霸榜马里奥赛车,谷歌将神经进化引入自解释智能体,强化学习训练参数锐减1000倍

新智元报道
【新智元导读】最近,谷歌的研究人员发现神经进化方法非常适合训练基于视觉的强化学习(RL)任务的自注意力结构,使研究人员能够合并一些模块,包括对智能体有用的一些不可微分的操作,从而解决具有挑战性的视觉任务如马里奥赛车,其参数至少降低了 1000 倍。「新智元急聘主笔、高级主任编辑,添加HR微信(Dr-wly)或扫描文末二维码了解详情。」

心理学中有一种现象叫选择性失明,会使人们看不见东西。选择性关注使我们能够专注于信息的重要部分,而不会将精力分散到无关紧要的细节,而谷歌的这篇强化学习论文正是受此启发。
受神经科学启示,发现高效编码方法

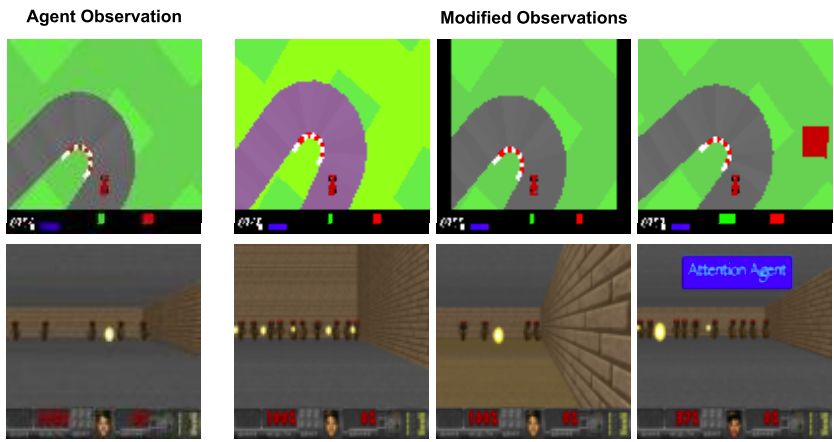
试水马里奥赛车
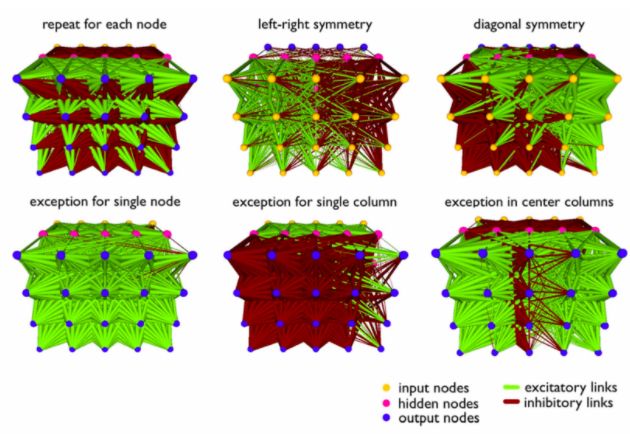
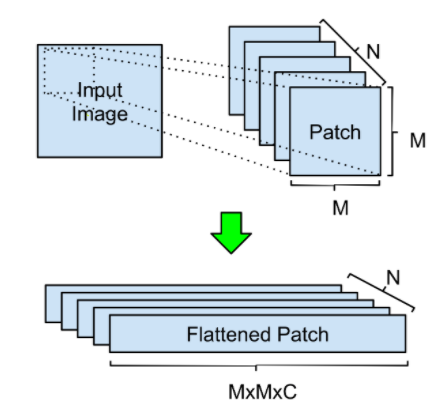
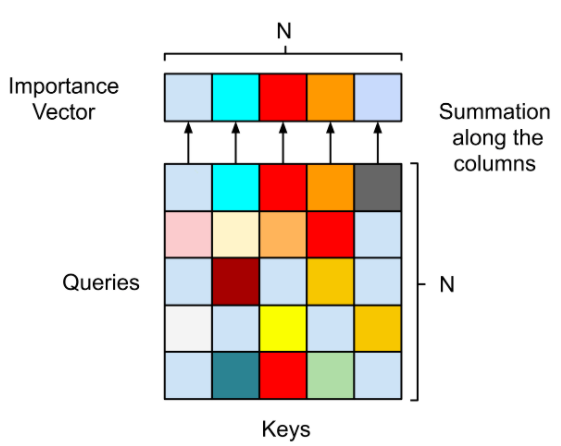
引入 self-attention 进行数据处理
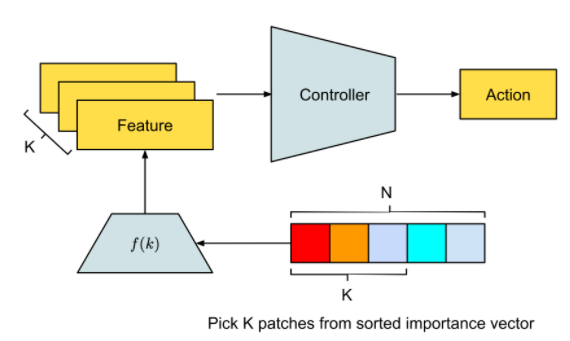
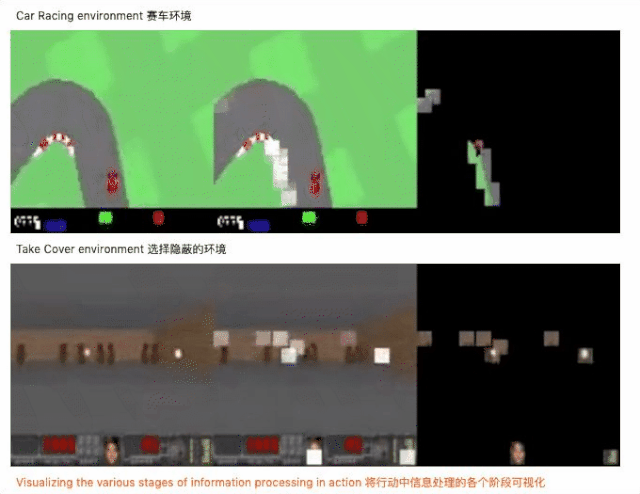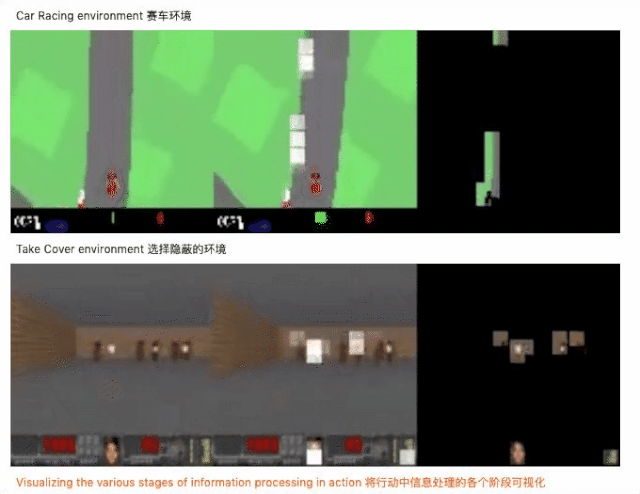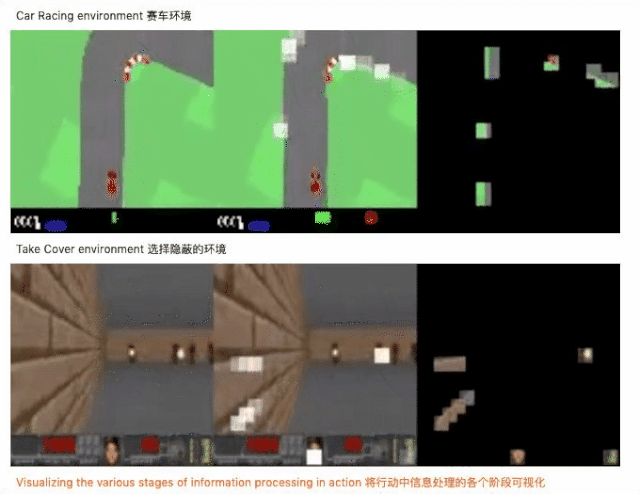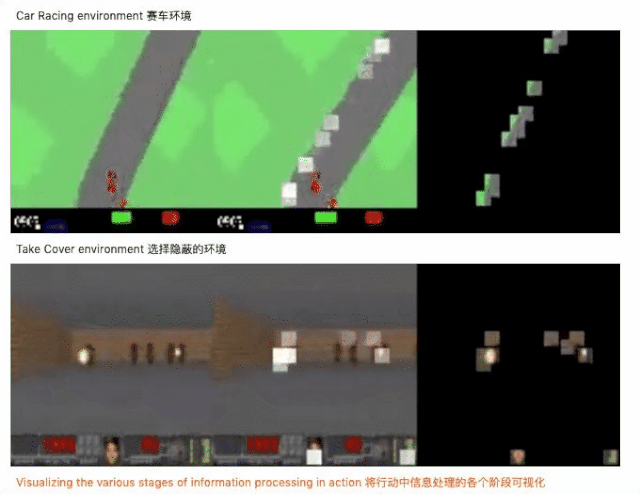
不仅达成目标,参数还锐减 1000 倍
结构设计好之后,开始用神经进化算法对自注意力模块和控制器的参数进行训练,神经进化为什么是训练自注意力智能体的理想方法呢?因为神经进化可以去除基于梯度方法的不必要的复杂性,从而使计算更简单。此外,我们还用一些模块来增强自注意力的有效性,下面是实验的结果。

人工智能吹响了智能大航海时代的号角,AI也成为抗疫救灾的技术主题词。新智元特推出“AI方舟”直播公开课,依托“AI开放创新平台”小程序,邀请一线AI技术专家分享实战经验,带你一起驶向载满干货的新航程。


登录查看更多
相关内容
Arxiv
7+阅读 · 2018年5月25日





相关VIP内容
相关资讯
相关论文
Arxiv
7+阅读 · 2018年5月25日