【进化算法】【机器学习】当机器学习遇上进化算法
进化,是生物智能演化的原动力。 学习, 是人类文明产生的原动力,也是当下红红火火的AI进步的原动力。 如果这两种神秘的力量结合, 我们会得到一个怎样的物种呢?虽然说这方面的尝试还不多, 不过我们已经可以在一些过去人的研究中见出端倪。
首先,我们说两种算法的本质都是在做优化。 在充满随机性的世界里, 大部分的自然过程趋势是熵增,耗散,或者说随机性的增加。而唯有生物的进化和学习,却可以抵抗这种趋势,在随机中产生有序,产生结构。
虽然都在做优化, 它们的优势和缺点也非常明显。 让我们来概述一下两种方法的核心。
进化算法vs机器学习
进化算法:
进化算法建立在基因之上,基因 - 可以理解为生命在各种条件下的一组行为策略。比如吃什么, 向什么方向移动,肤色的选择等。 这组策略被一套叫DNA的大分子固定, 也就是我们常常说的遗传编码 , 它通过一个复杂的化学反应, 制造RNA和特定的蛋白质,而一切生命现象都是由特定蛋白质实现的, 我们简单的说就是生命策略, 比如在外界环境出现如何变化时候如何反应。 你可以把DNA的编码看成一系列的if else语句, 就是在某种条件下, 触发某个蛋白质, 实现某一个功能。
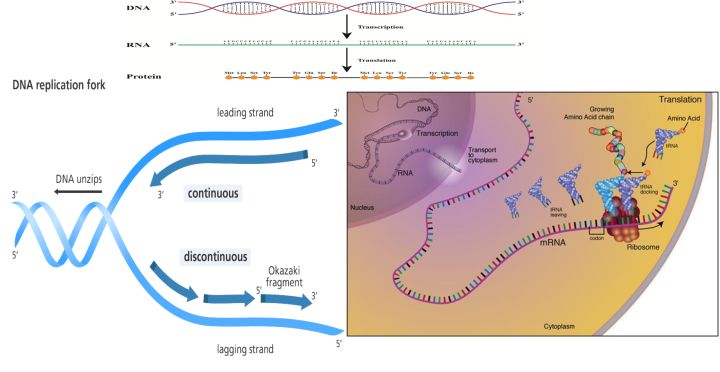
那么进化算法包含以下要素:
1,生物通过基因编码生存策略。 基因即一组可以编码蛋白质的生物大分子。
2, 单组策略的存在时间有限, 它会以繁殖的形式得到一个和自己一样的策略, 但是这个过程不是完全精确的, 它会以一定的方式出错或者说变化, 这恰恰使得下一代的策略可以轻微的偏离上一代。 从而在一段时间里, 形成越来越多的策略,我们叫做基因池。
3, 有的时候不同的基因会发生交叉, 也就是说把两组策略把各自的一部分给对方, 然后形成新的策略组合。 这种重组产生新的基因的速度会比变异快的多, 也就是我们说的交配。
3, 环境会评估某个策略(DNA) 是不是适合自己, 这个通常由一个叫适应度函数的东西表达。 适应度越高, 基因就是越适应当下环境。这个适应度很像机器学习里的目标函数。
3, 经过一段时间, 适应环境的策略会比不适应的环境的策略得到更多的个体,因为它自身存活的概率更高, 这样, 最终环境里数量最多的, 是最适应环境的策略。这样的策略不一定有一个。
4, 环境会变化。当环境变化, 最适宜的策略发生变化, 这个时候最适合的策略也发生变化, 导致新的物种和生态系统的生成。
机器学习:
理解机器学习最简单的角度是从一个计算机程序来看: 学习算法是一段特殊的程序。
如果说一段程序可以看做一连串从输入到输出的过程,无论是工程师还是程序员,我们都想通过设计来完成某种功能, 比如说你做一个网页, 你要画视觉图, UI图, 前端后端交互图,我们都是在给计算机设计一套解决具体问题的流程, 如做一个淘宝网。
而机器学习呢? 机器学习是你不去设计, 而让计算机自己去磨,如同用一套很一般的模子里打磨出能够解决特定问题的武器。 这点上,机器学习做的正是” 自发能够产生解决问题的程序的程序” , 一些机器学习的经典算法如线性回归, SVM, 神经网络, 它们单个都不能解决问题, 但是通过“学习”却可以一会去预测房价, 一会去寻找美女。
生物世界的学习与机器学习最接近的是强化学习。 强化学习的目标函数是未来的奖励总和, 智能体需要学习到合理的行为来实现奖励最大化。 最简单的强化学习即条件反射。 与进化算法非常类似的, 强化学习在优化行为策略, 但是与之不同的是, 强化学习的优化方法是下面要讲的梯度方法, 一种更为贪婪, 高效的优化方法。
整个机器学习依靠的寻求最优的方法就是梯度优化, 这个方法相比进化算法, 更具方向性和目的性, 虽然我依然不知道我要寻找的那个最优是什么, 但是我每往前走一步, 都希望最大程度的接近它, 或者说贪婪的接近它, 这个时候我们就会设置一个目标函数(类似于进化算法里的适应度), 然后我们让参数顺着最快速减少目标函数的方向去自动调整, 如下图。
深度学习作为机器学习的发展, 其成功几乎完全依靠了以反向传播为基础的梯度下降方法, 而事实上也是, 梯度下降在很多时候更加精准。但是, 如果你认为因为梯度下降完全优于进化算法的优化方法, 就错了。
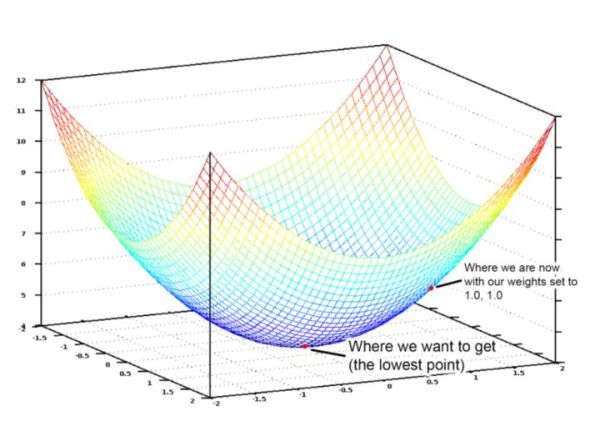
首先, 关于优化问题, 我最喜欢用的例子是一个小姑娘在山上采集蘑菇, 地势越低的地方蘑菇越多。 因而, 她需要找到一个最快的到达山谷的路径,小姑娘视力不好,因此她最好的做法就是用脚感受当下地势下降最快的方向往前走一步, 这就是梯度下降法。 在一个山谷形状比较简单的地方, 犹如上图, 你是很容易达到这个目标的。
然而真实世界的地形却并非如此简单, 比如下图,你看到无数的波峰和波谷。 每个波谷都代表一个局部最小值。 而事实上哪一个谷是最低谷, 这件事并没有那么容易。 如果你采用机器学习所使用的梯度下降, 则你极大可能会陷入到某个小的山谷里长期停滞。 当然, 在深度学习的问题里, 局部最优往往足够好了。 可是在最真实的情况下, 这下波峰和波谷的高低也可能是动态调整的, 今天的谷底可能是明天的波峰。
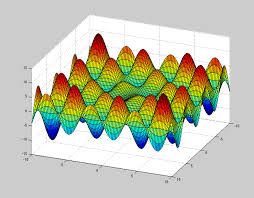
而进化算法呢? 进化算法就不一样了, 进化算法相当于一次释放出无数个小姑娘(基因池), 这些小姑娘, 各自在这个崎岖的地形里试错寻找蘑菇丰盛的最低点。 每个人的搜索策略(每个人的基因)有不同。 虽然趋近每个小山谷的速度不如梯度下降。 但是最终找到那个最优解的可能反而还更快。 这里面最核心的是, 用一个群体替代个体, 在优化的同时更多的保持多样性。 就如同自然界的物种, 有些物种比如说熊猫,居然进化成那么可爱但是站动力不强的样子, 但是自然还是没有淘汰它。 因为这种当下看着不太有利的基因, 不一定在自然巨变中就一定是没有用的。
进化算法结合机器学习之最小案例
废话少说,我们来看看把学习算法和进化算法合在一起, 会发生什么?
我们从一篇1994年的文章开始看起(Learning and evolution in neural networks by Nolfi, Elman, & Parisi) 这篇文章的作者试图阐述一件事,就是如果进化和学习是相辅相成的,不仅进化可以促进学习能力的增加,反过来, 学习也会促进进化的过程 , 造成类似于拉马克进化的效果。
来看如下的儿童游戏: 在一个grid走方格任务里,模拟生物需要在最短的时间里收集足够多的食物(用F代表), 这个生物由一个菜鸟级的神经网络代表。 神经网络接受的输入数据来自周围的食物的方向和距离远近(一种视觉,足以让你找到临近的食物)。 它的行为呢? 直线前进, 向左或向右转动。 神经网络的输出决定它的行为。
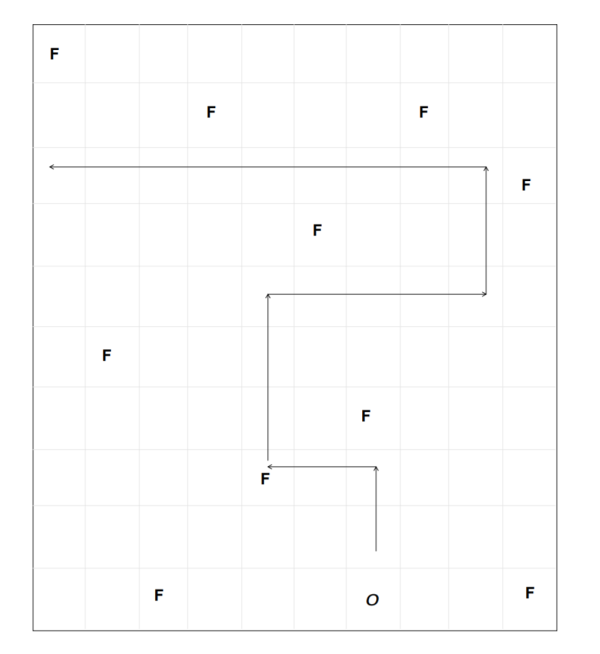
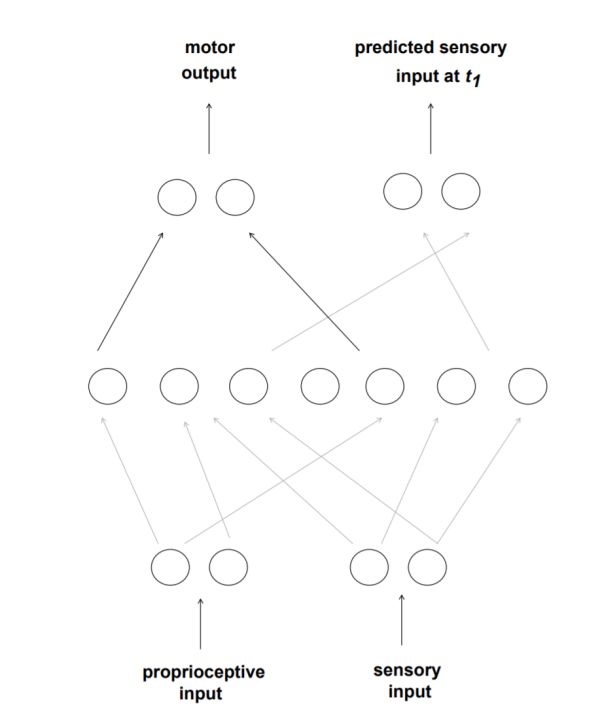
进化算法在这里具体管什么呢? 由于网络只有7个隐层神经元, 和两个动作输出神经元, 它的策略就是由它们的权重表达的。 而一组权重, 就可以看作一组DNA。 我们一开始准备很多这样的权重, 代表不同的策略(基因池)然后放到略有不同的环境里让这些虚拟生物跑, 跑到一定时间,就开始看它们采集到的食物的数量(fitness适应度), 那些食物采集比较少的生物, 而保留优胜者,经过这样一个经典的进化算法流程, 生物就可以学到上图所示的那种策略。
然而, 文章的发出者偏偏不是等闲之辈, 这个网络在干这件事之余还干的一件事是, 进行预测! 不停的预测下一刻它会看到的东西 ,或者说理解它的动作将给它带来什么样的环境变化。你看, 这不就是当下大名鼎鼎的好奇心或预训练的前身吗, 看来还真的是我们总在重复前辈的思想。
预测这个事情会产生什么效果呢? 通过预测的对错(不停的把自己想到的和最终结果对比),它会开始进行学习,一个重点在于, 学习的过程只在代系之内, 也就是说比如100轮(一轮就是一次游戏)做一次进化算法的迭代, 那么学习可能是在这100轮里每轮都进行的, 但是学习的结果不会传递给下一代, 就好像你死了, 你头脑里的知识也消失了。 那么随之而来的是什么现象呢? 学习不是就没有意义了吗?
不是。 在实验中我们发现, 这个预测性学习, 不仅仅是学会了预测, 而且, 它让虚拟生物在进化算法中得到的食物采集能力, 也就是说任务采集能力大大增加,也就是说,进化算法被监督学习助力了!
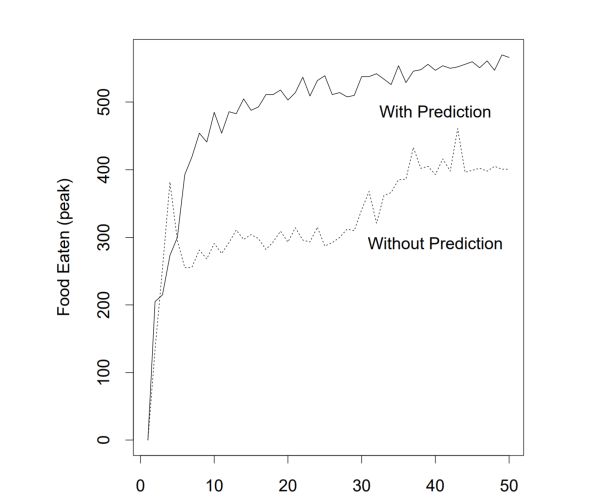
这件事表明看上去匪夷所思, 它就好像是我们过去所说的拉马克进化的复兴。拉马克进化是说, 亲代在后来习得的能力是可以通过遗传传递给子代的, 用一句话就是“用进废退” 。如果你看上面的曲线, 仿佛是说监督学习的个体, 由于亲代可以把它监督学习的成果传递给下一代, 引起了具备监督学习的批次进化速度更快。 事实上呢? 这是不可能的, 因为每一次学习到的权重并不会传递给子代, 虽然说传递是会发生的, 但是学习得到的权重改变却没有被传递。
那么学习是如何作用于进化的呢?用一句话概括这个过程的本质是: 学习使得进化的选择效应发生了变化。 那些通过监督学习能够最大程度的改变命运的个体,每一次被选择出来, 而非像在没有学习的版本里只是天生丽质被选择了。 一句话, 学习, 使得进化的选择更准确。
如果你这样理解这件事情, 还是会觉得有点民科, 我们可以给出一个比较数学的版本。 你依然想象一个高低不平的山区地图, 然后我们希望在上面寻找最小值。 每一个不同的策略, 代表地图上的一个点。 那么学习的效果是什么呢?学习可以在局部改变你的策略, 这就好比, 我们的策略可以从当下的一个点, 丰富到周围的很多点, 甚至是一个小的局域。 由于我们的地图是极度凹凸不平的, 可能在很小的局域里就包含了很多的地势变化。 一个没有学习的群体, 它的效果是在这个凹凸不平的地图上撒上很多点, 而有学习的呢?就是撒上很多小圆圈, 如果小圆圈所覆盖的地方包含了极小值, 我们就可以迅速的锁定它。 也就是说, 虽然学习本身的成果无法遗传, 通过学习, 我们才能更好判断哪些是值得保留的真正优势策略。 用优化的语言说就是学习通过局部优化增加了进化这个全局搜索器的效率。
好了 , 这个游戏看起来有点简单, 但那时你一定不要小瞧简单的游戏, 做AI, 你就应该从toy model 里理解问题, 然后看你的想法是否salable, 可扩展。 恰恰是, 这篇文章的成果可以映射当下的一系列AI成果, 直到征服星际争霸的alpha-star。
如果你追溯这条线的发展, 你首先会看到。机器学习和进化算法, 在这篇文章后, 都得到了飞速发展, 但是机器学习要快很多。
然后你会看到, 进化算法开始桥悄悄进入很多机器学习框架。而且, 正在实现之前机器学习所完全不可能实现的任务。
进化算法结合机器学习带来的无限可能
首先, 进化算法的本质是一种集群算法, 通过集群, 遍历式的搜索策略空间。 这点, 就比梯度下降更好克服非线性问题里局部极小的问题。 而且在用梯度方法不好并行的一些问题里, 如RNN的训练, 这种方法却可以产生出并行的威力。 再有,进化算法可以帮助我们做梯度下降所难以实现的改变,梯度下降需要问题可以微分, 而进化算法就自由的多, 只要你能够定义适应度和策略就可以做。 它特别擅长做超参数的调整, 改进网络架构, 甚至可以改变学习算法本身。 一句话就是说, 进化算法迈大步, 梯度下降局部调。 这样的思路结合,可以解决相当困难的问题。最后, 进化算法更有遐想力的地方, 还在于它所带来的智能体间合作与博弈的可能。
我们先来看合作, 后面的文章来自那个AI界的不为人赏识的教父级人物Schmidhuber: Accelerated Neural Evolution through Cooperatively Co-evolved Synapses 这篇08年左右的文章,将这种思路几乎用到了极致。这篇文章用进化算法直接解决了一个传统强化学习的经典任务pole balancing的较困难版本, 并且证明它在这类问题上比强化学习更有可扩展性。 联想到强化学习运用到现实生活中, 却经常碰壁, 原因就是鲁棒性差, 可扩展性不高,进化算法会是对它的一个极好补充。
那么何为合作? 这篇文章里, Schmidhuber直接用进化算法来优化一个模块化的网络。 网络中的每个模块可以看作群体中的一个个体, 而它们的组合网络就可以解决更复杂的任务, 合作体现在网络模块之间的配合。 这点让人不仅想到那个群体和个体的界限问题。 人由不同的器官组成, 人脑由不同脑区组成, 社会由人组成, 这些都可以看作一种广义的合作。 如果每个个体都很优秀, 组成的国家很弱小, 它还是会灭亡,基因传不下去。因此, 进化就会鼓励合作。同样的道理, 在这个模块化的网络里, 进化算法会促进模块间更好的配合最终完成复杂的控制任务。

进化算法和机器学习混合的最新应用案例 - AlphaStar: AlphaStar, 在星际争霸这样级别的游戏击败人类, 应该说这是一个了不起的胜利, 因为星际争霸这个游戏比围棋要接近真实世界很多, 信息是局部的,远方的世界笼罩在黑雾里, 当下和未来是连续的, 战略需要跨越很多时间尺度。这些问题,需要比阿法狗更加复杂的接近方法。 AlphaStar以一个具有记忆的神经网络LSTM为基础, 然后用到的学习方法, 正是进化算法加机器学习(强化+监督学习)。应该说, 这才是这套方法的灵魂(参见AlphaStar: An Evolutionary Computation Perspective)。
它的思想简直是对1994文章的升华, 把拉马克进化真正用起来。 也就是说, 我们把一个最外层的代系间的进化过程, 和内层的持续不断的强化学习结合起来。 内层的学习会影响外层的进化。 更重要的是, 在这里, 我们通过进化引入了不同参数的网络(智能体)间的博弈。 那些从一个根基上产生的稍有不同的网络, 会通过学习来改变自己, 并在战斗中一决雌雄, 当一轮结束, 优胜者将改写失败者的基因, 但失败者不会马上消失,正如文章中所说:
“The fittest solutions survive longer, naturally providing a form of elitism/hall of fame, but even ancestors that aren’t elites may be preserved, maintaining diversity.”
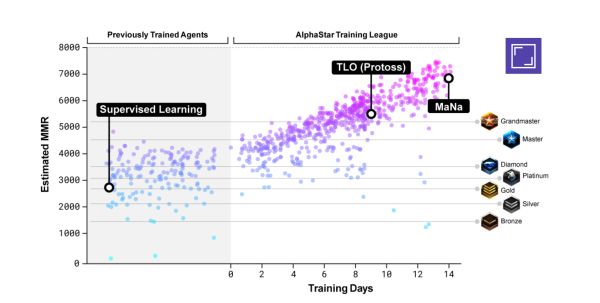
这样, 我们就鼓励了种群的多样性, 而得到一个在纳什均衡状态下多样化的解空间(一组不同策略的组合)。也就说, 最后的最优解不是一个网络, 而是一个策略集群。 如此, 我们就可以玩转很复杂的问题。 保持多样性的好处还是在之前的小姑娘采蘑菇的例子说的,任何优化都是在高低不平的空间里寻找最低点, 而在星际这样复杂的游戏中, 整个地形都在缓慢或迅速的变化着, 之前处于劣势的个体,可能在下一个拐点变成处于优势的。 这也是进化算法的温情之处, 世界是充满不确定性的,因此我不要斩尽杀绝。
正如schmidhuber在上一篇文章说的, 这一类损失函数对应的地形动态变化的问题里, 那些传统的优化问题甚至会完全失效(稳定性丧失), 而最后剩下的,会是进化算法。
deepmind的宣传稿里有一个非常好的例子, 我不是星际玩家, 但是你应该可以很快理解。 大意说的是在早期具有优势的策略(比如用某种武器迅速偷袭对方的高风险策略), 会随着时间发生变化, 有的时候, 这种变化完全不是之前基础的改进, 而是从完全不同的分支长出来的(比如早期通过增加工人取得经济优势,这与风险策略几乎相反,而这个策略后来居上)。如果你砍掉所有的分支, 你是否还能找到那个后期的优势策略呢? 那个后来最优的策略, 压根不是你先前的最优渐进发展出来的。
“As the league progresses and new competitors are created, new counterstrategies emerge that are able to defeat the earlier strategies. While some new competitors execute a strategy that is merely a refinement of a previous strategy, others discover drastically new strategies consisting of entirely new build orders, unit compositions, and micro-management plans.“
在进化算法和学习算法的结合里, 我们看到了一种AI发展的未来路径。 我们也看到了让AI从一个单个学习的网络, 发展到群体, 并通过群体间的合作和博弈促进发展的某种必要性。 在整个过程里, 我们看到人类自己智能产生和发展的影子。 这样的一条道路, 会给我们带来怎样的未来, 让我们拭目以待。
更多内容请关注作者新书

《深度学习》圣经"花书"经验法则中文版!
作者:Jeff Macaluso
https://jeffmacaluso.github.io/post/DeepLearningRulesOfThumb/

当我在研究生期间,第一次学习神经网络时,我问我的教授是否有任何关于选择架构和超参数的经验法则。他的回答是:“嗯,有点,但不...” - 毕竟神经网络的选择远远多于其他机器学习算法!在阅读 Ian Goodfellow,Yoshua Bengio和Aaaron Courville的深度学习书时,我一直在思考这个问题,并决定攥写本书中列出的一系列规则。事实证明,它们中有很多可以完成许多类型的神经网络和任务。

有趣的是,很多这些经验法则都没有得到很好的建立 - 深度学习仍然是一个相对较新的活跃研究领域,所以下面列出的很多都是研究人员最近发现的事情。
以下是我在阅读深度学习时所采用的更实用的注释。我在顶部包含了一个TL:DR来总结最重要的点,如果你没有很多时间,我建议你跳过下面第10节:实用方法论中的一些更重要的部分。
以下正文感谢 Cugty 同学的的翻译:
https://zhuanlan.zhihu.com/p/61528654
TL:DR
尽可能使用迁移学习。否则,对于已经是广泛研究的问题,先从复制网络结构开始。
网络结构应该总是由实验和验证误差来确定。
更深(层多),更浅(层少)的网络更难优化,但是更容易有更好的泛化误差。
一定要使用 early stopping(早停),两种方法:
在整个数据集上使用新的参数再次重新训练模型,在到达先前模型的早停点时停止训练。
保留早停点时的参数,继续在所有数据上训练,当平均训练误差降到原先早停点以下时停止。
使用 dropout 或许是个好主意。
使用 0.8 作为输入层的保留概率,0.5 作为隐层的保留概率。
dropout 会需要更大的网络和更长的迭代。
ReLU 是理想的激活函数。它也有缺陷,因此使用 leaky ReLU 或 noisy ReLU 或许有性能提升,但是会有更多的参数要调。
要得到差不多可以接收的性能,至少需要每个类 5000 个数据(>=10M可以达到人类的水平或更好)
如果低于 100,000个数据,使用 K 折交叉验证而不是 train/validation/test 划分的方法。
使用 GPU 能做到的最大的 batch size。
尝试不同 batch size,从 32 开始以 2 的指数增加到 256,对于太大的模型可以从 16 开始。
带动量和学习率衰减的随机梯度下降是个不错的开始。
动量超参数通常的值有 0.54, 0.9 和 0.99。可以随时间调整,从小值开始,然后增大。
或者,使用 Adam 或 RMSProp。
在分布式深度学习中使用异步 SGD。
学习率是最重要的超参数。如果时间有限,主要花时间来调它。
可以通过绘制学习曲线(目标函数随时间的变化)来观察学习率的情况
最优学习率通常高于前 100 次迭代后产生最佳性能的学习率,但不会高到出现不稳定的情况。
对于计算机视觉:
使用数据增强,只要图像没有本质上的改变。对比度归一化是另一个安全的预处理步骤。
批量归一化,池化和填充在 CNN 中经常使用。在批量归一化的情况下或许不需要 dropout。
对于自然语言处理:
LSTM 通常效果比其他网络好。
预训练的词嵌入(word2vec, word2glove 等)是很强大的方法。
随机搜索通常比网格搜索更快的收敛到好的超参数设置。
调试策略:
可视化模型:查看模型检测的图像样本,这对确定性能指标是否合理有帮助。
可视化最差的错误情况:这可以发现预处理和打标签中存在的问题。
当训练误差太高时先拟合一个小的数据集:这能检查出是欠拟合问题还是软件缺陷。
监视激活和梯度的直方图:完成大概一个 epoch。这能告诉我们神经元是否饱和及其饱和频率。梯度(值?)应该是参数的 1% 左右。
完整的笔记
第一部分 应用数学和机器学习基础
1. 介绍
每个类别至少需要大概 5000 个样本才能得到可接受的性能。大概每类需要 10M 个样本才能达到人类水平或更好。
4. 数值计算
在深度学习中,我们通常会陷入局部最优而不是全局最优,这是由于复杂性和非凸优化的问题。
5. 机器学习基础
如果模型具有最优的容量,但是在训练和测试误差之间仍有较大差距,去收集更多的数据来。
通常使用 20% 的训练集作为验证集。
如果数据少于 100000 个样本,使用k折交叉验证而不是训练/测试集划分的方法。
使用均方误差时,增加容量会降低偏差但是会增加方差。
贝叶斯方法在训练数据有限的时候泛化性能更好,但是训练样本较多时它的计算开销很大。
最常使用的损失函数是负对数似然。因此最小化损失函数也就是最大似然估计。
第二部分 深度网络:现代实践
6. 深度前馈网络
ReLU 对于前馈神经网络而言是一个完美的激活函数。
它所基于的原则是,接近线性的特性更加容易优化。
sigmoid 应该用于 ReLU 不能使用的情况。例如 RNN,很多的概率模型,和一些自动编码机。
在基于梯度的优化问题上,由于梯度消失的原因,交叉熵相比 MSE 和 MAE 更好。
ReLU 的优点:减少了梯度消失的概率,稀疏性,减少了计算量。
缺点:有死区 Dying ReLU。(leaky 和 noisy ReLU 解决了这个问题,但是引入了额外的参数)
大的梯度帮助学习更快,但是任意大会导致不稳定。
网络结构应该通过实验和监视验证集误差来确定。
更深的模型减少了用于表示函数的神经元数量,也降低了泛化误差。
直觉上说,更深的网络更好,因为我们在学习一系列函数。
7. 深度学习的正则项
最好在每层中使用不同的正则系数,但是使用相同的权重衰减。
使用早停 early stopping。这是一个很好调的超参数,而且也减少了计算量。
在整个数据集上使用新的参数再次重新训练模型,在到达先前模型的早停点时停止训练。
保留早停点时的参数,继续在所有数据上训练,当平均训练误差降到原先早停点以下时停止。
模型平均(bagging, boosting 等)基本上总会提高预测性能,虽然提高了计算量。
dropout 在宽层网络工作更好,因为它减少了从输入到输出的路径。
通常输入层 dropout 中的保留概率是 0.8,隐层的概率是 0.5。
使用 dropout 的模型通常要更大,迭代更长。
如果数据集足够大,dropout 没有太大帮助。另外,在很小(<5000)的训练样本上dropout的作用很有限。
批量标准化同样也引入了噪声,这提供了正则的作用,但也可能让 dropout 没有太大必要。
模型平均一般都工作得很好,因为不同的模型不太可能犯相同的错误。
dropout 通过创建子网络形成了一个高效的 bagging 方法。
8. 训练深度模型的优化
mini-batch 的大小(batch size):大的 batch size 会提供更大的梯度,但是通常内存是个限制条件。
让你的 batch size 在内存允许范围内尽可能大。
在 GPU 中,从 32 到 256 以 2 的指数级别增长,对于较大的模型可以从 16 开始。
小的 batch size 因为噪声的原因可能有正则的作用,但是会导致整体运行时间增加。这些情况下需要更小的学习率来提升稳定性。
深度学习模型有多个局部最优,但这没太大关系,因为它们都有相同的代价。最主要的问题是局部最优的损失比全局最优的损失大得多。
为了测试局部最优的问题,可以绘制梯度的范数来看它是否随时间衰减到一个非常小的值。
在高维非凸函数中鞍点比局部最优更常见,梯度下降对于鞍点相对来说更加鲁棒。
梯度裁剪(clipping)用于解决梯度爆炸的情况。这在 RNN 中是个常见的问题。
绘制出目标函数随时间的变化曲线来选择学习率。
最优学习率通常高于前 100 次迭代后产生最佳性能的学习率。监视前几次迭代,选择一个比表现最好的学习率更高的学习率,同时注意避免不稳定的情况。
使用高斯和均匀分布来初始看起来没有太大影响。
但是,对尺度(scale)有影响。大的初始权重会帮助避免冗余神经元,但是太大会有不利影响。
权重初始化可以看作是超参数,尤其是初始尺度稀疏或密集的情况。查看一个minibatch内激活或梯度的范围或方差来选择尺度。
没有一个优化算法明显由于其他,这主要取决于用户对超参数调整的熟悉情况。
随机梯度下降(SGD),带动量的SGD,RMSProp,带动量的RMSProp,AdaDelta,Adam都是流行的选择。注意:RMSProp在训练初期或许会有很高的偏差。
通常动量的值有0.5,0.9,0.99。这个超参数可以随时间变化,从一个小值开始增加到大的值。
Adam通常是较为鲁棒的选择。但是学习率通常要根据默认值改动。
对转化后的值(transformed value)而不是输入做批量归一化。在引入可学习的参数 β 下去掉偏置项。对于 CNN 在每个空间位置应用范围归一化(range normalization)。
太浅或太深的网络更难训练,但是他们有更好的泛化误差。
相对于一个强大的优化算法,选择容易优化的模型更重要。
9. 卷积网络
池化对于控制不同大小的输入是非常有用的。
0 填充可以让我们独立的设置卷积核大小和输出大小,而不会让维度衰减变成一个受限因素。
对于测试准确率而言最优的 0 填充通常在:
“valid 卷积”,不使用 0 填充,卷积核在图像范围内,但是每层输出会衰减。
“same 卷积”,使用足够的 0 填充让输出的大小等于输入大小。
一个潜在的验证卷积结构的方法是使用随机权重,并且只训练最后一层。
10. 序列模型:循环和递归网络
双向 RNN 在手写识别,语音识别和生物信息方面非常成功。
相比较 CNN 而言,RNN 用于图像通常更困难,但是可以让相同特征图中的特征进行远程横向交互。
无论何时 RNN 要表示长期依赖,长期交互的梯度要指数级别小于短期交互。
在回波状态网络中设置权重的技术可用于在完全可训练的 RNN 中初始化权重。初始光谱半径为 1.2,稀疏初始化性能良好。
实践中最有效的序列模型是门控 RNN,包括 LSTM 和 GRU。
LSTM 比简单的 RNN 更容易学到长期依赖。
给遗忘门加入偏置 1 可以让 LSTM 像 GRN 变种一样强大。
在 LSTM 中使用 SGD 通常考虑二阶优化方法来防止二次偏导消失。
设计一个容易优化的模型通常比设计一个强大的算法容易些。
正则参数鼓励“信息流”,并预防梯度消失,但是同样需要梯度裁剪来预防梯度爆炸。但是大量的数据例如语言建模对于 LSTM 而言就不是那么高效了。
11. 实践方法
在不确定的时候让模型拒绝决策也是很有帮助的,但是这之间也存在折中。收敛是机器学习算法可以响应的样本部分,和准确率之间也存在折中。
对于基线模型而言,ReLU 及其变种是理想的激活函数。
带动量和学习率衰减的 SGD 是基线优化算法中一个不错的选择。衰减方法包括:
线性衰减直到一个固定小的学习率。
指数衰减。
每次验证误差不变时减少 2 到 10 分之一。
另一个不错的基线优化算法是 Adam。
如果优化出现了问题,立马使用批量归一化。
如果训练集不足 10M,一开始就采用中等强度的正则项。
基本上肯定要用 early stopping。
在大多数结构中 dropout 是个不错的选择。批量归一化也是个可选的替代品。
如果当前的问题已经被研究烂了,直接拷贝模型就是个不错主意,或许可以拷贝训练过的模型。
如果已知无监督学习对于你的应用很重要(例如 NLP 中的词嵌入),那么在基线中就把它包含进来。
决定什么时候收集更多的数据:
如果无法获得更多的数据,最后的办法是尝试提升学习算法。
使用对数比例的学习曲线来决定还需要多少数据。
如果训练性能很差,增加模型的大小,调整学习算法。如果还是很差,那是数据质量问题,重新开始收集更干净的数据或更多的特征。
如果训练性能不错但是测试性能很差,在可行的情况下收集更多的数据。或者,尝试降低模型的大小或增加正则强度。如果这些没有帮助,那你的确需要更多的数据。
学习率是最重要的超参数,因为它以一种复杂的方式控制着模型的有效容量。如果时间有限,就调它。调其他的超参数需要监视训练和测试误差来判断模型是欠拟合还是过拟合。
如果训练误差高于目标误差,增加容量。如果没有使用正则项,并确定优化算法工作正确,使用更多的隐层。
如果测试误差高于目标误差。那么较大的模型加合适的正则会带来最好的性能。
只要训练误差很低,你总是可以通过收集更多数据来减低泛化误差。
网格搜索:通常在少于四个超参数时使用。
通常最好使用对数尺度来挑选值,并且不断重复来减少搜索范围。
计算量随着超参数的数量指数增加,即使是并行也不能有很好的帮助。
随即搜索:使用起来很简单,相比于网格搜索更快收敛到好的超参数。
在几个超参数不是很强烈的影响性能指标时,随机搜索相对于网格搜索可以达到指数级别的效率。
我们也许要重复运行它来得到更好的结果。
随机搜索比网格搜索快,因为它不需要指数级别的运行。
通常不建议基于超参数来调整模型,因为它很少超过人类并且经常失败。
调试策略:
可视化模型的行为。例如,查看图像样本,和模型检测情况。这可以看到量化的性能指标是否合理。
可视化最差的错误情况:这可以发现预处理和打标签中存在的问题。
当训练误差太高时先拟合一个小的数据集:这能检查出是欠拟合问题还是软件缺陷。
监视激活和梯度的直方图:完成大概一个 epoch。这能告诉我们神经元是否饱和及其饱和频率。梯度值应该是参数的1%左右。稀疏的数据(如 NLP)有很多参数很少更新,一定要记得这一点。
12. 应用
在分布式系统中,使用异步 SGD。每一步的平均提升是很小的,但是步骤速率加快也导致了整体的加快。
级联(cascade)分类器是目标检测中一个高效的方法。一个分类器有高召回率,另一个有高精确率,好的,结果有了。
集成方法中一个减少推理时间的方法是训练一个控制器来挑选哪个网络应该来做推理。
标准化像素尺度是计算机视觉中唯一一个强制的预处理步骤。
对比度归一化通常是一个安全的计算机视觉预处理步骤。
尺度参数或者可以设置为 1,或者让每个像素在整体样本上有接近1的标准梯度。
近似剪切的图像数据集可以安全的设置 λ=0, ϵ=1e−8。
小的随机剪切的图像数据集需要更高的正则强度,例如 λ=10, ϵ=0。
全局对比度归一化(GCN)是其中一个方法,但是它在低对比度的情况下会降低边缘的检测。
局部对比度归一化通常可以用分离卷积计算特征图的局部均值/方差来实现,然后在不同的特征图上做元素级别减/除。相比于全局对比度归一化更能凸显边缘。
在 NLP 的实践中,分层 softmax 相比于基于采样的方法测试结果更差。
第三部分 深度学习研究
13. 线性因子模型
线性因子模型可以扩展到自动编码器和深度概率模型,它们做相同的任务但是更灵活更强大。
14. 自动编码器
稀疏自动编码器在学习特征如分类等任务上表现不错。
自动编码器在学习隐含变量解释输入方面很有用。它们可以学到有用的特征。
虽然很多自动编码器只有一个编码/解码层,但它们有深度前馈网络一样的优点。
在强化对比度例如稀疏性方面尤其有用。
深度减少了指数级别的计算量,以及表示某些函数所需训练数据的数量。
通常训练深度编码器的方法是通过一系列浅的自动编码器来贪心的预训练深度结构。
15. 表示学习
在深度学习中,一个好的表示可以让后续的学习任务更加容易。例如监督前馈网络:每一层都为最后的分类层学习一个更好的表示。
贪心的层间无监督训练对于分类测试误差有帮助,但是其他任务上不行。
对于图像分类没啥作用,但是对于 NLP 很有帮助(例如词嵌入),这是因为初始表示非常差。
在标签样本很少,或无标签样本很大的时候,正则器非常有用。
在要学习的函数极其复杂的时候它最有用。
根据监督阶段的验证集误差来选择预训练阶段的超参数。
无监督预训练基本已经被抛弃了,除了 NLP 领域(例如词嵌入)。
在有些特征对于不同的任务设置有帮助的时候,迁移学习,多任务学习和域适应都可以通过表示学习来完成。
当一个很复杂的结构可以用更少的参数紧凑表示时,分布式表示相比于非分布式表示更具有统计优势。一些传统的非分布式算法能泛化是由于其平滑的假设,但是会受限于维度诅咒。
16. 深度学习的结构化概率模型
结构化概率模型提供了一个框架,用于对随机间隔的直接交互进行建模,这使得模型可以使用更少的参数。正因为此,他们可以在更少的数据下可靠地估计,并且减少了存储模型,执行推理和采样的计算量。
很多深度学习的生成模型或没有隐含变量,或这用一层隐含变量。他们在模型中使用深度计算图来定义条件分布。这和大部分深度学习应用中有比可观察变量更多的隐含变量形成强烈对比。他们是从非线性交互中学得的。
深度学习中的隐含变量是不受限的,但是很难通过可视化来解释。
循环信念传播(loopy belief propagation)基本上在深度学习中从未使用,因为大部分深度学习模型是使用吉布斯采样或变分推断算法设计的。
17. Monte Carlo方法
Monte Carlo Markov Chains(MCMC)计算量很大,这是由于在平衡分布“燃烧”需要的时间,以及为了保证样本间不相关而让每n个样本有序。
当在深度学习中从MCMC采样时,通常需要运行一定数量的并行马尔科夫链,数量与一个minibatch的样本数一样,让后从中采样。通常使用的数字是100。
马尔科夫链会到达平衡状态,但我们不知道要多久,除非它已经到达了。我们可以测试它是否混合了启发式方法,比如手动检查样本或测量连续样本之间的相关性。
虽然 Metropolis-Hastings 算法在其他学科中经常与马尔可夫链一起使用,但 Gibbs 抽样是深度学习的 de-facto 方法。
19. 近似推断
Maximum a posteriori (MAP) 推断通常用于特征提取和学习机制,主要是稀疏编码模型。
20. 深度生成模型
玻尔兹曼机的变种早已超过了最初的流行度。玻尔兹曼机对于观察变量就像一个线性预测器,但是对于未观察到的变量更加强大。
从一系列受限玻尔兹曼机中初始化一个深度玻尔兹曼机时,稍微修改下参数是很有必要的。
今天很少使用深度信念网络(DBN),因为其他算法已经超过它了,但是在历史上有重要地位。由于 DBN 是生成模型,一个训练过的 DBN 可以用于初始化一个 MLP 的权重来做分类。
【略去玻尔兹曼机的部分内容】
虽然变分自动编码器(VAE)很简单,但是它们通常能得到不错的结果,也是最后的生成模型之一。来自 VAE 的图像通常模糊,原因未知。
不收敛是 GAN 欠拟合(一个网络抵达局部最优,另一个抵达局部最大)的一个问题,但是这个问题的长度还不清楚。
虽然 GAN 有稳定性的问题,但是通常在精心选择的模型和超参数情况下效果很不错。
GAN 的一个变种 LAPGAN,从低分辨率开始不断加入细节,它的结果经常能骗过人类。
为了保证 GAN 的生成器不会在任意点变成0概率,需要在最后一层给所有图像加入高斯噪声。
在 GAN 的判别器中一定要使用 dropout,不这样做结果很差。
生成矩匹配网络的视觉样本令人失望,但可以通过将它们与自动编码器结合来改进。
在生成图像时,使用转置卷积操作通常会产生更真实的图像,相比于没有参数共享的全连接层使用更少的参数。
即使在卷积生成网络中上采样的假设不真实,但是生成的样本总体来说还是不错的。
虽然有很多使用生成模型的方法来生成样本,MCMC 采样,ancestral sampling 或把二者结合是比较流行的做法。
当比较生成模型时,预处理的改变(即使很小,很微妙)是完全不能接收的,因为它会改变分布从而根本上改变了任务。
如果通过观察样本图片来衡量生成模型,最好在不知道样本源的情况下去做实验。另外,由于一个差的模型也可能产生好的样本,必须确保模型不是仅仅复制了训练图片。使用欧氏距离来进行检查。
如果计算上可行的化,最好的衡量生成模型样本的方法是评估模型分配给测试数据的对数似然。这个方法也有缺陷,例如一个固定的简单图片(如空白背景)有很高的似然。
生成模型有很多用处,因此根据用途来挑选评估指标。
例如,一些生成模型更擅长为最真实的点分配高概率,而其他一些模型给不真实的点不分配高概率做的更好。
即使当指标缩小到最合适的任务上,所有的指标也都有很严重的问题。

先进制造业+工业互联网
产业智能官 AI-CPS
加入知识星球“产业智能研究院”:先进制造业OT(自动化+机器人+工艺+精益)技术和工业互联网IT技术(云计算+大数据+物联网+区块链+人工智能)深度融合,在场景中构建“状态感知-实时分析-自主决策-精准执行-学习提升”的机器智能、认知计算系统;实现产业转型升级、DT驱动业务、价值创新创造的产业互联生态链。

版权声明:产业智能官(ID:AI-CPS)推荐的文章,除非确实无法确认,我们都会注明作者和来源,涉权烦请联系协商解决,联系、投稿邮箱:erp_vip@hotmail.com。




