超级简单 :两个月上手AI的学习经验(附学习资源)
当今时代,每个人都很忙。生活和职场中有太多的事情等着我们去做。 而更重要的是,一个叫AI(Artificial Intelligence: 人工智能)的东西正在展翅, 你会发现你所拥有的技能在未来两年里会变得越来越过时。
当我关掉我的初创公司Zeading时,我徒然惊醒,感觉到自己似乎忽略了一个非常重要的东西:
一个全栈开发者所拥有的能力已经不足以赶上时代的步伐。在未来的两年里,不具备AI不能被称之为全栈。
是时候采取行动了。唯一的方式就是,我得把我的那些开发人员的技能、产品经理的方法论以及企业家的经营哲学统统升级到数据导向的才行。
风险投资家、AI和金融科技的思想领导者Spiros Margaris对我说过一段非常具有说服力的话:
“如果创业者和企业们把AI和机器学习当作一种竞争优势的话是不够的。AI不是一种优势,而是一件装备。你听说过哪个企业把电力当作一种竞争优势吗?”
建立我的第一个神经元网络
大多数建议是注册参加吴恩达(Andrew Ng)在Cousera开设的课程。 它确实是一个很好的入门课程,但我发现我常常看着看着就睡着了。因为我个人更喜欢在实践中学习,所以有时候不能在观看视频时保持长时间的注意力集中。
我并没有走捷径直接跳到神经元网络那一章,而是尝试理解熟悉这个领域,这样我才能学会使用这门“语言”。
第一不是学习,而是理解。
基于我JavaScript和Nodejs的背景,我并不想即刻转换编程方式。于是,我找了一个叫做nn的神经网络模块,并用它建立了一个 有虚拟变量的与门(AND gate)模型。 受教程启发,我把问题定义为:对于任意三个输入项X,Y,Z, 输出项为X AND Y。
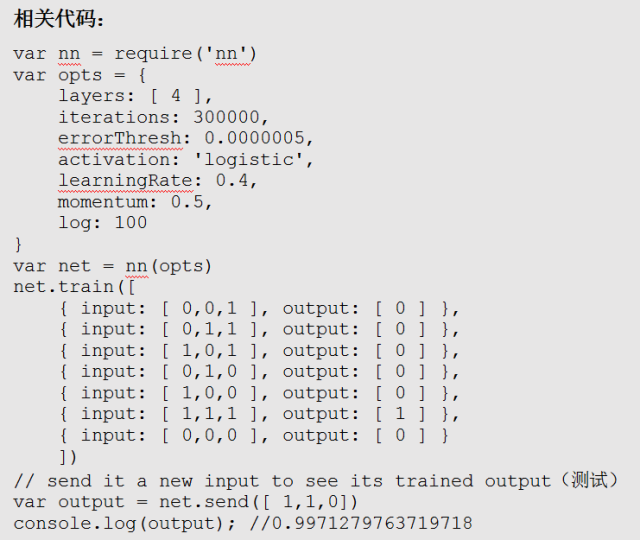
满满的成就感!在我个人看来,这就是是建立信心最重要的一步。 当输出闪烁为0.9971时,我意识到我的神经元网络学会了如何做与运算 (AND operation),并且能够自动忽略多余的输入项。
机器学习的最基本的要领就是:给程序输入一组原始数据作为学习数据(learning data),程序通过对原始数据的观察获得对类似新数据在一定程度上的认知能力,并且在学习过程中通过优化算法调整其内部的参数(parameter),以此逐步降低辨别新数据时的错误率。
其中最常用的一种优化算法 ,正如我后来所知道的, 为梯度下降法(gradient descent)。
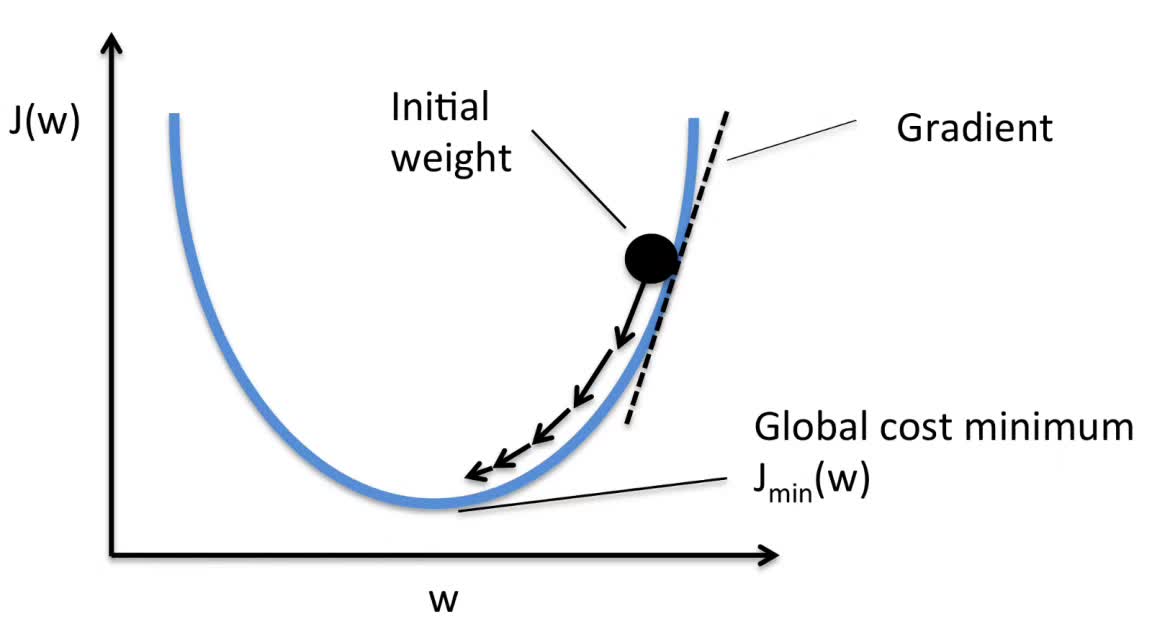
梯度下降 (图片为作者所选取,出自
Sebastian Raschka:https://sebastianraschka.com/faq/docs/closed-form-vs-gd.html)
用AI填充我的大脑
当我作成我的第一个AI程序之后,我无比的自信。作为开发人员,我想知道我可以用机器学习再做些什么事情。
我解决了几个监督学习问题,比如回归和分类。
我使用非常有限的数据和多元线性回归模型尝试预测哪只支队伍会赢得IPL棒球比赛。(预测结果很差,但这项任务本身很酷。)
我尝试了在谷歌云端上的关于机器学习的各类展示,想了解如今AI的一些用途。(谷歌把它作为SAAS云服务这个主意很不错。)
我偶然发现了AI Playbook。 它是风投公司Andreessen-Horowitz提供的AI方面的资源。 对于开发人员和企业家来说,它确实是最好的上手资料之一。
我开始在Youtube上观看Siraj Rawal的频道,它以深度学习(Deep Learning)为重点。
我阅读了Hacker Noon论坛上关于Not Hotdog (识别热狗) App在硅谷的开发过程。一个非常容易实现的深度学习实例。
我读了特斯拉AI部门的总监,Andrej Karpathy的博客。一开始我很难理解所有的内容,看的非常头痛。但是,当我自己在学习AI的历程中尝试了很多东西之后,我渐渐能理解他博客上所写的这些概念了。
我勇敢地开始逐字逐行的码一些AI教程上的练习,并且运行我的代码,来试图训练出这些模型。但大多数时候,结果都不是很理想。因为这些模型需要很多的运算资源,而我的GPU太差了。
我所使用的工具逐渐从Javascript变成了Python。此外,我还在我的电脑上装了Tensorflow。
整个学习过程比较被动,我需要把这些知识在大脑中建立索引,这样我就可以在面临一个真实消费者问题的时候懂得如何运用它们。
就像史蒂夫.乔布斯(Steve Jobs)所说的那样:
暮然回首,路上的点点滴滴才会相链。
搭上聊天机器人的列车
作为电影“她”的脑残粉,我必须建立一个聊天机器人。我接受了这个挑战,并花了不到两个小时用Tensorflow作了一个。 我在几天前发表的一篇文章中记录了这个过程以及聊天机器人的商业用途。
非常幸运的是,这篇文章火了,并且被TechInAsia,CodeMentor以及KDNuggets等知名网站转载。对于我来说,这是一个伟大的时刻,因为我才刚刚加入到科技博客中。 我甚至可以把这篇文章当作我学习AI历程上的一个丰碑。
它让我在Twitter和LinkedIn上收获了很多朋友。 我可以和他们一起长期并深入地讨论AI的发展和用途,甚至当我陷入困境时,可以在上面找到帮助。 我得到了几个咨询项目的提议,而让我非常自豪的是,很多年轻的开发人员和AI初学者们开始问我如何开始学习AI。 这也是我会发表本篇文章的原因。我希望更多的人可以从我的历程中找到他们自己的路。
开始,是每段历程中最富有挑战性的一步。
盐和胡椒
放弃Javascript对于我来说是非常艰难的一步。我几乎是一夜之间转用Python,并学会如何用它来写代码。当我在i7处理器上没法训练我的模型,或者是训练了几个小时后结果却是五五开时,我真的难受的不行。学习AI和学习Web应用框架还是有区别的。
这是一种技巧,需要在计算的微观层次上了解正在发生的事情,并且能够找出对输出影响最大的那个点 —— 是在你的代码中,还是在你的数据里。
AI不只是一个简单的定义,而是一个雨伞术语(Umbrella term),包含了从简单的回归问题到有朝一日能杀死我们的杀手机器人。就像你所踏入的每个行业一样,你希望从AI中找到属于你的那一部分,比如计算机视觉,自然语言处理,甚至是统治世界。
在一次与(AI、金融科技和加密技术领军企业)Atlantis Capital 公司的Gaurav Sharma交谈的过程中,他向我倾诉:
“在人工智能的时代, “聪明”的定义完全不同。我们需要人们表现出更高层次的批判性、创造性和思考能力,以及需要高情感投入的工作。”
你需要痴迷于计算机是如何具备自学习能力的这个问题。耐性和好奇心是你能够坚持下去的基本属性。
这是一个漫长的旅程,很累、很伤脑筋、特别是很花时间。
幸运的是,就像所有的旅程一样,这一个也将从第一步开始。
原文标题:
How I started with learning AI in the last 2 months
Beginning with the most important skill of the 21st century
原文地址:
https://hackernoon.com/how-i-started-with-learning-ai-in-the-last-2-months-251d19b23597
作者:Shival Gupta;翻译:王瑞玺;编辑:王璇;校对:冯羽;
本文转自:数据派THU 公众号;

END
优秀人才不缺工作机会,只缺适合自己的好机会。但是他们往往没有精力从海量机会中找到最适合的那个。100offer 会对平台上的人才和企业进行严格筛选,让「最好的人才」和「最好的公司」相遇。
扫描下方二维码或点击“ 阅读原文 ”,注册 100offer,谈谈你对下一份工作的期待。一周内,收到 5-10 个满足你要求的好机会!

关联阅读
原创系列文章:
数据运营 关联文章阅读:
数据分析、数据产品 关联文章阅读:





