【干货】KNN简明教程
【导读】本文是Devin Soni撰写的博文,主要介绍k-近邻算法(KNN)的工作原理和常见应用。KNN可以说是机器学习算法中最普遍、最简单的分类方法了,其拥有思想简单、易于实现等优点,但是也存在若干缺点,如需要计算量大、耗费计算资源等。因此KNN适用于小样本分类任务。本文简明扼要地介绍了KNN的原理和若干要点,相信对于机器学习初学者能有帮助。
Introduction to k-Nearest-Neighbors
KNN 简介
k-最近邻(kNN)分类方法是机器学习中最简单的算法之一,并且是机器学习和分类入门的算法之一。 最基本的,它是通过在训练数据中找到最相似的数据点进行分类,并根据他们的分类做出有根据的猜测。 虽然KNN理解和实现起来非常简单,但是这种方法在很多领域都有广泛的应用,例如推荐系统,语义搜索和异常检测。
正如我们在其他机器学习问题中需要的那样,我们必须首先找到一种将数据点表示为特征向量的方法。特征向量是我们对数据的数学表示,并且由于我们的数据的期望特征可能不是固有数值,因此可能需要预处理和特征工程来构建这些向量。给定具有N个特征的数据,特征向量将是长度为N的向量,其中向量的入口I代表特征I的数据点值。因此,每个特征向量可以被认为是R ^ N中的点。
现在,与大多数其他分类方法不同,kNN属于惰性学习,这意味着在分类之前没有明确的训练阶段。相反,任何对数据进行概括或抽象的尝试都是在分类时进行的。虽然这确实意味着我们可以立即开始分类,但是这种类型的算法存在一些固有的问题。我们必须能够将整个训练集保存在内存中,除非我们利用某种方法对数据集进行一定的减少,并且执行分类可能在需要耗费巨大的计算量,因为算法需要通过每个分类的所有数据点进行解析。因此,kNN往往适用于特征不多的小型数据集。
一旦我们形成了我们的训练数据集,表示为M×N矩阵,其中M是数据点的数量,N是特征的数量,我们现在可以开始分类。对于每个分类,kNN方法的要点是:
计算要分类的样本与训练数据集中的每个样本之间的距离值
选取k个最近的数据点(k个最低距离的项目)
在这些数据点之间进行“多数投票” - 该样本范围中的主要类别被确定为最终分类。
在进行分类前必须确定两个超参数的值。一个是将要使用的k的值;这可以任意决定,也可以尝试交叉验证以找到最佳值。接下来也是最复杂的是将要使用的距离度量。
有很多不同的方法来计算距离,因为它是一个相当模糊的概念,并且最好的距离计算方式总是由数据集和分类任务决定。两种比较流行的是欧几里得距离和余弦相似性。
欧几里得距离最广为人知;它通过从待分类点减去训练数据点而得到向量。
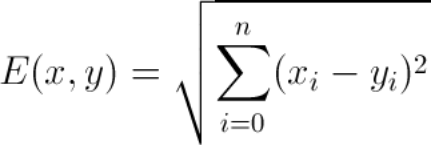
另一个常用指标是余弦相似度。 余弦相似性使用两个向量之间的方向差来计算量值。
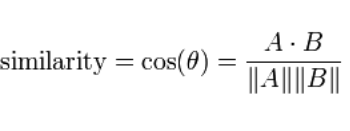
选择度量标准通常会非常棘手,最好使用交叉验证来决定,除非您有一些先前的知识能清楚地了解一种肯定比另一种好。例如,对于词向量,您可能会使用余弦相似度,因为词的方向比分量值的大小更有意义。一般来说,这两种方法的运行时间所差无几,并且都会受到高维数据的影响。
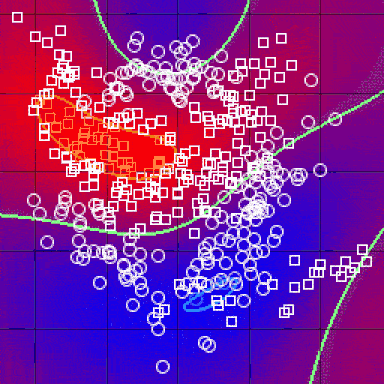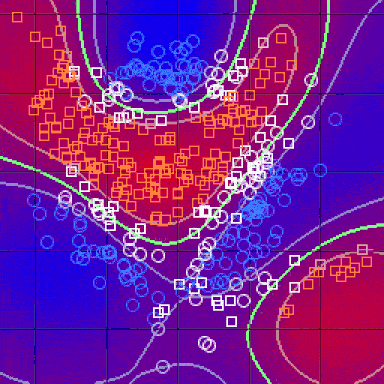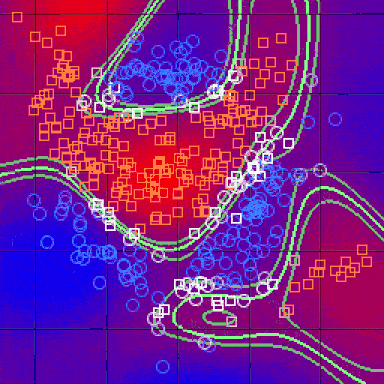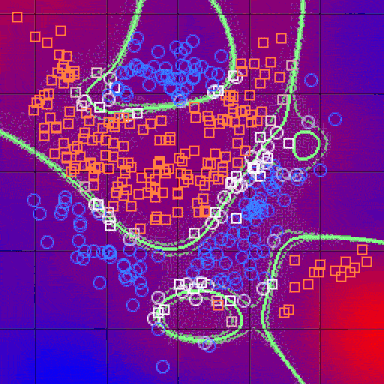
在完成上述所有步骤并确定度量之后,kNN算法的结果是将R ^ N划分为多个部分的决策边界。每个部分(在下面明显着色)表示分类问题中的一个类。边界不需要与实际的训练样例一起形成 - 而是使用距离度量和可用的训练点来计算边界。通过在(小)块中取R ^ N,我们可以计算出该区域内假设数据点的最可能类别,因此我们将该块标记为该类的区域。
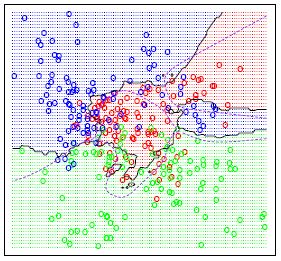
这个信息是实现算法必需的,这样做应该相对简单。当然,有很多方法可以改进这个基本算法。常见的修改包括加权、特定的预处理,以减少计算和减少噪声,例如各种算法的特征提取和减少尺寸。
此外,kNN方法也被用于回归任务,虽然不太常见,它的操作方式与分类器非常相似。
原文链接:
https://towardsdatascience.com/introduction-to-k-nearest-neighbors-3b534bb11d26
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~
点击“阅读原文”,使用专知



