AI中文语言理解得分首超人类,阿里达摩院创造新纪录,大模型又立功了
丰色 发自 凹非寺
量子位 | 公众号 QbitAI
最新中文语言理解领域权威榜单CLUE,诞生了一项新的纪录:
来自阿里达摩院的大模型,获得了超越人类成绩的86.685高分。
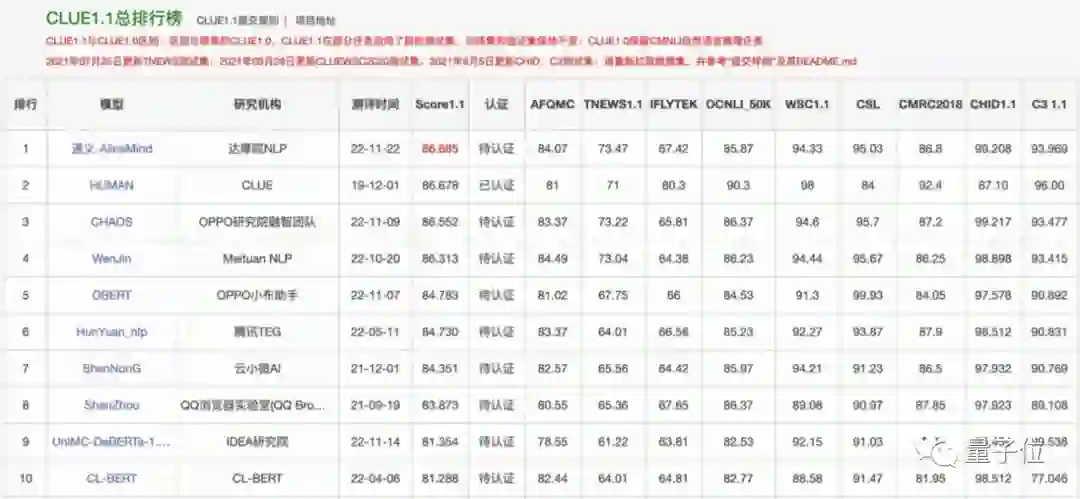
这是该榜单诞生近三年以来,首次有AI超过人类得分。
这也意味着AI理解中文的水平又达到了一个新的高度。
那么,创下这一纪录的AliceMind,是如何做到的?
4项任务超人类水平,同时实现总榜平均分首次超越
作为业界最权威的中文自然语言理解榜单之一,CLUE从文本分类、阅读理解、自然语言推理等9项任务中全面考核AI模型的语言理解能力。
过去三年,该榜单吸引了众多国内NLP团队的参与,尽管榜首位置多次易主,但参评AI模型一直未能超越人类成绩。
本次,这个来源于阿里通义大模型系列的AliceMind,一举在4项任务中超过了人类水平,并实现总分的首次超越。
据介绍,AliceMind一共靠下面两个关键技术获得这一成绩。
首先,基础模型迭代升级
AliceMind的基础模型在通用语言预训练模型StructBERT1.0(入选ICLR 2020)之上,进行了迭代升级。
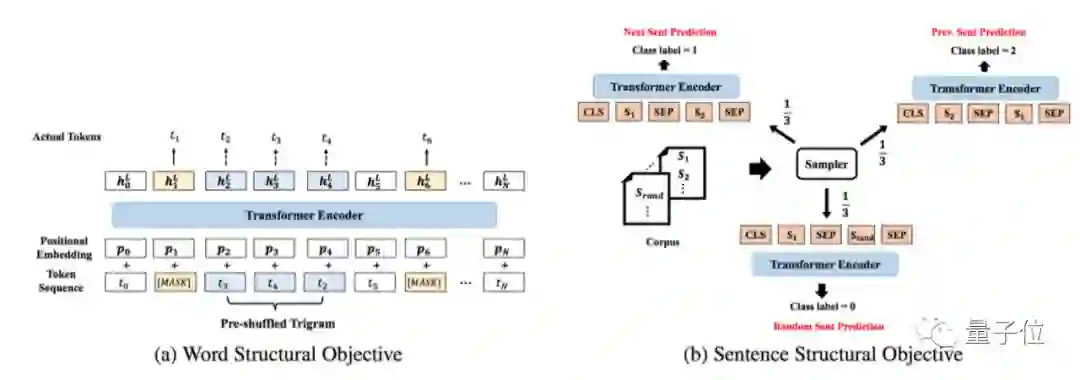
此前1.0的工作聚焦于通过在句子级别和词级别引入两个新的目标函数,相当于给机器内置一个“语法识别器”。
这使机器在面对语序错乱或不符合语法习惯的词句时,仍能准确理解并给出正确的表达和回应,大大提高机器对词语、句子以及语言整体的理解力。
本次,达摩院通过使用此前团队用于PLUG/中文GPT-3等超大规模模型训练所使用的海量高质量中文文本,以及近两年训练技术的经验,进行了以下改进:
替换激活函数,用GLU替换GeLU;
使用更大规模的字/词混合的词表,替换了原始的字级别词表;
使用相对位置向量替代绝对位置向量;
选取5亿规模的模型,在增加约60%模型参数和计算量的前提下,获得性能显著提升。
此外,阿里达摩院配合AliceMind在大规模预训练领域训练端和推理端的加速技术的积累,利用StrongHold(SuperComputing 2022)等技术实现了在16卡A100上用14天时间完成超过500B tokens的训练。
其次,Finetune
预训练模型是语义理解的重要基础,但是如何将其应用于下游任务同样也是一项重要的挑战。
达摩院NLP团队面对语义相似度、文本分类、阅读理解等下游任务,从迁移学习、数据增强、特征增强等方面进行了一系列的探索,来提升下游任务的性能表现。
以CLUE榜单中的WSC任务为例:
{
“target”: {
“span2_index”: 25, “span1_index”: 14,
“span1_text”: “小桥”, “span2_text”: “它”
},
“idx”: 14,
“label”: “true”,
“text”: “村里现在最高寿的人,也不知这小桥是什么年间建造的。它年年摇摇欲坠,但年年都存在着。”
}
输入样本构建方式:
村里现在最高寿的人,也不知这<名词>小桥</名词>是什么年间建造的。<代词>它</代词>年年摇摇欲坠,但年年都存在着。
在常规的分类方法中,一般使用[CLS]标签的最后一层隐藏状态作为输入分类器的特征,要求模型通过标记隐式地学习指代任务。
为了加强分类器的输入特征,阿里达摩院从编码器最后一层隐藏状态中提取出指代词和名词所对应的向量表示并进行mean pooling。
随后将名词和代词的向量表示进行拼接,并用分类器进行0-1分类。在加入增强输入特征后,在dev集上,模型表现从87.82提升至93.42(+5.6)。
通过分析structbert的预训练任务,我们也可以发现,这种特征构建的方式,更符合structbert预训练任务的形式,缩短了Pretrain阶段和Fine-tune阶段的gap,从而提高了模型表现。
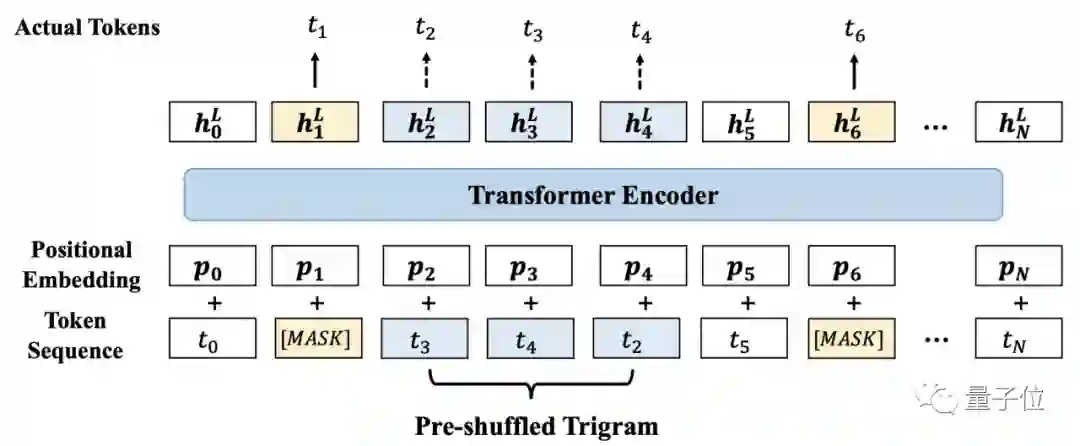
△structbert预训练任务
关于AliceMind
阿里达摩院历经三年研发出阿里通义AliceMind。
该模型体系涵盖预训练模型、多语言预训练模型、超大中文预训练模型等,具备阅读理解、机器翻译、对话问答、文档处理等能力。
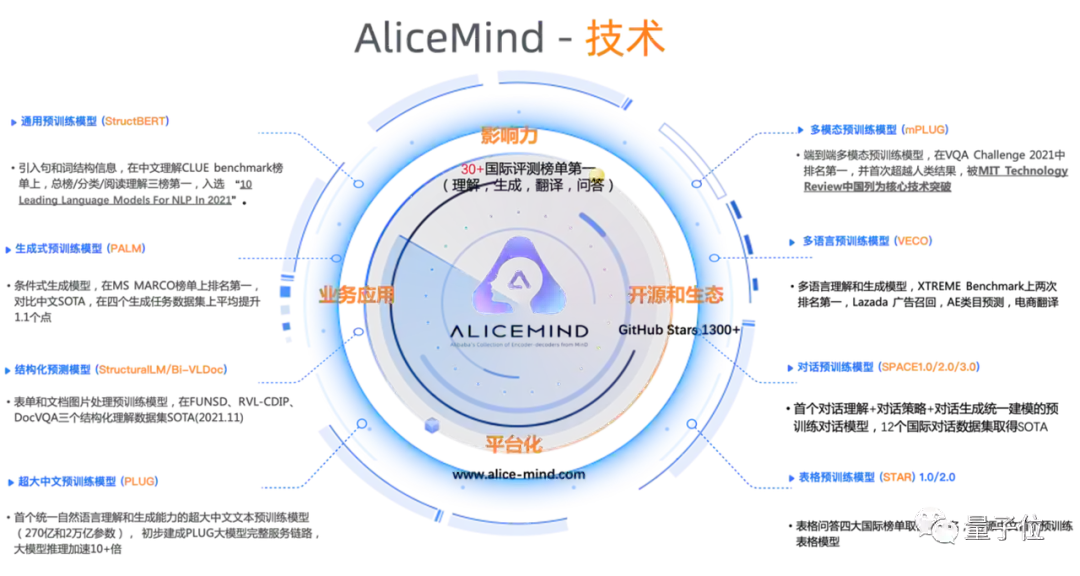
并先后登顶了GLUE、CLUE、XTREME、VQA Challenge、DocVQA、MS MARCO在内的自然语言处理领域的的六大权威榜单,斩获36项冠军。
AliceMind已于去年6月开源。
本次在CLUE benchmark上首超人类中所使用的backbone模型,已经在达摩院此前发布的ModelScope平台中开放。
开放地址:
https://modelscope.cn/models/damo/nlp_structbert2_fill-mask_chinese-large/summary
— 完 —
MEET 2023 大会定档!
首批嘉宾阵容公布
量子位「MEET2023智能未来大会」正式定档12月14日!
首批嘉宾包括郑纬民院士、MSRA刘铁岩、阿里贾扬清、百度段润尧、高通Ziad Asghar、小冰李笛、浪潮刘军以及中关村科金张杰等来自产学研界大咖嘉宾,更多重磅嘉宾陆续确认中。
点击“预约”按钮,一键直达大会直播现场!
点这里关注我 👇 记得标星噢 ~




