当人工智能遇上一代宗师叶问......

作者:谭婧,虎嗅专栏作者,《亲爱的数据》公众号创始人,香港浸会大学硕士,N年前高考作文满分得主。曾负责中国节能集团控股企业战略管理工作,许多年管理咨询经验,也曾任人脸识别创业公司合伙人。

俗话说,南拳北腿。
咏春拳作为经典的南派功夫,讲究贴身近击、连消带打与攻守合一。咏春高手的双手知觉灵敏且变化多端,防守时密不透风、滴水不漏,进攻时犹如水银泻地、插缝即入。初看斯文冷静、再看后发先至、以疾如风的速度、爆发出雷霆之力对敌。
那如果叶问对上人工智能里的生成模型呢?
一代宗师叶问先生笑意慈祥,摆出咏春拳的标志性——问路手,
说道:“咏春,叶问。”
见此状后,生成模型生成:___________。(答案见文末)
生成模型:VAE
言归正传,变分自动编码器(Variational AutoEncoders,VAEs)模型是一种流行的生成模型(Generative model),在2013年由Kingma学者提出,能够通过无监督的方式学习复杂的分布。
顶级会议ICLR的一篇论文中提出了一种新的变分自动编码器(简称VAE),以下为该论文的详细解读。

该论文获得了NIPS研讨会的最佳论文奖
随着时间序列和图像等连续数据建模的深入,深度生成模型进展迅速,但要生成语法和语义正确的离散结构化数据(如化学分子和计算机程序)仍然具有挑战性。这篇论文受编译器理论的启发,提出一种新的语法导向的变分自动编码器(SD-VAE)。
语法制导翻译(SDT,syntax-directedtranslation)通过语法和语义检查以及随机惰性属性(stochastic lazyattributes)两个技术点实现对生成模型(解码器)的动态约束。
与前人方法相比,论文所述方法不仅在语法上是正确的,而且在语义上也是合理的。论文作者们评价了该方法在程序的生成和分子的优化上的应用,结果表明,在离散数据的生成模型中引入语法和语义约束效果提升明显。
第一作者:佐治亚理工学院计算机学院,戴涵俊
第二作者:石溪大学计算机科学系,田应涛
第二作者:石溪大学计算机科学系,StevenSkiena
第四作者:蚂蚁金服,人工智能首席工程师,宋乐
论文链接:https://arxiv.org/abs/1802.08786
论文简介

(一)能力
生成模型比较火,主要用于生成图像,或者生成文本。也许你听过今日头条新闻机器人张小明(xiaomingbot)的神勇:2秒钟写稿,拟人化语言,智能配图——其技术原理就是使用的生成模型。也许你还听过将原始的照片或者绘画作品,转化成拥有类似艺术风格的图像。文艺青年的压力突然大起来,写作和绘画都被机器占了先机,你到哪里去说理?
但是讲道理,从上面的例子我们知道,生成模型非常的有用。它可以由可能的数据概率分布估计出来,然后生成像以前的图像,但是和以前不是一模一样,只是有所类似罢了。比如给到模型人脸的图像,它就会给你人脸的图像,而不是生成喵星人的脸或是汪星人的脸。你一定希望使用了生成模型之后,生成的图像稍有变化,如果生成和以前一模一样的脸,那也没有用。
就好比朋友圈的一些自拍狂,同一张图片摆满九宫格,你就告诉我,是想让我来找出每张照片的不同吗,还是让人一口气连看九遍。如今,连生成模型都不屑生成一模一样的新数据。
使用了生成模型,希望把以前的数据特征在模型里被抓住,但是能够产生一些新样品,无论是图像还是文本都是如此。
你需要生成新的东西,就好像人一样,人的智能就是产生新的东西。不仅能把以前的东西学过来,而且能产生一些全新的东西。
(二)缺陷
生成模型有很大能耐,但是也有一个缺陷。
生成模型对自己生成的条件没有办法控制。比如想生成一个序列对应分子的化学表达式,这种离散结构的数据有一个特点,就是不是每一个生成的样本都是合理的,或者语法正确的。
论文中,我们提出三个条件:
和原来的数据集要像,学到原数据集的特征分布;
生成的离散结构具有多样性;
合乎形式语言文法。
下面是论文中模型对离散数据的嵌入空间进行插值得到的生成结果。
简单程序:
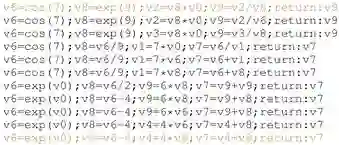
化学分子:

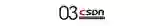
对话论文作者
(一)如何简单地理解论文提出的新方法?
我们利用语法制导翻译这个方法,将离线语义检查变成生成过程的在线指导,重塑了生成模型的输出空间,使它变得更加有意义。如图1所示。
即使增加了表达特征的能力(increased capacity),但是我们的方法与以前的高效学习和推理模型相比并没有增加计算成本。它在化学分子和计算机程序的各种任务上产生了显著的、持续的改进,表现出了其解决现实世界问题的实证价值。
重塑了生成模型的输出空间,使它变得更加有意义。
(图1)
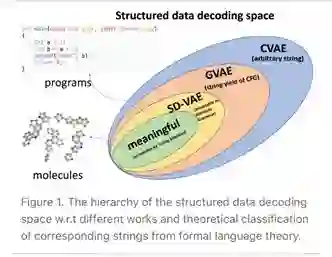
我们的方法将离线属性语法转换为动态生成过程,如图2所示。
(图2、3)
在属性文法(Attribute Grammar)中,有一些继承的和合成的属性,是离线计算的,以确保语义正确性。为了能在生成过程中实时确保语义正确性,我们引入了随机惰性属性,将相应的合成属性转换为生成过程中的约束。惰性链接机制(lazy linking mechanism)设置了属性的实际值,一旦所有其他相关属性都准备好了,就如图3所示。
实验结果表明,我们提高了重建精度和有效的先验精度,这两种方法都是变分自动编码器的重要质量指标,如图4所示。
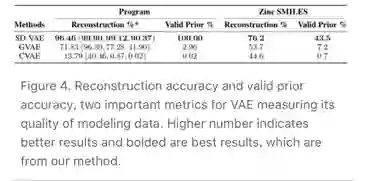
(图4)
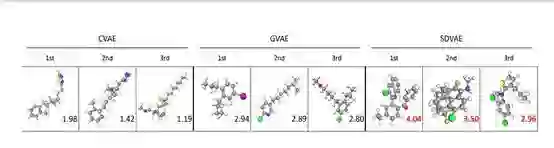
在构建了结构数据的嵌入空间之后,我们使用贝叶斯优化来寻找与新的药物分子。论文所述方法效果良好,如图5所示。
(图5)
图6右边是CVAE、GVAE、SD-VAE三者效果的比较,结果表明,语法导向的变分自动编码器(SD-VAE)效果最好。

(图6)
图7为可视化隐变量空间,表明了通过观察分子,而不教模型任何领域知识(机器学习术语中的“监督”,不给模型任何关于化学分子式的打标签信息),在分子化学式中,找到了一种具有化学意义的分子潜在表征。

(图7)
综上,虽然我们的工作改进效果明显,但是仍然有更多的问题需要解决。例如,我们希望探索形式化的方法,并研究这种形式化在更多样化的数据模式上的应用。
(二)论文中有哪些新内容?
大多的生成模型都满足前两个条件:一是和原来的数据集要像。学到原数据集的特征分布。
二是生成的离散结构具有多样性,都还没有在生成模型里面考虑加上第三个条件——合乎形式语言文法。
因为以前的生成模型比如生成图像,没有一个严格的标准来告诉模型,这个是正确的,这个是错误的。同样的,以前文本生成的内容也比较模糊。没有一个严谨的方法(公式)去测试,以此来决定是否正确。
(三)那么增加正确性这个条件的原因是什么?
我们仍然拿分子式举例,如果是一个不存在、瞎编的分子式,那么在现实中久缺少使用的意义。再举例,生成的代码如果是错误的、无法运行,也是在现实中缺少使用的意义。我们都希望得到的代码是可以运行的,当然生成正确的代码自然增加了难度。
可以理解为正确与否是一个条件,但是模型自然而然的一个发展的目标,就是生成正确的,有意义的。
(四)如何确定正确与否呢?
通常情况下,离散数据——化学表达式和程序代码都有一个编译器(compiler)可以用编译器去检查语法错误。
所以你希望生成的每个都是正确的话,那一定要有多样性。相当于你的生产模型有很多限制在里面。多了一个限制,那就是正确性。生成错误的,使用的意义将降低。
(五)这是本篇论文的突破点吗?
是的,难度系数更高,以前根本做不到。以前没有好的方法来处理,所以一般情况下都会从简单的起步,从而生成错误的起步。
实际上,加入想生成的数学公式和物理公式,当然是正确的公式,一定会更难。再比如,长的程序代码回避短的程序代码的生成,更有难度。
论文提出的方法解决了正确性,这当然不是把所有的问题都解决了。离散的序列,包括一段文字,第一有语法的正确性这一标准,第二有是不是内容和逻辑这是第二个标准。在计算机眼中,一个程序也是一个字符串,化学表达式也是字符串。
例如,你要书写一篇篇幅很长的深度新闻报道,你肯定希望尽量保证句子语法正确。但是如果不用这种方法,会生成很多语法的病句,上下文逻辑关系也有可能不正确。
新闻报道就是离散的序列,无论是英文还是中文。一个句子的基本单位是字,句子在人的眼中是句子,在计算机的眼中是字符串。
(六)生成模型用在汉字上是什么样的情况?
会生成一些不是汉字的图片,可能看起来像汉字的字,但其实根本不是汉字。可能生成图片这个不是个很好的例子,因为图片没有形式语言文法,也就没有一个客观指标判别正确错误(此处有一个尴尬的微笑)。
(七)伴随生成模型的不断强大,计算机程序真的会自动生成生动有趣的新闻报道吗?
现在的技术还达不到,一些人工智能公司的模型也是写好了对应的模板,把新闻数据对应填进去,从而生成不同写作风格的文字。从技术角度讲,生成的文字语法正确,上下文逻辑正确是很有难度的。
(八)为什么我们这里不用GAN而用VAE?
因为GAN需要将梯度从判别器传回生成器,而如果生成器产生的output是不可导的(比如这里的离散结构),那么事情就比较麻烦。
VAE答叶问
补充一个心理活动:感谢论文作者的讲解,本文作者我觉得可能还有一段时间不会失业,心里松了一口气。
文末,我们复习下文章开头提出的问题:
叶问先生说道:“咏春,叶问。”
见此状后,生成模型生成三个参考答案:
答案一:咏鹅,骆宾王。
答案二:咏柳,贺知章。
答案三:咏烛,李世民。



这三个答案都“完美”地满足了前面所提的三个条件:和原来的数据集要像,学到原数据集的特征分布;生成的离散结构具有多样性;合乎形式语言文法。

One More Thing
一个活生生的例子(虽然论文中没有提及),下面用论文的方法搞了一个小应用:同步执行生成这是一个以神经为基础的五音节汉语四行诗词,忠实地遵循偶数诗句中的押韵和严格的声调交替模式——它是基于我们在ICLR2018的论文中提出的想法。
链接:https://alantian.github.io/kanshi-web/
附:第35届机器学习技术国际会议(ICML)署名论文数量排名并列第三的作者宋乐,即为本论文的作者之一。

声明:本文为作者投稿,版权归作者个人所有。