专栏 | Detectron精读系列之一:学习率的调节和踩坑
机器之心专栏
作者:huichan chen
大家期盼已久的 Detectron 终于开源啦,state-of-the-art 的模型就在一个命令行之间。但是面对庞大的 caffe2 和 detectron 函数库,多少会感觉有些迷茫。Detectron 精读系列会从细小的调参开始,到一些重要的函数分析,最后掌握 Detectron 函数库的全貌。在这个过程中,我们也会帮大家提前踩坑,希望大家可以从 Detectron 函数库学到更多通用的计算机视觉技能。
Detectron 函数库有一点复杂,在这次的解读中我们主要介绍 multi-gpu 训练的时候,学习率如何调节的问题。看似简单的问题,最近 Facebook,Google 和 Berkeley 多个组都发表了论文对这一问题进行了理论和实验的讨论,首先我们对这些论文的结果做一个简要的总结。三篇论文研究类似,但是每一篇相对于前一篇都有改进。
Facebook : Training Imagenet in 1 hour
贡献:
提出了 Linear Scaling Rule,当 Batch size 变为 K 倍时,Learning rate 需要乘以 K 就能够达到同样的训练结果。看似简单的定律,Facebook 的论文给出了不完整的理论解释和坚实的实验证明。除此之外,论文还讨论了如何处理 Batch Normalization 如何实现分布式 SGD。通过 Linear Scaling Rule,Facebook 成功的在一小时内训练了 Batch size 为 8192 的 Resnet 50。
缺陷:
当 Batch Size 超过 8000 时观测到了模型训练结果会严重变差。如下图:
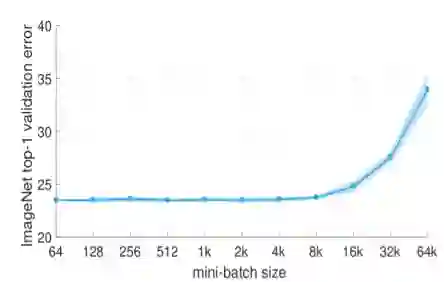
Berkeley : Large Batch Training of Convolution Networks
Berkeley 的组发现 Facebook 提出的 Linear Scaling Rule 当 Batch Size 过大时训练不稳定,容易发散。并且当模型 Batch Size 超过 8000 时,结果会严重退化。作者提出了 Layer Wise Adaptive Rate Scaling(LARS)定律,从而能够在 Batch Size 为 32000 的情况下高效的训练 ResNet 50 网络。SGD 的权值更新等于梯度乘以 Learning rate,论文中作者提出了 global learning rate 和 local learning rate 决定,global learning rate 所有层共享,local learning rate 由梯度的变化速率决定,这一想法是受 ADAM 等 adaptive learning rate SGD 的方法的影响。下表格为 LARS 的训练结果:
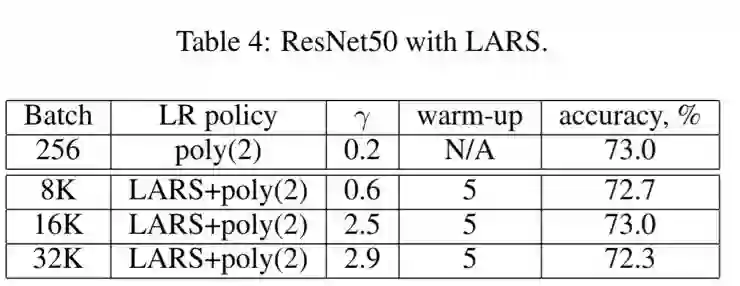
Google : Don’t decrease the learning rate, increase the batch size
LSR 和 LARS 大大的提高了模型的并行性,但是不能够提高模型的结果。Google 组的研究发现,通过增大 Batch Size 保持 Learning rate 不变的办法可以得到与 decreasing learning rate 类似的学习曲线,并且将 batch size 进一步扩大到了 65536,整个模型的训练过程只需要 2500 次参数更新。
收获与总结:
三篇论文通过理论和实验证明了 large batch size 能够加快模型的训练速度。面对动则几百块的 GPU,很多人对这三篇论文望而却步。其实本文提出的 idea 可以在 Faster RCNN,Mask RCNN 中得到很好的应用,我们只需要使用 multi-GPU,并且根据 Linear Scaling Rule 来调节学习旅就可以大大的提高 Detection 网络的训练速度,并且还有可能得到更好的结果。
Detectron Linear Scaling Rule Example
Detectron 库的 toy example 已经给大家展示如何使用 Linear Scaling Rule
python2 tools/train_net.py \
--cfg configs/getting_started/tutorial_1gpu_e2e_faster_rcnn_R-50-FPN.yaml \
OUTPUT_DIR /tmp/detectron-output
python2 tools/train_net.py \
--cfg configs/getting_started/tutorial_2gpu_e2e_faster_rcnn_R-50-FPN.yaml \
OUTPUT_DIR /tmp/detectron-output
python2 tools/train_net.py \
--cfg configs/getting_started/tutorial_4gpu_e2e_faster_rcnn_R-50-FPN.yaml \
OUTPUT_DIR /tmp/detectron-output
python2 tools/train_net.py \
--cfg configs/getting_started/tutorial_8gpu_e2e_faster_rcnn_R-50-FPN.yaml \
OUTPUT_DIR /tmp/detectron-output
对应的 config 文件如下:
1 GPUs:
BASE_LR: 0.0025
MAX_ITER: 60000
STEPS: [0, 30000, 40000]
2 GPUs:
BASE_LR: 0.005
MAX_ITER: 30000
STEPS: [0, 15000, 20000]
4 GPUs:
BASE_LR: 0.01
MAX_ITER: 15000
STEPS: [0, 7500, 10000]
8 GPUs:
BASE_LR: 0.02
MAX_ITER: 7500
STEPS: [0, 3750, 5000]
Large Batch Size 的初始训练不稳定,需要使用 warm up schedule 进行学习旅调整,具体论文在 lib/utils/lr_policy.py 中实现。
Mxnet Faster RCNN Linear Scaling Rule Testing
Linear Scaling Law 简单的让人难以相信,为了真实的测定这一定律是适用于 faster rcnn,我们在 mxnet faster rcnn github 上面测试了该定律。我们分别测定了不使用 Linear Scaling Law 的 faster rcnn 跟使用 Linear Scaling Law 的结果。从结果分析使用 Linear Scaling Law 能够加速训练,并且还有可能得到更高的准确率。训练集和测试集分别为:VOC 07 和 VOC 07 test 实验结果如下:
nohup bash script/resnet_voc07.sh 0,1 0.001 &> resnet_voc07.log &
nohup bash script/resnet_voc07.sh 0,1,2,3 0.002 &> resnet_voc07.log &
nohup bash script/resnet_voc07.sh 0,1,2,3,4,5,6,7 0.004 &> resnet_voc07.log &
Learning rate / GPUs / MAP / training sample per second
0.001 / 2 / 70.23 / 4
0.002 / 4 / 71.43 / 6
0.004 / 8 / 70.98 / 9
0.001 / 4 / 66.50 / 6
0.001 / 8 / 65.00 / 9
Detectron 函数库训练踩坑录 (o^^o)
Detectron 条理清楚,但是免不了有一些小的 bug,下面我们就给大家分享一下我们遇到的小坑。
踩坑 1
Config 中大多数参数是为 8 路 GPU 准备的,直接把 GPU 数目改为 1 会让结果变为 NAN。
Solution
根据 Linear Scaling Law 请自行降低学习率,减少 batch size 会增大梯度的不准确性,这时候大的学习率会让神经网络 diverge。
踩坑 2
Multi GPU 训练的时候会 out of memory。错误如下:
terminate called after throwing an instance of 'caffe2::EnforceNotMet'what(): [enforce fail at context_gpu.h:230] error == cudaSuccess. 4 vs 0. Error at: /home/huichan/caffe2/caffe2/caffe2/core/context_gpu.h:230: unspecified launch failure Error from operator:input: "gpu_0/res5_0_branch2c_w_grad" output: "gpu_2/res5_0_branch2c_w_grad" name: "" type: "Copy" device_option { device_type: 1 cuda_gpu_id: 2 }terminate called recursively*** Aborted at 1516782983 (unix time) try "date -d @1516782983" if you are using GNU date ***terminate called recursivelyterminate called recursivelyterminate called recursivelyterminate called recursivelyterminate called recursivelyterminate called recursivelyterminate called recursivelyterminate called recursively
Solution
Facebook 已经发现了这一错误,对 lib/utils/subprocess.py 进行了及时的修改。
踩坑 3
我们使用 multi GPU 训练的时候会出现服务器重启,初步怀疑 memory leakage,我们已经将该问题反馈回了 Facebook,如果遇到相同问题的同学,请稍加等候。
祝大家学习顺利……(o^^o)

本文为机器之心专栏,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com

