【趣科研】计算机视觉极简史


- 本期关键词 -
计算机视觉
▼
-01-
什么是计算机视觉?
▼ 是二娃的火眼金睛?▼

▼ 还是凹凸曼的动感光波?▼

拒绝脑补 | 一起补脑

今天的主题和二娃、凹凸曼都有着淡淡的联系。如果说二娃的眼睛是人类视觉的杰出代表,那凹凸曼的眼睛就代表了计算机视觉(Computer Vision, CV),又称机器视觉。如果把脑接收信息的通道比作流进太平洋的河流,那视觉就是长江黄河级别,听觉顶多算淮河,嗅觉基本就是门前大桥下那条沟了~
研究表明,人脑接收的信息约80%来自于视觉。原来视觉如此重要,突然明白为啥单身了,毕竟近视眼大半个残疾人啊。莫慌,一些CV前辈们已经为我们开创了计算机视觉,它的目的就是让计算机具备和人一样的"眼力",能够识别、理解周围的世界。但是,目前看来,就像二娃能看到并理解千里之外蛇精的企图,而凹凸曼可能把怪兽都认错了(每次使用还要敲几下脑袋), 现在的CV系统对周围世界的识别尤其是理解能力还远远比不上人类。
-02-
计算机视觉极简史
近几年初入CV界的同志,几乎都是被深度学习的春风给刮进来的。这导致很多CV未成年司机几乎把CV和深度学习划上了等号。这种认识从科学的角度来说很有必要纠正。其实,深度学习只是机器学习的一个分支,是一类方法,而CV则是一个研究领域。CV好比物理学,而机器学习就像数学,深度学习可以比作数学里面的一个分支。所以说,CV是一个独立的江湖。
▼ 50年代 ▼
混沌初开
时间回到20世纪50s,当我国红红火火进行社会主义改造时,CV界混沌初开。这时谈CV,不得不先提它的表哥---模式识别(Pattern Recognition, PR)。直到现在CV和PR都有着千丝万缕的关系,CV界一个国际顶级会议---CVPR(与ICCV、ECCV合称CV界三大顶会)就是以它俩的名字命名的。所以,CV刚生下来时,是放在他表哥家寄养的。那时的CV主要研究的是二维图像分析,如光符识别等。
▼ 60年代 ▼
自立门户
1963年,MIT的Larry Roberts博士毕业,他的博士论文《Machine Perception of Three-Dimensional Solids》 ,虽然没有获诺贝尔奖,但打响了CV作为一门新兴研究方向的第一枪,从此CV正式从表哥PR家分出来,成为一个独立的研究领域。Roberts时代的CV研究主要是从图像中提取立方体等多面体的三维结构,并对物体形状及其空间关系进行描述。
▼ 70年代 ▼
江湖一统
当CV进入及冠之年,发生了一个标志性的事件。MIT AI实验室的Minsky---人工智能的先驱,在全世界广发英雄帖,邀请到了当时世界上很多有名的青年学者,其中一位叫做David Marr---他就是我们CV界公认的第一位武林盟主,CV的70年代,是属于Marr的。
有武林盟主,必有武功绝学。Marr提出的视觉计算理论---Marr视觉计算理论,标志着计算机视觉理论框架初步建成,犹如牛顿力学之于物理学。Marr理论将视觉过程分为三个层次:首先是基元图层次,它抽取原始图像的角点、边缘、纹理等基本特征;其次是2.5维图层次,即通过输入图像和基元图恢复场景的深度、轮廓等信息;最后是三维重建层次,由输入图像、基元图、2.5维图来重建和识别三维物体。
▼ 80年代 ~20世纪初▼
踏上康庄大道
进入80s,当我国乘着改革开放的东风踏上社会主义的康庄大道时,CV也乘着Marr理论的东风进入了大繁荣时代。新的理论不断涌现,著名的如主动视觉理论框架,分层重建理论框架。新的算法层出不穷,特征提取方面如SIFT算法、HOG算法,物体识别方面如LDA算法、SPM算法。这个时期的理论和算法基本上是基于Marr理论,但又超出了Marr理论。是江湖代有才人出,青出于蓝而胜于蓝。
▼ 20世纪前10年▼
深度学习神助攻
自从Marr理论一统江湖后,CV算法出现了大繁荣。总的来说,那个时期的CV算法研究都是通过CV界各路英雄豪杰手工设计特征。2012年,深度学习在CV界的华山论剑(ILSVRC)上几乎打败了之前所有的算法。尤其是在目标识别与检测领域,深度学习更是令传统CV界各位老前辈怀疑人生。正如现在的趋势,深度学习在近年来大有一统天下的趋势。深度学习方法与传统视觉方法不同的是,传统方法是先手工设计特征,然后用分类器分类。深度学习方法是将特征学习和分类器集成到一个网络里,深度网络在大数据中自己学习特征并分类。
-03-
计算机视觉的任务
▼ 图像分类 ▼
当人看到一只猫,不知不觉就会对它分类---猫类,图像分类就是完成这个任务。它将一副图像分类到一个属于已知的类别集合中的类别。为什么要已知类别集合呢?因为计算机本身不认识物体,是人介绍给它认识的,所以它只能在有限个类别内进行分类。为了训练计算机认识不同物体,CV前辈们收集了一些图像数据集。
入门的数据集有CIFAR-10(包含10类物体),进阶的数据集有ImageNet(包含上万类物体)。下图是CIFAR-10中的一些图片,图像分类的任务就是把一张未知图片分类为这10类中的一类。图像分类是最基本的视觉任务,流行的基本方法就是用深度卷积网络(CNN)提取特征并分类,将图片输入网络直接得到物体的类别。CNN的发展经历了以下路线:AlexNet->ZF-net-> GoogleNet->VGG->ResNet。
相关推荐:
【深度】生物视觉中的图像物体识别通道|胡占义研究员

▼ 目标检测▼
目标检测是图像分类的一种推广,图像分类任务中, 图像内只有一个物体。当一副图像内的不同位置存在不同物体时那就不能简单地将图片分为某一类了。这时我们需要找出图像中有几类物体,准确地标注出它们所在的位置,并把物体在图像中框出来,效果如下图所示。目标检测也有其相应的数据集如PASCAL、COCO。
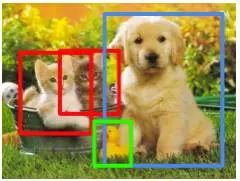
目标检测算法的发展路线是DPM->RCNN->Fast-RCNN->Faster-RCNN->YOLO->SSD。提到目标检测,还不得不提到一个人---Ross Girshick(江湖人称rbg),他为整个目标检测领域,尤其是基于深度学习的目标检测做出了重大的贡献。
相关推荐:
【AI唠科】Focal Loss:助大神何凯明获得ICCV最佳学生论文,究竟有什么功?|兼谈目标检测发展历程
▼ 语义分割▼
刚才我们用目标检测的方法把物体在图像中框出来了,这里的框一般是用矩形框。但物体一般是流线形的,所以为了进一步标注出物体,我们需要指出图像中哪些像素是对应哪一类的物体,这就是图像语义分割,效果如下图所示。语义分割可以看做一个分类问题,可以借鉴分类的算法把每一个像素划分到某一类物体。
相关推荐:
【新知】自动化所马佳彬、王威、王亮等研究人员提出不规则卷积神经网络:可动态提升内核效率

▼ 视觉问答 ▼
有人说,计算机能对图像进行识别,那它看懂了图像吗?有没有看懂图像,这是一个很学术的问题,现在也有很多相关的研究,其中就包括视觉问答。视觉问答(Visual Question Answering, VQA)已经不是一个纯粹的计算机视觉问题了。
它需要和自然语言处理(NLP)进行结合。视觉问答的任务就是输入一张图片然后输出一条自然语言来描述这个图片的特点,效果如下图所示。它的基本方法是CNN+RNN,这是因为CNN在CV任务中很豪,而RNN在NLP中很豪,豪门联姻,怎能不豪?
相关推荐:
【团队新作】让机器"好好说话": 自然语言处理新进展

▼三维重建▼
Marr的理论表明,CV的最高境界就是三维重建。前面研究内容是对二维图像的分析,而三维重建涉及到立体视觉。我们常说的三维重建一般是指基于二维图像的三维重建,是指通过图像预处理、点云配准与融合、生成表面等过程把真实的三维场景从二维图像中恢复出来,效果如下图所示。三维重建技术在机器人视觉导航、无人驾驶、文物保护等领域有非常大的作用。
相关推荐:
【实录】2017 GAITC 吴毅红研究员:三维视觉研究及应用

以上只是CV研究的几个主要问题,CV的研究热点远不止于此,如目标跟踪等...
欢迎留言、投稿补充!

Activation Function – 激活函数: 在人工神经网络中,节点的激活函数在给定输入的情况下定义该节点的输出。放在硬件上,计算机芯片电路可以被视为激活函数的数字化实现,其可以是“开”(1)或“关”(0)的状态,具体要取决于输入。在人工神经网络中,该功能也称为传递函数。

更多精彩内容,欢迎关注
中科院自动化所官方网站:
http://www.ia.ac.cn
欢迎后台留言、推荐您感兴趣的话题、内容或资讯,小编恭候您的意见和建议!如需转载或投稿,请后台私信。
作者:任盈盈
排版:Cassia
编辑:鲁宁、欧梨成


中科院自动化研究所
微信:casia1956
欢迎搭乘自动化所AI旗舰号!





