CVPR2020 | 参数量减半,北大开源全新高效空域转换模块,还原图像逼真细节
加入极市专业CV交流群,与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度 等名校名企视觉开发者互动交流!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~

很多图像生成任务都需要在空域对输入图像进行移动和重新排列。然而,卷积神经网络难以进行高效的空域转换操作。近日,来自北大和鹏城实验室的研究者们提出了一种全新的空域转换模块 Global-Flow Local-Attention 。这一模块将光流和注意力机制结合起来,通过首先提取源图像与目标图像之间的整体相关性,得到全局的光流图。然后利用光流图,采样局部的特征块以进行局部的注意力操作。
他们在人体姿态转换任务上测试了提出模型的优越性。实验结果证明模型可以对输入图像进行准确高效地空域转换:输出结果图像保持了输入图像中逼真的细节纹理;同时,模型的参数量不足现有主流方法的一半。



Global-Flow Local-Attention模型简介
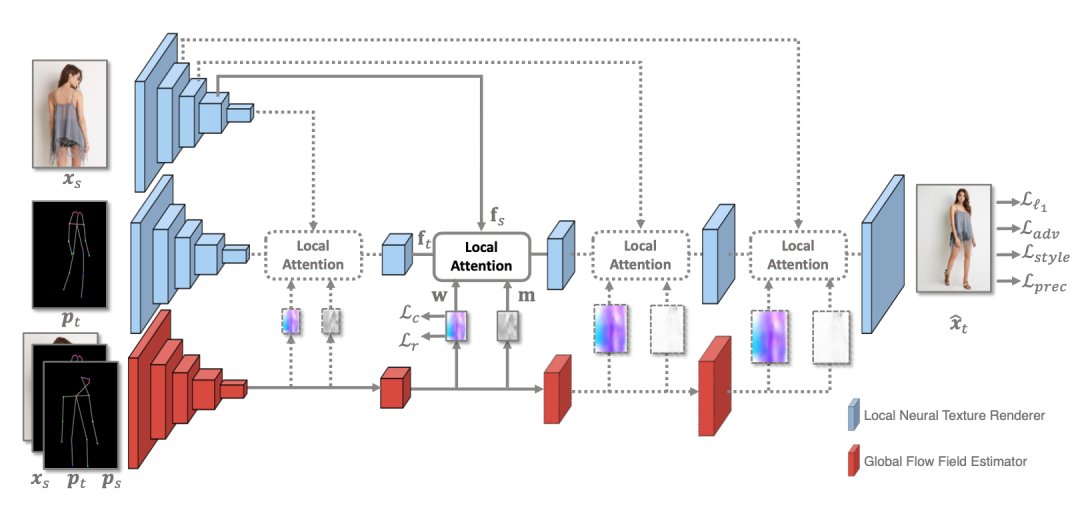
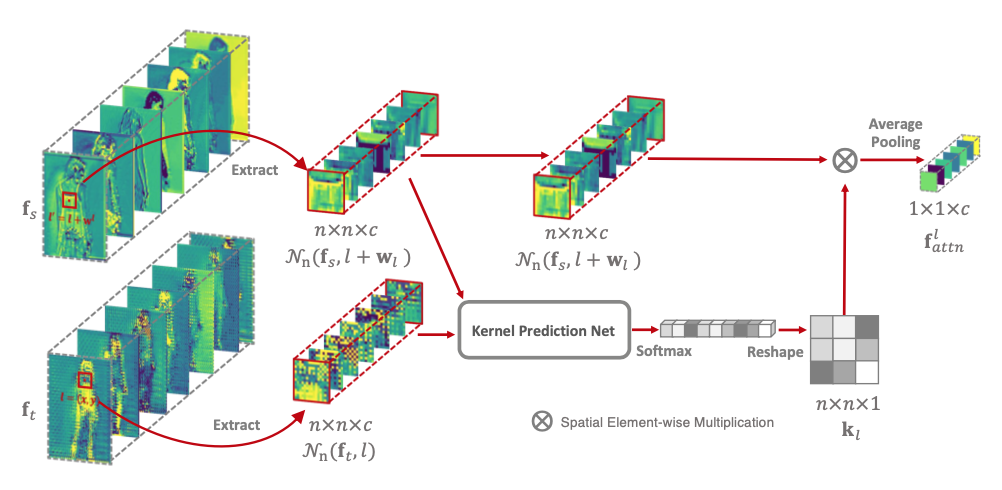
那么算法的实际效果如何呢?
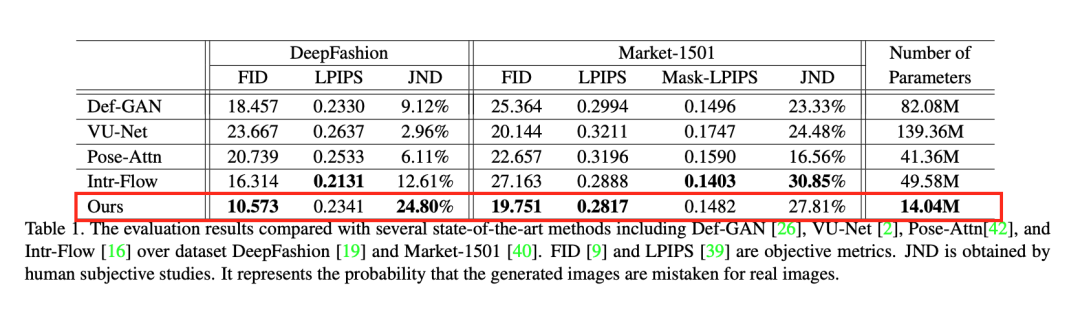
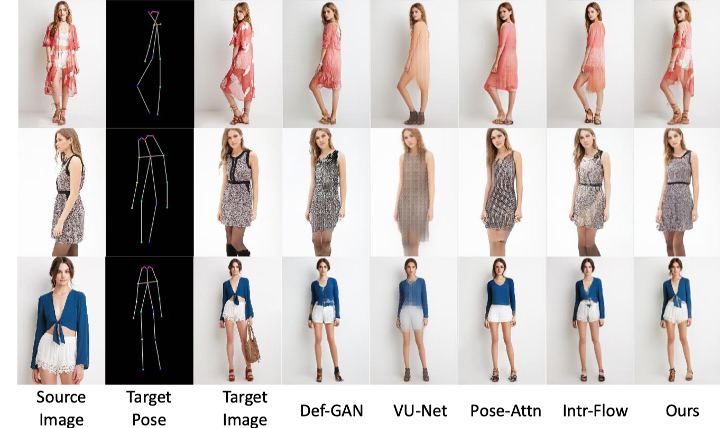
从不同算法的结果图像中可以看出文章所提出的算法不仅能够生成正确的姿势,同时还能够还原出结果图像逼真的纹理信息,例如:衣服上的图案花纹、鞋带的样式等等。
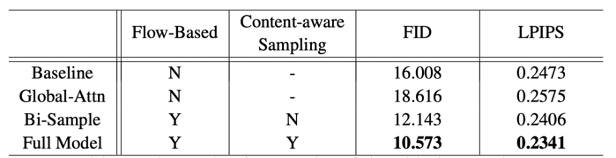
此外,文章还进行了详尽的消融实验来验证假设的正确性。对比的模型包括:不使用任何Attention模块(Baseline);使用传统的Global Attention模块(Global-Attn);使用光流模块,但是采用双线性插值进行采样(Bi-sample)以及完整的模型(Full Model)。可以看出,采用完整Global-Flow Local-Attention模块的模型(Full Model)取得了最好的性能。
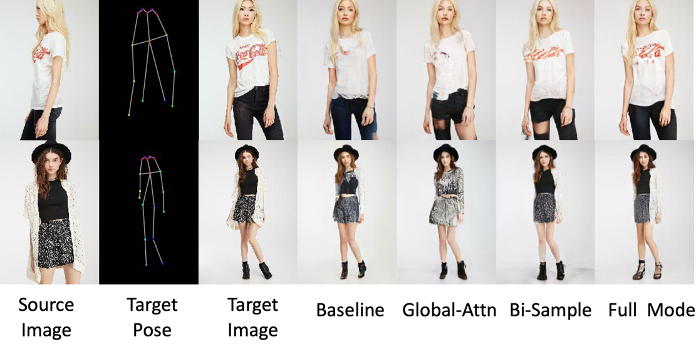
通过分析消融实验的主观结果图像可以进一步地为这一结论寻找可能的解释。Baseline难以恢复细节信息,因为它使用一种先将原始信息抽象,后扩散至局部的方式来生成结果图像。Global-Attn将某一特征与全部的特征计算相似度并采样。这样的采样方式并不符合该任务的需求,因此结果图像无法恢复逼真的细节信息。Bi-sample会因为错误的采样而导致性能下降。Full Model维持了良好的结构和细节信息。
传递门
ICCV 2019 | 港大提出视频显著物体检测算法MGA,大幅提升分割精度
视频预测领域有哪些最新研究进展?不妨看看这几篇顶会论文
AAAI 2020|GlobalTrack:简单又强大!视频长期目标跟踪新基线

添加极市小助手微信(ID : cv-mart),备注:研究方向-姓名-学校/公司-城市(如:AI移动应用-小极-北大-深圳),即可申请加入AI移动应用极市技术交流群,更有每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、行业技术交流,一起来让思想之光照的更远吧~

△长按添加极市小助手

△长按关注极市平台,获取最新CV干货
觉得有用麻烦给个在看啦~




