【干货】机器学习基础算法之随机森林
【导读】在当今深度学习如此火热的背景下,其他基础的机器学习算法显得黯然失色,但是我们不得不承认深度学习并不能完全取代其他机器学习算法,诸如随机森林之类的算法凭借其灵活、易于使用、具有良好的可解释性等优势在工业界以获得良好的应用。本文主要介绍随机森林的工作原理、特征重要性、优势和劣势、使用例子等,让我们一起了解一下这个简单易用的机器学习基础算法吧。

The Random Forest Algorithm
随机森林算法
随机森林是一种灵活且易于使用的机器学习算法,即使没有进行超参数调整,也可以在大多数情况下产生很好的结果。 它也是最常用的算法之一,因为它很简单,并且可以用于分类和回归任务。 在这篇文章中,您将学习如何使用随机森林算法以及其他一些关于它的重要的事情。
▌工作机制
随机森林是一个监督学习算法。 就像你已经看到它的名字一样,它创建了一个森林,并以某种方式使它成为随机的。 它构建的“森林”是决策树的集合体,大部分时间都是用“装袋(bagging)”方法训练的。 装袋方法的总体思路是,多个模型通过组合可以显著的比单个模型要好, 可以用来增加整体效果。
简单来说:随机森林建立多个决策树并将它们合并在一起以获得更准确和稳定的预测。
随机森林的一大优势是,它可以应用于分类和回归问题,目前大多数机器学习系统都是围绕这两个问题进行的。 我将在分类问题中讨论随机森林,因为分类问题有时被认为是机器学习的基石。 在下面你可以看到两棵树构成随机森林的样子:
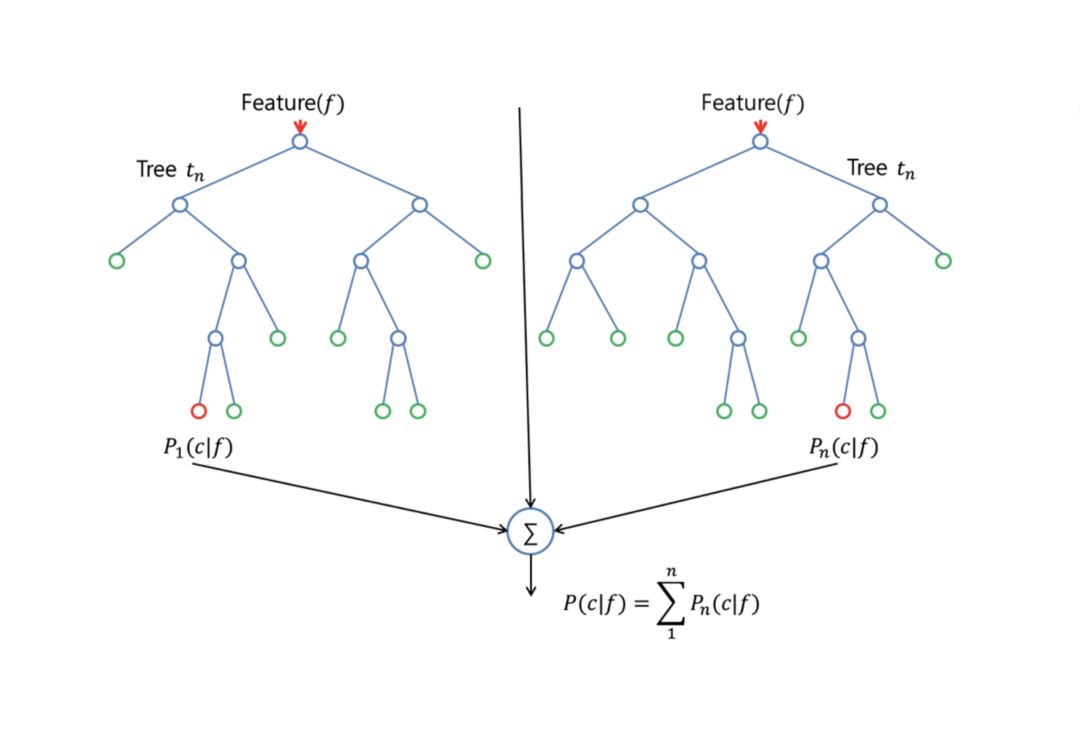
除了少数例外,随机森林分类器具有决策树分类器的所有超参数以及bagging分类器的所有超参数,这些超参数用以控制集合本身。与其构建bagging分类器并将其传递给决策树分类器,您可以仅使用随机森林分类器,这更加方便优化。请注意,还有一个用于回归任务的随机森林回归器。
随机森林算法在树木生长时会给模型带来额外的随机性。不是在分割节点时搜索最佳特征,而是在特征的随机子集中搜索最佳特征。这个过程产生了广泛的多样性,这通常会得到更好的模型。
因此,当您在随机森林中构建一棵树时,仅考虑用于分割节点的随机子集。您甚至可以通过在每个特征上使用随机阈值来使树更随机,而不是像正常的决策树一样搜索最佳阈值。
▌类比现实生活
想象一下,一个名叫安德鲁的人,想要决定在一年的假期旅行中他应该去哪些地方。他询问认识他的人的建议。首先,他去找一位朋友,他问安德鲁他过去去过的地方,如果他喜欢或不喜欢。基于这些答案,他会给安德鲁一些建议。
这是一种典型的决策树算法方法。安德鲁斯的朋友通过使用安德鲁的答案创建了规则来指导应该推荐什么的决定。
之后,安德鲁开始要求越来越多的朋友给他建议,他们再次问他不同的问题,他们可以从中得到一些建议。然后他选择推荐给他的地方,这是典型的随机森林算法方法。
▌特征重要性
随机森林算法的另一个优点是可以很容易地衡量每个特征对预测的相对重要性。 Sklearn提供了一个很好的工具,通过查看有多少使用该特征的树节点(这些树节点使用该特征减少了森林中所有树木的杂质),从而衡量了特征的重要性。它在训练后为每个特征自动计算特征重要性分数并对结果进行归一化,以使所有重要性的总和等于1。
如果你不知道决策树如何工作,如果你不知道叶子或节点是什么,这里有一个来自维基百科的很好的描述:在决策树中,每个内部节点代表一个属性的“测试”(例如每个分支代表测试的结果,并且每个叶节点代表一个类标签(在计算所有属性之后作出的决定),没有孩子的节点是叶子。
通过查看特征的重要性,您可以决定您可能要放弃哪些特征,因为它们对预测过程没有足够贡献或没有贡献。这很重要,因为机器学习的一般规则是您拥有的特征越多,您的模型就越容易过拟合,反之亦然。
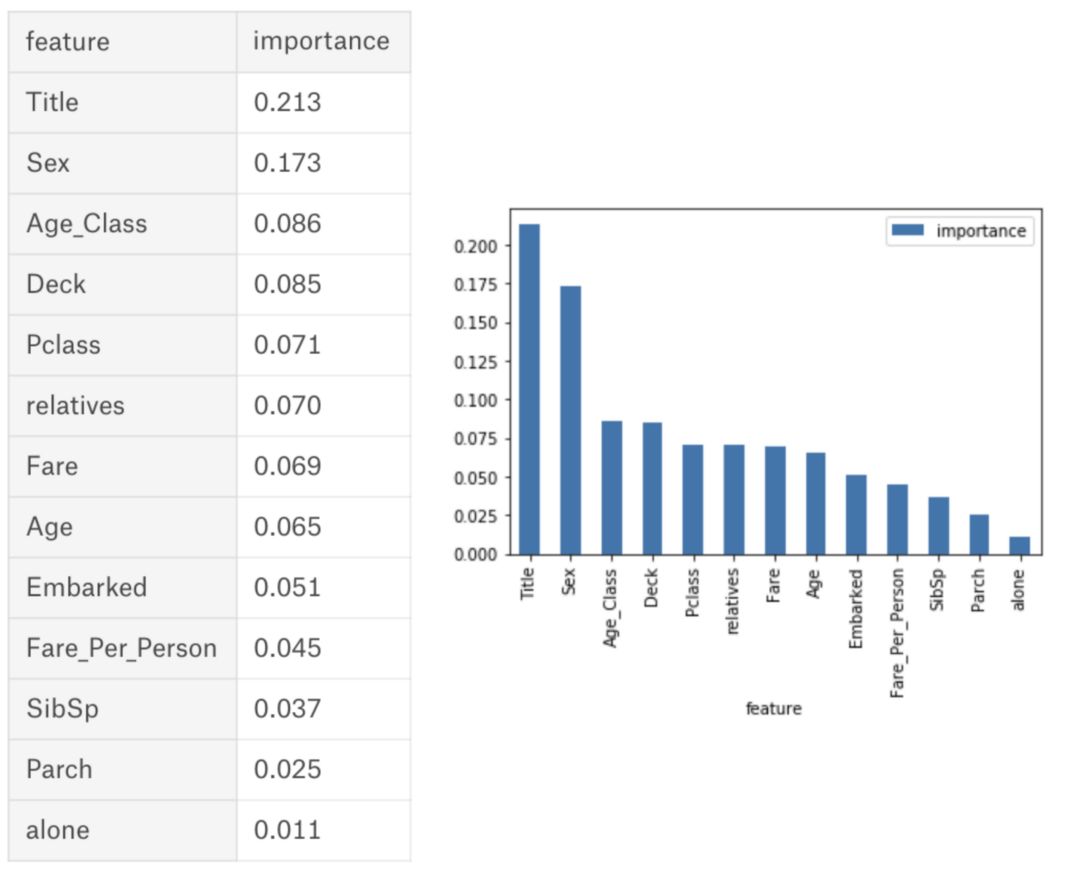
下面你可以看到一个表格和一个可视化图表,显示了13个特征的重要性,我在我的监督分类项目中使用了kaggle上著名的Titanic数据集。
https://www.kaggle.com/niklasdonges/end-to-end-project-with-python
▌决策树和随机森林之间的区别:
就像我之前提到的,随机森林是决策树的集合,但是有一些区别。
如果您将具有特征和标签的训练数据集输入到决策树中,它将制定一些规则集,这些规则被用于预测。
例如,如果您想预测某人是否会点击在线广告,则可以收集该广告的过去点击人员以及描述其决定的某些功能。如果将特征和标签放入决策树中,它将生成节点和一些规则。然后你可以预测广告是否会被点击。当决策树生成节点和规则时,它通常使用信息增益和基尼指数计算。相比之下,随机森林是随机的。
另一个区别是“深度”决策树可能会因过拟合而受到影响。随机森林可防止大部分过拟合,方法是创建随机的特征子集并使用这些子集构建较小的子树。之后,它组合这些子树。请注意,这也会使计算速度变慢,这取决于随机森林构建的子树数量。
▌重要的超参数
随机森林中的参数要么用来增加模型的预测能力,要么使模型更快。我将在这里讨论sklearns内置的随机森林函数的超参数。
1.提高预测能力
首先,存在“n_estimators”超参数,它是控制随机森林中树的数量。一般来说,树数量越多,性能越好,预测越稳定,但也会减慢计算速度。
另一个重要的超参数是“max_features”,它是允许随机森林在单个树中尝试的最大特征数量。 Sklearn提供了几个选项,在他们的文档中有描述。
http://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html
我们将讨论在速度方面的一个重要的超参数是“min_sample_leaf”。正如其名称所述,这决定了叶子的数量。
2.提高模型速度
“n_jobs”超参数告诉引擎允许使用多少个处理器。如果它的值为1,它只能使用一个处理器。值“-1”表示没有限制。
“random_state”使模型的输出可复制。当它具有一个明确的random_state值并且它已经被赋予了相同的参数和相同的训练数据时,该模型将始终产生相同的结果。
最后,还有一个“oob_score”(也称为oob采样),它是一种随机森林交叉验证方法。在这个抽样中,大约三分之一的数据不用于训练模型,可用于评估其性能。这些样品被称为袋外样品。它与一次性交叉验证方法非常相似,但几乎没有附加的计算负担。
▌优缺点
就像我之前提到的那样,随机森林的一个优点是它可以用于回归和分类任务,并且很容易查看它分配给输入特征的相对重要性。
随机森林也被认为是一个非常方便和易于使用的算法,因为它是默认的超参数通常会产生一个很好的预测结果。超参数的数量也不是那么高,而且它们很直观易懂。
机器学习中的一个重大问题是过度拟合,但大多数情况下,对于随机森林分类器来说并不容易出现过拟合。那是因为如果森林中有足够的树,分类器将不会过拟合。
随机森林的主要限制是大量的树会使算法变慢不能应对实时预测场景。一般来说,这些算法训练速度很快,但一旦训练完成就很难创建预测。更准确的预测需要更多的树,导致模型更慢。在大多数现实世界的应用中,随机森林算法速度可以满足要求,但在时间性能要求更高的场景中,其他方法可能更受欢迎。
当然,随机森林是一个预测性建模工具,而不是一个描述性工具。这意味着,如果您正在寻找关于数据中关系的描述,其他方法将是首选。
▌例子
随机森林算法被用于很多不同的领域,如银行,股票市场,医药和电子商务。在银行业中,它被用来检测那些比其他人更频繁地使用银行服务的客户,并及时偿还债务。在这个领域,它也被用来检测欺诈客户,即谁想诈骗银行。在金融领域,它用于确定未来股票的行为。在医疗保健领域,它用于识别医学成分的正确组合,并分析患者的病史以识别疾病。最后,在电子商务中,随机森林被用来确定客户是否真的喜欢这个产品。
▌总结
随机森林是一个很好的算法,可以在模型开发初期了解它是如何执行的,并且由于其简单性,很难构建“坏”随机森林。如果您需要在短时间内开发模型,该算法也是一个很好的选择。最重要的是,它可以只是您的特征的重要性。
随机森林在性能方面也很难被击败。当然,你可能总能找到一个性能更好的模型,比如神经网络,但是这些模型通常需要更多的时间来开发。最重要的是,它们可以处理许多不同的特征类型,如二元的,数字的。
总的来说,随机森林是一个(基本上)快速,简单和灵活的工具,尽管它有其局限性。
参考文献:
https://towardsdatascience.com/the-random-forest-algorithm-d457d499ffcd
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!
点击“阅读原文”,使用专知



