IJCAI 2020丨近期必读七篇【深度强化学习】论文

根据AMiner-IJCAI 2020词云图,小脉发现表征学习、图神经网络、深度强化学习、深度神经网络等都是今年比较火的Topic,受到了很多人的关注。今天小脉给大家分享的是IJCAI 2020七篇必读的深度强化学习(Deep Reinforcement Learning)相关论文。


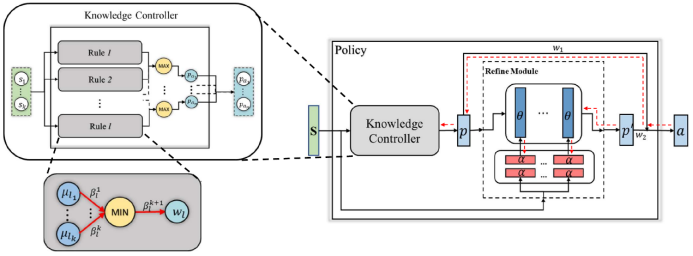
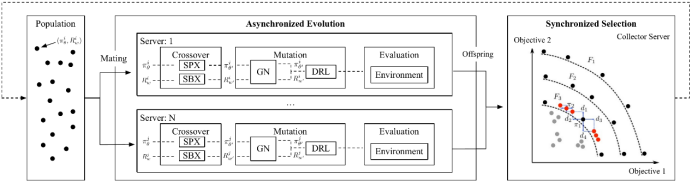

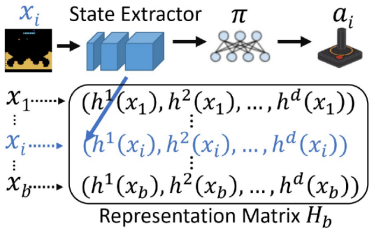
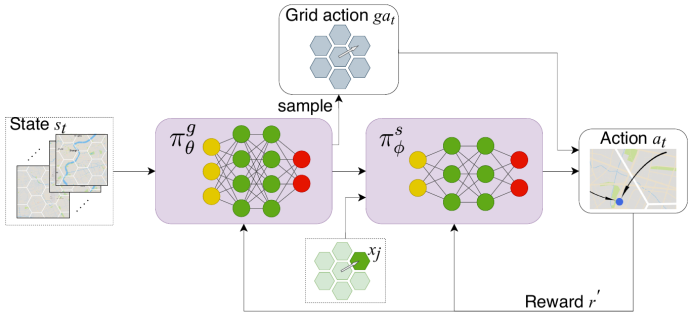





登录查看更多
相关内容

Arxiv
16+阅读 · 2019年12月16日



相关VIP内容
相关资讯
相关论文
Arxiv
16+阅读 · 2019年12月16日