关于深度多任务学习的 3 点经验
原文 / 机器之心
在过去的一年里,我和我的团队一直致力于为 Taboola feed 提供个性化用户体验。我们运用多任务学习(Multi-Task Learning,MTL),在相同的输入特征集上预测多个关键性能指标(Key Performance Indicator,KPI),然后使用 TensorFlow 实现深度学习模型。回想最初的时候,我们感觉(上手)MTL 比现在要困难很多,所以我希望在这里分享一些经验总结。
现在已经有很多关于利用深度学习模型实现 MTL 的文章。在本文中,我准备分享一些利用神经网络实现 MTL 时需要考虑的具体问题,同时也会展示一些基于 TensorFlow 的简单解决方案。
共享即关怀
我们准备从参数硬共享(hard parameter sharing)的基础方法开始。硬共享表示我们使用一个共享的子网络,下接各个任务特定的子网络。
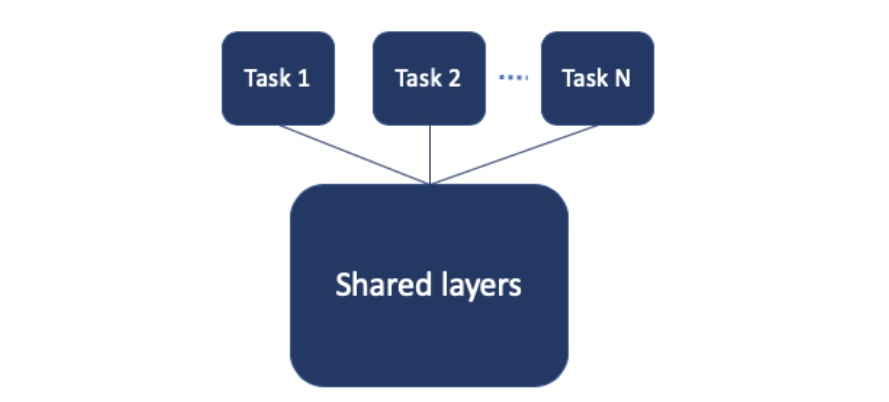
在 TensorFlow 中,实现这样一个模型的简单方法是使用带有 multi_head 的 Estimator。这个模型和其他神经网络架构相比没什么不同,所以你可以自己想想,有哪些可能出错的地方?
第一点:整合损失
我们的 MTL 模型所遇到的第一个挑战是为多个任务定义一个损失函数。既然每个任务都有一个定义良好的损失函数,那么多任务就会有多个损失。
我们尝试的第一个方法是将不同损失简单相加。很快我们就发现,虽然某一个任务会收敛得到不错的结果,其他的却表现很差。进一步研究后,可以很容易地明白原因:不同任务损失的尺度差异非常大,导致整体损失被某一个任务所主导,最终导致其他任务的损失无法影响网络共享层的学习过程。
一个简单的解决方案是,将损失简单相加替换为加权和,以使所有任务损失的尺度接近。但是,这引入了另一个可能需要不时进行调节的超参数。
幸运的是,我们发现了一篇非常棒的论文《Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics》,提出引入不确定性来确定 MTL 中损失的权重:在每个任务的损失函数中学习另一个噪声参数(noise parameter)。此方法可以接受多任务(可以是回归和分类),并统一所有损失的尺度。这样,我们就能像一开始那样,直接相加得到总损失了。
与损失加权求和相比,该方法不仅得到了更好的结果,而且还可以不再理会额外的权重超参数。论文作者提供的 Keras 实现参见:https://github.com/yaringal/multi-task-learning-example/blob/master/multi-task-learning-example.ipynb。
第二点:调节学习速率
调节神经网络有一个通用约定:学习速率是最重要的超参数之一。所以我们尝试调节学习速率。我们发现,对于某一个任务 A 而言,存在一个特别适合的学习速率,而对于另一个任务 B,则有不同的适合学习速率。如果选择较高的学习速率,可能在某个任务上出现神经元死亡(由于大的负梯度,导致 Relu 函数永久关闭,即 dying ReLU),而使用较低的学习速率,则会导致其他任务收敛缓慢。应该怎么做呢?我们可以在各个「头部」(见上图,即各任务的子网络)分别调节各自的学习速率,而在共享网络部分,使用另一个学习速率。
虽然听上去很复杂,但其实非常简单。通常,在利用 TensorFlow 训练神经网络时,使用的是:
optimizer = tf.train.AdamOptimizer(learning_rate).minimize(loss)
AdamOptimizer 定义如何应用梯度,而 minimize 则完成具体的计算和应用。我们可以将 minimize 替换为我们自己的实现方案,在应用梯度时,为计算图中的各变量使用各自适合的学习速率。
all_variables = shared_vars + a_vars + b_vars
all_gradients = tf.gradients(loss, all_variables)
shared_subnet_gradients = all_gradients[:len(shared_vars)]
a_gradients = all_gradients[len(shared_vars):len(shared_vars + a_vars)]
b_gradients = all_gradients[len(shared_vars + a_vars):]
shared_subnet_optimizer = tf.train.AdamOptimizer(shared_learning_rate)
a_optimizer = tf.train.AdamOptimizer(a_learning_rate)
b_optimizer = tf.train.AdamOptimizer(b_learning_rate)
train_shared_op = shared_subnet_optimizer.apply_gradients(zip(shared_subnet_gradients, shared_vars))
train_a_op = a_optimizer.apply_gradients(zip(a_gradients, a_vars))
train_b_op = b_optimizer.apply_gradients(zip(b_gradients, b_vars))
train_op = tf.group(train_shared_op, train_a_op, train_b_op)
友情提醒:这个技巧其实在单任务网络中也很实用。
第三点:将估计作为特征
当我们完成了第一阶段的工作,为预测多任务创建好神经网络后,我们可能希望将某一个任务得到的估计(estimate)作为另一个任务的特征。在前向传递(forward-pass)中,这非常简单。估计是一个张量,可以像任意一个神经层的输出一样进行传递。但在反向传播中呢?
假设将任务 A 的估计作为特征输入给 B,我们可能并不希望将梯度从任务 B 传回任务 A,因为我们已经有了任务 A 的标签。对此不用担心,TensorFlow 的 API 所提供的 tf.stop_gradient 会有所帮助。在计算梯度时,它允许你传入一个希望作为常数的张量列表,这正是我们所需要的。
all_gradients = tf.gradients(loss, all_variables, stop_gradients=stop_tensors)
和上面一样,这个方法对 MTL 网络很有用,但不止如此。该技术可用在任何你希望利用 TensorFlow 计算某个值并将其作为常数的场景。例如,在训练生成对抗网络(Generative Adversarial Network,GAN)时,你不希望将对抗示例反向传播到生成过程中。
下一步
我们的模型已经上线运行,Taboola feed 也已经是个性化的了。但是,还有很多可以提升改进的空间,以及许多有趣的结构可以探索。在我们的应用场景中,预测多任务也意味着基于多个 KPI 完成决策。这可能比基于单个 KPI 的更复杂……不过这就是另一个全新的问题了。
推荐阅读
15亿参数!史上最强通用NLP模型诞生:狂揽7大数据集最佳纪录


