多个 3D points。有了 3D points,就能够通过相机内外参获取 3D points 在 view 平面上的投影点。受到相机参数的限制,每个 BEV query 一般只会在 1-2 个 view 上有有效的投影点。基于 Deformable Attention,我们以这些投影点作为参考点,在周围进行特征采样,BEV query 使用加权的采样特征进行更新,从而完成了 spatial 空间的特征聚合。
3.2.3 Temporal Self-Attention
从经典的 RNN 网络获得启发,我们将 BEV 特征视为类似能够传递序列信息的 memory。每一时刻生成的 BEV 特征都从上一时刻的 BEV 特征获取了所需的时序信息,这样保证能够动态获取所需的时序特征,而非像堆叠不同时刻 BEV 特征那样只能获取定长的时序信息。具体而言,给定上一时刻的 BEV 特征,我们首先根据 ego motion 来将上一时刻的 BEV 特征和当前时刻进行对齐,来确保同一位置的特征均对应于现实世界的同一位置。
对于当前时刻位于(x, y)出的 BEV query, 它表征的物体可能静态或者动态,但是我们知道它表征的物体在上一时刻会出现在(x, y)周围一定范围内,因此我们再次利用 deformable attention 来以(x, y)作为参考点进行特征采样。
我们并没有显式地设计遗忘门,而是通过 attention 机制中的 attention wights 来平衡历史时序特征和当前 BEV 特征的融合过程。每个 BEV query 既通过 spatial cross-attention 在 spatial space 下聚合空间特征,还能够通过 temporal self-attention 聚合时序特征,这个过程会重复多次确保时空特征能够相互促进,进行更精准的特征融合。
3.2.4 使用BEV特征支撑多种感知任务
一个显式的 BEV 特征能够被用于 3D 目标检测和地图语义分割任务上。常用的 2D 检测网络,都可以通过很小的修改迁移到 3D 检测上。我们也验证了使用相同的 BEV 特征同时支持 3D 目标检测和地图语义分割,实验表明多任务学习能够提升在 3D 检测上的效果。
3.3 实验效果
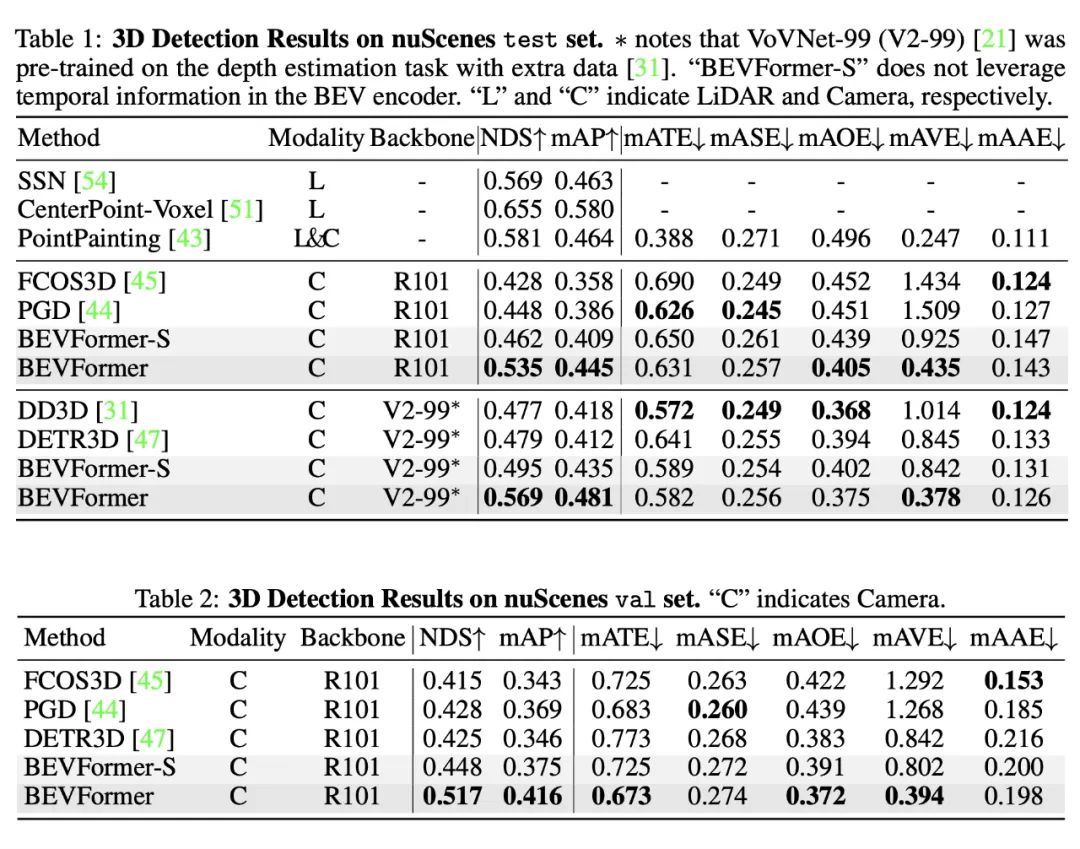
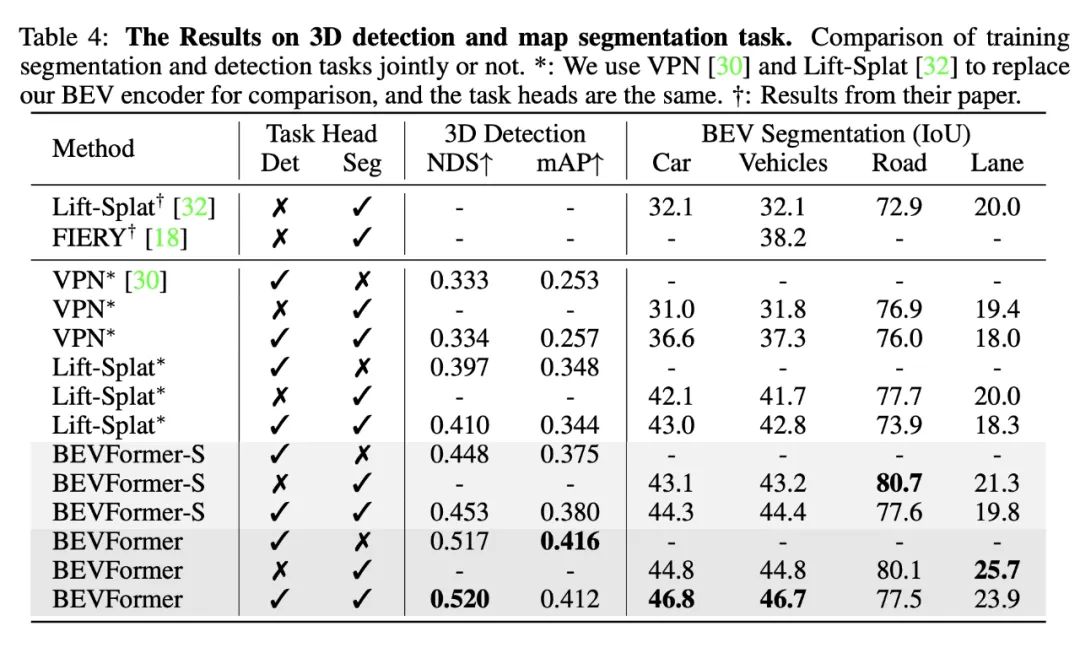
我们在 nuScenes 上的实验结果表明了 BEVFormer 的有效性。在其他条件完全一致下,使用时序特征的 BEVFormer 比不使用时序特征的 BEVFormer-S 在 NDS 指标上高 7 个点以上。尤其是引入时序信息之后,基于纯视觉的模型真正能够预测物体的移动速度,这对于自动驾驶任务来说意义重大。
我们还证明了模型同时做检测和分割任务能够提升在 3D 检测任务上的性能,基于同一个 BEV 特征进行多任务学习,意义不仅仅在于提升训练和推理是的效率,更在于基于同一个 BEV 特征,多种任务的感知结果一致性更强,不易出现分歧。
在下面这个场景下,BEVFormer 基于纯视觉输入得到的检测结果跟真实结果十分接近,再 BEV 视角下的分割结果和检测结果也有着非常好的一致性。


相关工作
自动驾驶场景中,基于 BEV 空间的感知系统能够给系统带来巨大的提升。在经典的自动驾驶感知系统中,camera 感知算法工作在 2D 空间,LiDAR/RaDAR 感知算法工作在 3D 空间。下游的融合算法通过 2D 与 3D 之间的几何关系对感知结果进行融合。由于融合算法仅对感知结果进行融合,会丢失大量的原始信息,同时手工设计的对应关系难以应对复杂的场景。
在基于 BEV 空间的感知系统中,Camera,LiDAR,RaDAR 的感知均在 BEV 空间中进行,有利于多模态感知融合。而且,融合过程较传统方法提前,能充分利用各个传感器的信息,提升感知性能。将 camera feature 从仿射视角 perspective 转换到鸟瞰图 BEV 视角,一般使用 IPM(inverse perspective mapping)和 MLP(multi-layer perception),近来也有工作使用 Transformer 结构。
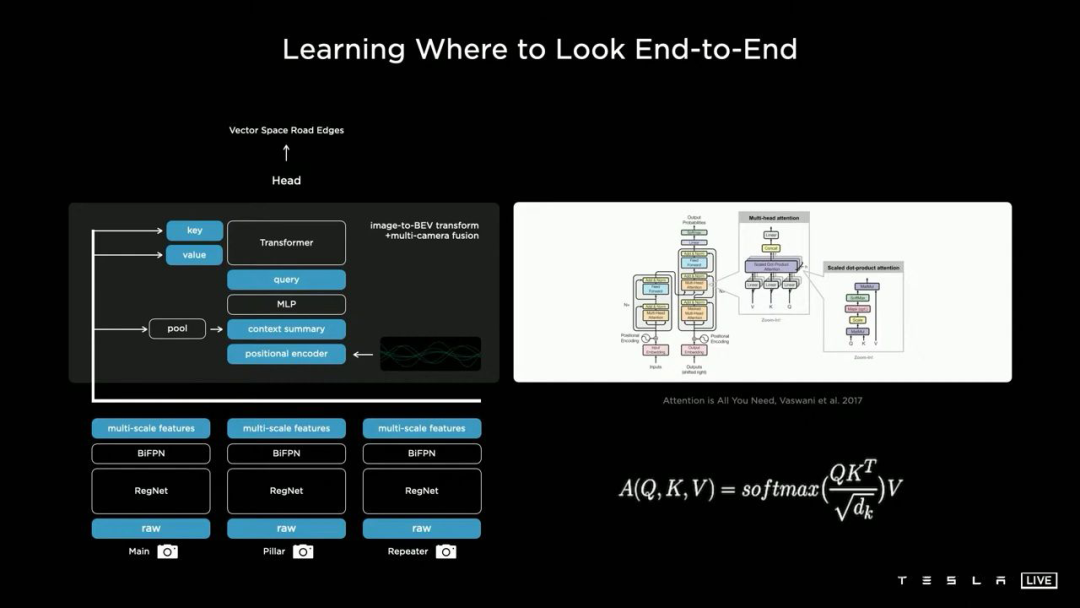
工业界方案:特斯拉
工业界方案:地平线/毫末智行
以 BEV 为中心的感知方案同样受到了国产厂商的关注。国产厂商中,地平线和毫末智行均公开展示过其感知方案使用 BEV 范式。
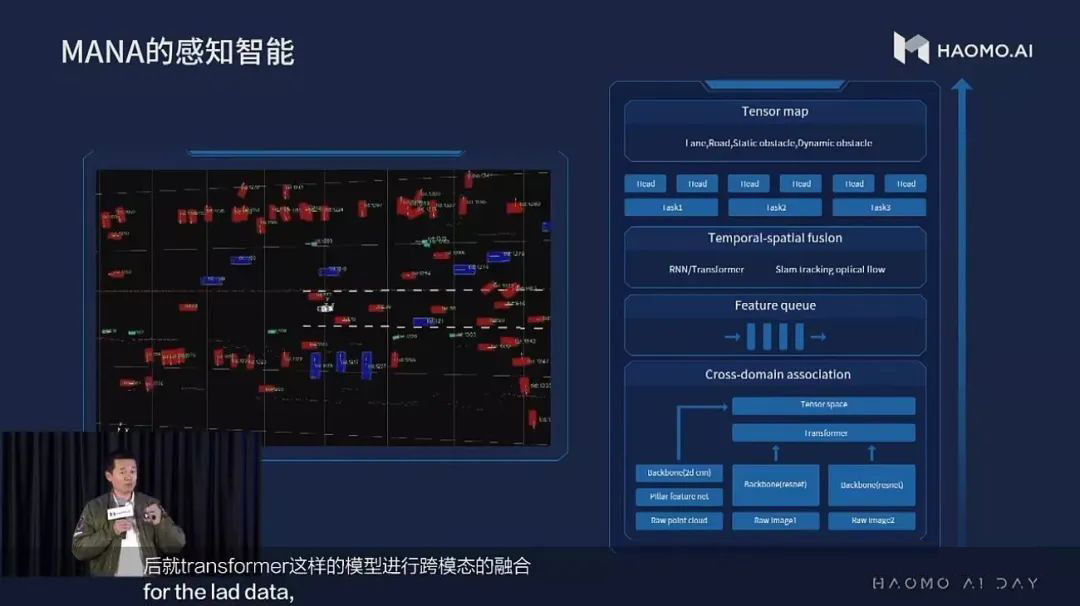
▲ 毫末感知架构图
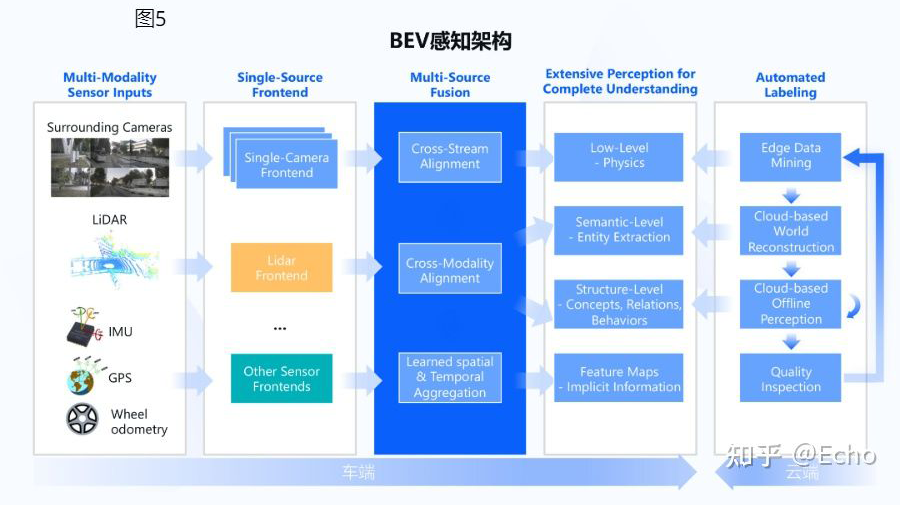
▲ 地平线架构图
学术界论文:Projecting Your View Attentively: Monocular Road Scene Layout Estimation via Cross-view Transformation(PYVA, CVPR 2021)
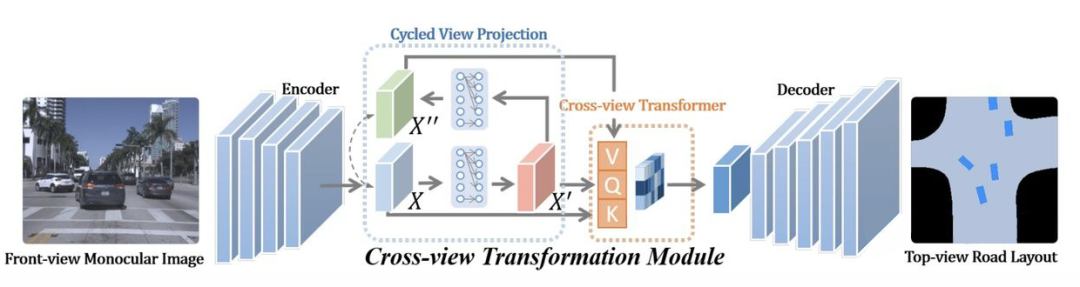
PYVA 使用 MLP 进行 perspective 到 BEV 的转换,在完成转换后,再使用一个 MLP 将 BEV feature X' 转换回 perspective view,并通过 X 与 X'' 进行约束。然后使用 tranformer 融合 BEV feature X' 和 perspective feature X'',再通过数据约束获得 BEV 表征。
PYVA 由两个 MLP 构成,一个将原始特征 X 从 perspective 转换到 BEV X',另一个将 BEV X' 转换回 perspective X",两个 MLP 通过 X 与 X'' 进行约束。然后使用 tranformer 融合 BEV feature X' 和 perspective feature X'',再通过数据约束获得 BEV 表征。
学术界论文:Translating Images into Maps https://arxiv.org/abs/2110.00966
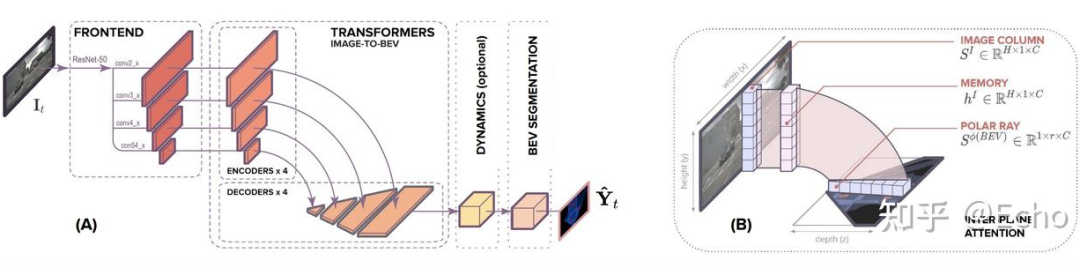
Translateing images into maps 发现,无论深度如何,在图像上同一列的像素在 BEV 下均沿着同一条射线,因此,可以将每一列转换到 BEV 构建 BEV feature map。作者将图像中每一列 encode 为 memory,利用 BEV 下射线的半径 query memory,从而获得 BEV feature,最后通过数据监督使模型拥有较好的视角转换能力。
学术界论文:DETR3D: 3D Object Detection from Multi-view Images via 3D-to-2D Queries(DETR3D, CoRL 2021)
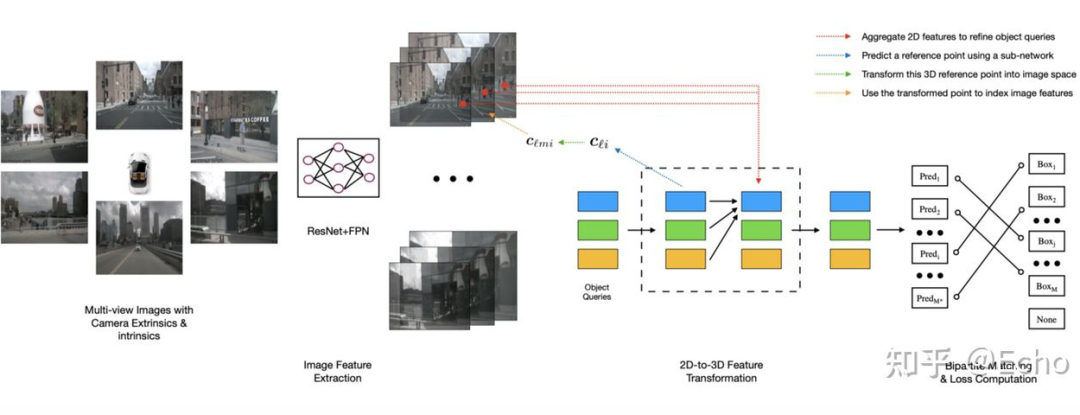
DETR3D 虽然没有直接使用 BEV feature,但 DETR3D 直接在 BEV 视角下进行物体检测。通过解码的物体三维位置及相机参数,利用 2D 图片对应位置的 feature 不断 refine 物体 3D 位置,从而达到了更好的 3D 物体检测性能。
学术界论文:PETR: Position Embedding Transformation for Multi-View 3D Object Detection
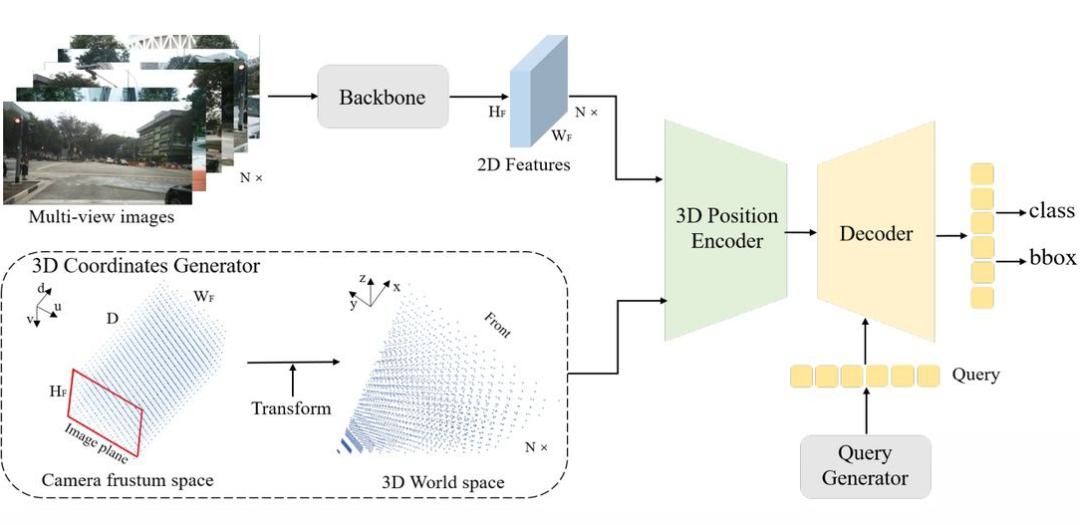
PETR 在 DETR3D 的基础上更进一步,为每个 2D 视角添加了 3D 位置特征,与之前的 Lift-Spalt-Shot 类似,PETR 使用深度分布来表征每个 2D 像素潜在的深度信息。将相机空间下的坐标系转换成世界坐标系之后,能为所有视角提供一个统一的 3D 位置特征。不同于 DETR3D,PETR 无需让 query 回归 3D 框的中心点然后投影到 2D 视角下聚合特征,PETR 直接使用类似 DETR 那样的全局 cross-attention 自适应的学习所需特征。

下一步工作
相信读到这里的小伙伴都是我们的铁粉,且坚定相信 BEV Perception 会是下一代自动驾驶感知算法框架的主流趋势。这里我们也给大家分享下基于 BEVFormer 的最新思考,希望和业界同仁一起探索这个方向。欢迎各种 challenge 与 comment。
一方面,把 BEVFormer 扩展成多模态、与激光雷达融合是一个很自然的想法。我们注意到最新的 DeepFusion 工作也已经揭开其神秘的面纱。这里面一个关键的点是如何正确 align Lidar query feature 和相机下的特征;在 deepFusion 实现中,InverseAug 是保证特征一致的重要操作。该方法在目前 Waymo 3D Detection 榜单中也独占鳌头。
另一方面,如何以纯视觉的设定,优化当前 pipeline,把性能提升至和 Lidar 差不多的结果也是一件非常有挑战的事情。这里面一个关键因素是如何以相机 2D 的信息输入,得到一个准确的 3D 空间位置估计,即基于图像的(稠密)深度估计。在这方面发力的影响力要远远大于单纯的 Sensor Fusion。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
