AI也可以脑补画面了吗?

一 导读
二 文章框架
1 AI的想象力?


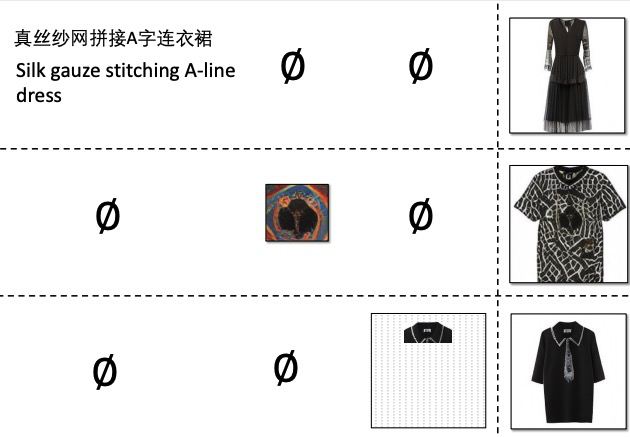
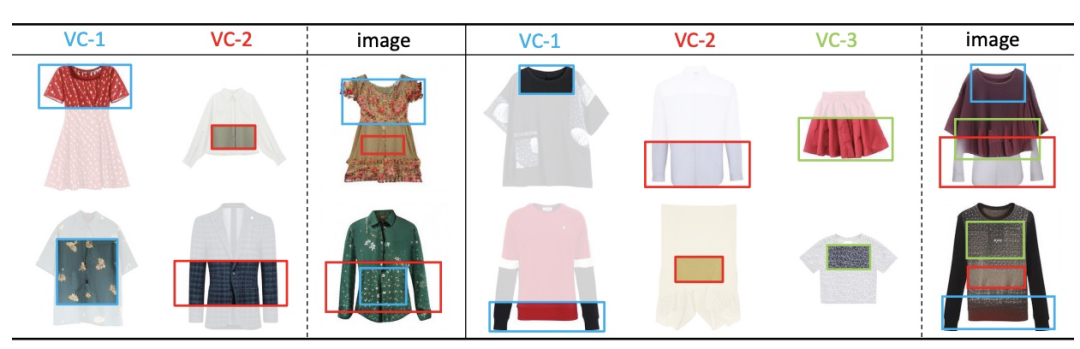

2 一个多模态控制下的图像生成模型

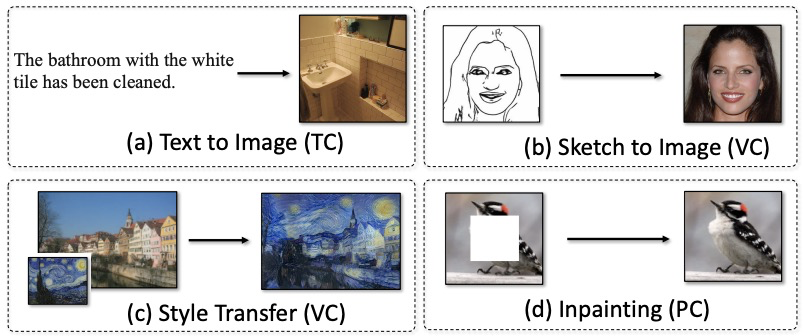
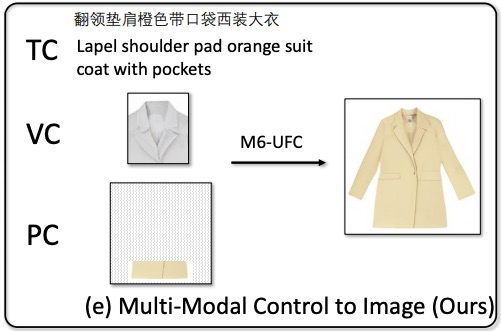
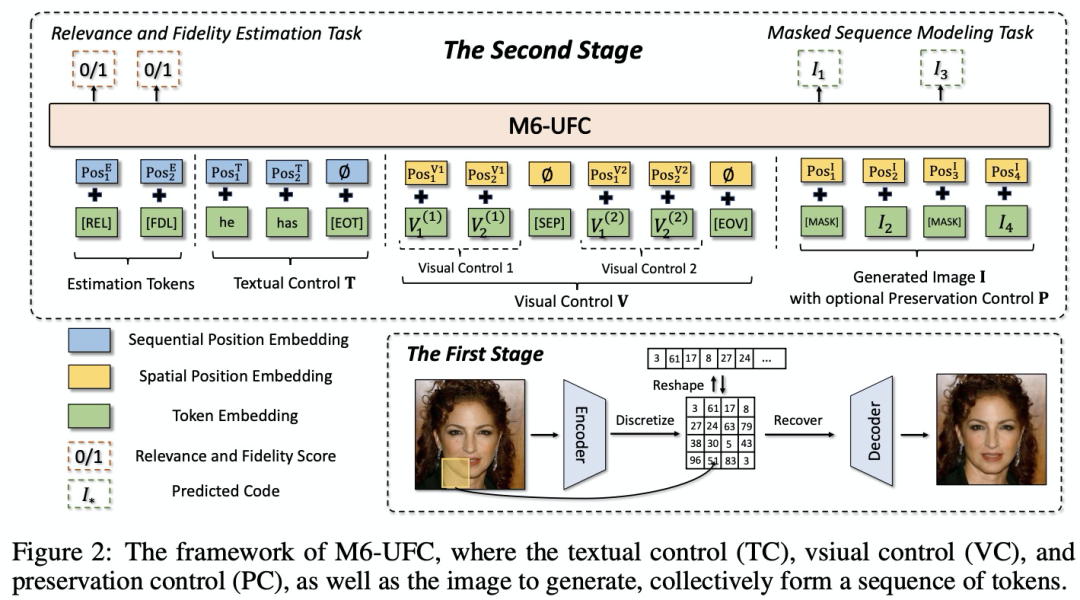
3 训练过程

4 测试结果

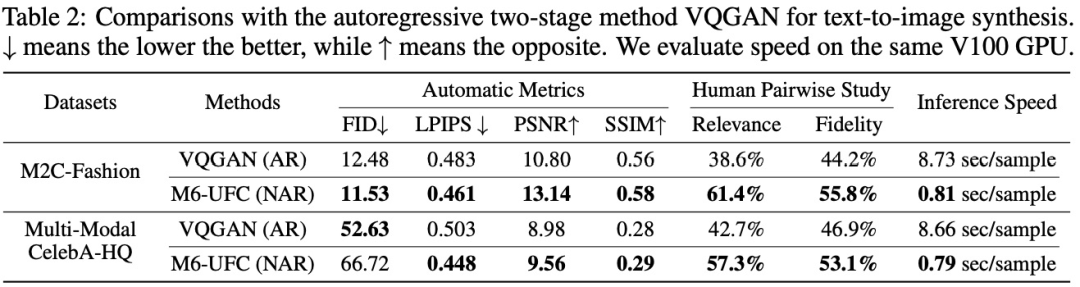

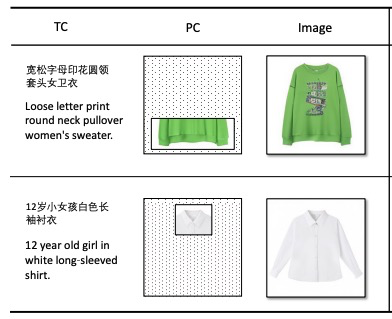

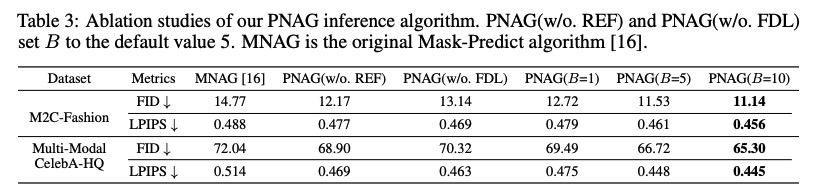
5 前景与展望
关于M6
数据库常见问题排查
登录查看更多
相关内容
Arxiv
11+阅读 · 2021年6月25日



相关VIP内容
相关资讯
相关论文
Arxiv
11+阅读 · 2021年6月25日