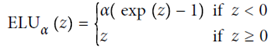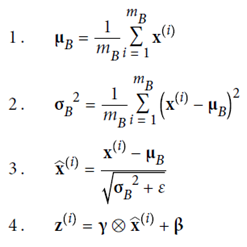来源丨机械工业出版社
《机器学习实战:基于Scikit-Learn、Keras和TensorFlow》
机器学习“四大名著”中最适合入门的“蜥蜴书”——《机器学习实战》新版来了!本文节选了该书第11章第1节中的内容,解析了反向传播算法中的梯度消失与梯度爆炸问题。另外,参与 文末粉丝福利活动,还有机会获赠全书 !>>加入极市CV技术交流群,走在计算机视觉的最前沿
1 梯度消失与梯度爆炸
正如我们在第10章中讨论的那样,反向传播算法的工作原理是从输出层到输入层,并在此过程中传播误差梯度。一旦算法计算出代价函数相对于网络中每个参数的梯度,就可以使用这些梯度以梯度下降步骤来更新每个参数。
不幸的是,随着算法向下传播到较低层,梯度通常会越来越小。结果梯度下降更新使较低层的连接权重保持不变,训练不能收敛到一个好的最优解。我们称其为梯度消失问题。 在某些情况下,可能会出现相反的情况:梯度可能会越来越大,各层需要更新很大的权重直到算法发散为止。这是梯度爆炸问题 ,它出现在递归神经网络中(请参阅第15章)。更笼统地说,深度神经网络很受梯度不稳定的影响。不同的层可能以不同的速度学习。
这种不幸的行为是很久以前就凭经验观察到了,这也是深度神经网络在2000年代初期被大量抛弃的原因之一。目前尚不清楚是什么原因导致在训练DNN时使梯度如此不稳定,但是Xavier Glorot和Yoshua Bengio在2010年的一篇论文中阐明了一些观点1。作者发现了一些疑点,包括流行的逻辑sigmoid激活函数和当时最流行的权重初始化技术(即平均值为0且标准差为1的正态分布)。简而言之,它们表明使用此激活函数和此初始化方案,每层输出的方差远大于其输入的方差。随着网络的延伸,方差在每一层之后都会增加,直到激活函数在顶层达到饱和为止。实际上,由于逻辑函数的平均值为0.5,而不是0(双曲线正切函数的平均值为0,在深度网络中的行为比逻辑函数稍微好一些),因此饱和度实际上变得更差。
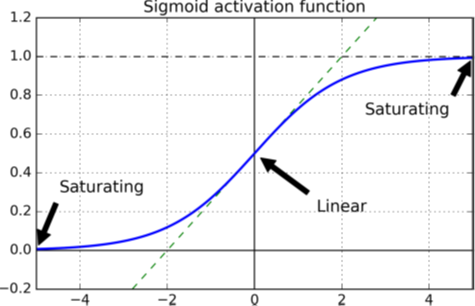
查看逻辑激活函数(参见图11-1),你可以看到,当输入变大(负数或正数)时,该函数会以0或1饱和,并且导数非常接近0。因此反向传播开始时它几乎没有梯度可以通过网络传播回去。当反向传播通过顶层向下传播时,几乎没有什么梯度不断被稀释,因此对于底层来说,实际上什么也没有留下。
图11-1 逻辑激活函数的饱和
1.1 Glorot 和He初始化 Glorot和Bengio在它们的论文中提出了一种能显著缓解不稳定梯度问题的方法。它们指出,我们需要信号在两个方向上正确流动:进行预测时,信号为正向;在反向传播梯度时,信号为反向。我们既不希望信号消失,也不希望它爆炸并饱和。为了使信号正确流动,作者认为,我们需要每层输出的方差等于其输入的方差2,并且我们需要在反方向时流过某层之前和之后的梯度具有相同的方差(如果你对数学细节感兴趣,请查看本论文)。除非该层具有相等数量的输入和神经元(这些数字称为该层的扇入和扇出),否则实际上不可能同时保证两者,但是Glorot和Bengio提出了一个很好的折中方案,在实践中证明很好地发挥作用:必须按照公式11-1中所述的随机初始化每层的连接权重,其中fan avg = (fan in + fan out ) / 2。这种初始化策略称为Xavier初始化或者Glorot初始化,以论文的第一作者命名。
公式11-1. Glorot初始化(使用逻辑激活函数时)
正态分布,均值为 0,方差为
或
和+
之间的均匀分布,其中
如果在公式11-1中你用fan
in
替换fan
avg
,则会得到Yann LeCun在1990年代提出的初始化策略。他称其为LeCun初始化。Genevieve Orr和Klaus-Robert Müller甚至在其1998年出版的《Neural Networks: Tricks of theTrade》(Springer)一书中进行了推荐。当fanin= fanout时,LeCun初始化等效于Glorot初始化。研究人员花了十多年的时间才意识到这一技巧的重要性。使用Glorot初始化可以大大加快训练速度,这是导致深度学习成功的诀窍之一。
一些论文为不同的激活函数提供了类似的策略3。这些策略的差异仅在于方差的大小以及它们使用的是fanavg还是fanin,如表11-1所示(对于均匀分布,只需计算r = )。ReLU激活函数的初始化策略(及其变体,包括ELU激活函数)有时简称为He初始化。本章稍后将解释SELU激活函数。它应该与LeCun初始化一起使用(最好与正态分布一起使用,如我们所见)。
None, tanh, logistic, softmax
默认情况下,Keras使用具有均匀分布的Glorot初始化。创建层时,可以通过设置
kernel_initializer="he_uniform"
kernel_initializer="he_normal"
keras.layers.Dense(10, activation="relu",kernel_initializer="he_normal")
如果你要使用均匀分布但基于fanavg而不是fanin进行He初始化,则可以使用VarianceScaling初始化,如下所示:
he_avg_init = keras.initializers.VarianceScaling(scale=2.,mode='fan_avg',distribution='uniform')keras.layers.Dense(10, activation="sigmoid",kernel_initializer=he_avg_init)
1.2 非饱和激活函数
Glorot和Bengio在2010年的论文中提出的一项见解是,梯度不稳定的问题部分是由于激活函数选择不当所致。在此之前,大多数人都认为,如果大自然母亲选择在生物神经元中使用类似sigmoid的激活函数,那么它们必定是一个好选择。但是事实证明,其他激活函数在深度神经网络中的表现要好得多,尤其是ReLU激活函数,这主要是因为它对正值不饱和(并且计算速度很快)。
不幸的是,ReLU激活函数并不完美。它有一个被称为“濒死的ReLUs”的问题:在训练过程中,某些神经元实际上“死亡”了,这意味着它们停止输出除0以外的任何值。在某些情况下,你可能会发现网络中一半的神经元都死了,特别是如果你使用较大的学习率。当神经元的权重进行调整时,其输入的加权和对于训练集中的所有实例均为负数,神经元会死亡。发生这种情况时,它只会继续输出零,梯度下降不会再影响它,因为ReLU函数的输入为负时其梯度为零4。
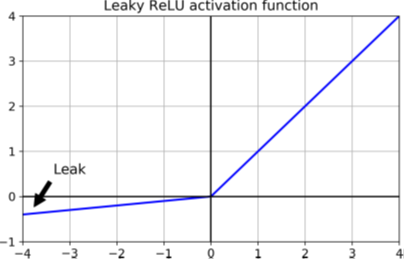
要解决此问题,你可能需要使用ReLU函数的变体,例如leaky ReLU。该函数定义为LeakyReLUα(z) =max(αz, z)(见图11-2)。超参数α定义函数“泄漏”的程度:它是z < 0时函数的斜率,通常设置为0.01。这个小的斜率确保了leaky ReLUs永远不会死亡。它们可能会陷入长时间的昏迷,但是它们有机会最后醒来。2015年的一篇论文比较了ReLU激活函数的几种变体5,其结论之一是泄漏的变体要好于严格的ReLU激活函数。实际上,设置α = 0.2(大泄漏)似乎比α = 0.01(小泄漏)会产生更好的性能。本论文还对随机的leaky ReLU(RReLU)进行了评估,在训练过程中在给定范围内随机选择α,在测试过程中将其固定为平均值。RReLU的表现也相当不错,似乎可以充当正则化函数(减少了过度拟合训练集的风险)。最后,本文评估了参数化leaky ReLU(PReLU),其中α可以在训练期间学习(不是超参数,它像其他任何参数一样,可以通过反向传播进行修改)。据报道,PReLU在大型图像数据集上的性能明显优于ReLU,但是在较小的数据集上,它存在过度拟合训练集的风险。
图11-2. Leaky ReLU: 与ReLU类似,对负值有一个小斜率
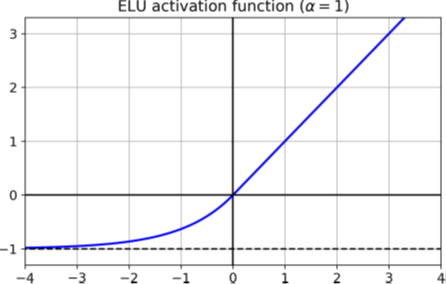
最后但并非最不重要的一点是,Djork-Arné Clevert等人在2015年发表的论文提出了一种新的激活函数6,称为指数线性单位(exponential linear unit,ELU),该函数在作者的实验中胜过所有ReLU变体:减少训练时间,神经网络在测试集上表现更好。图11-3绘制了函数图,公式11-2给出了其定义。
ELU激活函数与ReLU函数非常相似,但有一些主要区别:
当z < 0时,它取负值,这使该单元的平均输出接近于0,有助于缓解梯度消失的问题。超参数α定义当z为较大负数时,ELU函数逼近的值。通常将其设置为1,但是你可以像其他任何超参数一样对其进行调整。
对于z < 0,它具有非零梯度,从而避免了神经元死亡的问题。
如果α等于1,则该函数在所有位置(包括z = 0左右)都是平滑的,这有助于加速梯度下降,因为它在z = 0的左右两侧弹跳不大。
ELU激活函数的主要缺点是它的计算比ReLU函数及其变体要慢(由于使用了指数函数)。它在训练过程中更快的收敛速度弥补了这种缓慢的计算,但是在测试时,ELU网络将比ReLU网络慢。
然后,Günter Klambauer等人在2017年发表的论文提出了可扩展的ELU(Scaled ELU)激活函数7:顾名思义,它是ELU激活函数的可扩展变体。作者表明,如果你构建一个仅由密集层堆叠组成的神经网络,并且如果所有隐藏层都使用SELU激活函数,则该网络是自归一化的:每层的输出倾向于在训练过程中保留平均值0和标准偏差为1,从而解决了梯度消失/爆炸的问题。结果,SELU激活函数通常大大优于这些神经网络(尤其是深层神经网络)的其他激活函数。但是,有一些产生自归一化的条件(有关数学证明,请参见论文):
输入特征必须是标准化的(平均为0和标准偏差为1)。
每个隐藏层的权重必须使用LeCun正态初始化。在Keras中,这意味着设置
kernel_initializer="lecun_normal"
网络的架构必须是顺序的。不幸的是,如果你尝试在非顺序架构(例如循环网络)中使用SELU(请参见第15章15)或具有跳过连接的网络(即在Wide & Deep网络中跳过层的连接),将无法保证自归一化,因此SELU不一定会胜过其他激活函数。
本论文仅在所有层都是密集层的情况下保证自归一化,但一些研究人员指出SELU激活函数也可以改善卷积神经网络的性能(请参阅第14章)。
那么,你应该对深度神经网络的隐藏层使用哪个激活函数呢?尽管你的目标会有所不同,但通常SELU > ELU > leaky ReLU(及其变体)> ReLU> tanh > logistic。如果网络的架构不能自归一化,那么ELU的性能可能会优于SELU(因为SELU在z = 0时不平滑)。如果你非常关心运行时延迟,那么你可能更喜欢leaky ReLU。如果你不想调整其他超参数,则可以使用Keras使用的默认α值(例如,leaky ReLU为0.3)。如果你有空闲时间和计算能力,则可以使用交叉验证来评估其他激活函数,例如,如果网络过度拟合,则为RReLU;如果你的训练集很大,则为PReLU。就是说,由于ReLU是迄今为止最常用的激活函数,因此许多库和硬件加速器都提供了ReLU特定的优化。因此,如果你将速度放在首位,那么ReLU可能仍然是最佳选择。
要使用leaky ReLU激活函数,创建一个LeakyReLU层,并将其添加到你想要应用它的层之后的模型中:
model = keras.models.Sequential([ [...] keras.layers.Dense(10,kernel_initializer="he_normal"), keras.layers.LeakyReLU(alpha=0.2), [...] ])
对于PReLU,将LeakyRelu(alpha=0.2)替换为PReLU ()。Keras当前没有RReLU的官方实现,但是你可以轻松地实现自己的(要了解如何实现,请参阅第12章末尾的练习)。
kernel_initializer="lecun_nor mal":layer = keras.layers.Dense(10, activation="selu",kernel_initializer="lecun_normal")
1.3 批量归一化
尽管将He初始化与ELU(或ReLU的任何变体)一起使用可以显著减少在训练开始时的梯度消失/爆炸问题的危险,但这并不能保证它们在训练期间不会再出现。
在2015年的一篇论文中8,Sergey Ioffe和Christian Szegedy提出了一种称为批量归一化(BN)的技术来解决这些问题。该技术包括在模型中的每个隐藏层的激活函数之前或之后添加一个操作。该操作对每个输入零中心并归一化,然后每层使用两个新的参数向量缩放和偏移其结果:一个用于缩放,另一个用于偏移。换句话说,该操作可以使模型学习各层输入的最佳缩放和均值。在许多情况下,如果你将BN层添加为神经网络的第一层,则无须归一化训练集(例如,使用StandardScaler);BN层会为你完成此操作(因为它一次只能查看一个批次,它还可以重新缩放和偏移每个输入特征)。
为了使输入零中心并归一化,该算法需要估计每个输入的均值和标准差。通过评估当前小批次上的输入的平均值和标准偏差(因此称为“批量归一化”)来做到这一点。公式11-3逐步总结了整个操作。
μB是输入均值的向量,在整个小批量B上评估(每个输入包含一个均值)。
σB是输入标准偏差的向量,也在整个小批量中进行评估(每个输入包含一个标准偏差)。
γ是该层的输出缩放参数向量(每个输入包含一个缩放参数)。
⊗表示逐元素乘法(每个输入乘以其相应的输出缩放参数)。
β是层的输出移动(偏移)参数矢量(每个输入包含一个偏移参数)。每个输入都通过其相应的移动参数进行偏移。
ε是一个很小的数字以避免被零除(通常为10-5)。这称为平滑项。
z(i)是BN操作的输出。它是输入的缩放和偏移的输出。
因此在训练期间,BN会归一化其输入,然后重新缩放并偏移它们。好!那在测试期间呢?这不那么简单。确实,我们可能需要对单个实例而不是成批次的实例做出预测:在这种情况下,我们无法计算每个输入的均值和标准差。而且,即使我们确实有一批次实例,它也可能太小,或者这些实例可能不是独立的和相同分布的,因此在这批实例上计算统计信息将是不可靠的。一种解决方法是等到训练结束,然后通过神经网络运行整个训练集,计算BN层每个输入的均值和标准差。然后,在进行预测时,可以使用这些“最终”的输入平均值和标准偏差,而不是一个批次的输入平均值和标准偏差。然而,大多数批量归一化的实现都是通过使用该层输入的平均值和标准偏差的移动平均值来估计训练期间的最终统计信息。这是Keras在使用BatchNormalization层时自动执行的操作。综上所述,在每个批归一化层中学习了四个参数向量:通过常规反向传播学习γ(输出缩放向量)和β(输出偏移向量),和使用指数移动平均值估计的μ(最终的输入均值向量)和σ(最终输入标准差向量)。请注意,μ和σ是在训练期间估算的,但仅在训练后使用(以替换方程式11-3中的批量输入平均值和标准偏差)。
Ioffe和Szegedy证明,批量归一化极大地改善了它们试验过的所有深度神经网络,从而极大地提高了ImageNet分类任务的性能(ImageNet是将图像分类为许多类的大型图像数据库,通常用于评估计算机视觉系统)。消失梯度的问题已大大减少,以至于它们可以使用饱和的激活函数,例如tanh甚至逻辑激活函数。网络对权重初始化也不太敏感。作者可以使用更大的学习率,大大加快了学习过程。它们特别指出:
批量归一化应用于最先进的图像分类模型,以少14倍的训练步骤即可达到相同的精度,在很大程度上击败了原始模型。[…] 使用批量归一化网络的集成,我们在ImageNet分类中改进了已发布的最好结果:前5位的验证错误达到了4.9%(和4.8%的测试错误),超过了人工评分者的准确性。
最后,就像不断赠送的礼物一样,批量归一化的作用就像正则化一样,减少了对其他正则化技术(如dropout,本章稍后将介绍)的需求。
但是,批量归一化确实增加了模型的复杂性(尽管它可以消除对输入数据进行归一化的需求,正如我们前面所讨论的)。此外,还有运行时间的损失:由于每一层都需要额外的计算,因此神经网络的预测速度较慢。幸运的是,经常可以在训练后将BN层与上一层融合,从而避免了运行时的损失。这是通过更新前一层的权重和偏置来完成的,以便它直接产生适当的缩放和偏移的输出。例如,如果前一层计算X W + b,则BN层将计算γ⊗(XW + b – μ)/σ + β(忽略分母中的平滑项ε)。如果我们定义W′ = γ⊗W/σ和b′ = γ⊗(b –μ)/σ + β,,则方程式可简化为XW′ + b′。因此,如果我们用更新后的权重和偏置(W′ 和b′)替换前一层的权重和偏置(W和b),就可以去掉BN层(TFLite的优化器会自动执行此操作;请参阅第19章)。
你可能会发现训练相当慢,因为当你使用批量归一化时每个轮次要花费更多时间。通常情况下,这被BN的收敛速度要快得多的事实而抵消,因此达到相同性能所需的轮次更少,总而言之,墙上的时间通常会更短(这是墙上的时钟所测量的时间)。
与使用Keras进行的大多数操作一样,实现批量归一化既简单又直观。只需在每个隐藏层的激活函数之前或之后添加一个BatchNormalization层,然后可选地在模型的第一层后添加一个BN层。例如,此模型在每个隐藏层之后和在模型的第一层(展平输入图像之后)应用BN:
model = keras.models.Sequential([ keras.layers.Flatten(input_shape=[28, 28]), keras.layers.BatchNormalization(), keras.layers.Dense(300, activation="elu", kernel_initializer="he_normal"), keras.layers.BatchNormalization(), keras.layers.Dense(100, activation="elu", kernel_initializer="he_normal"), keras.layers.BatchNormalization(), keras.layers.Dense(10, activation="softmax") ])
就这样!在这个只有两个隐藏层的小例子中,批量归一化不可能产生非常积极的影响。但是对于更深层的网络,它可以带来巨大的改变。
如你所见,每个BN层的每个输入添加了四个参数:γ,β,μ 和 σ(例如,第一个BN层添加了3136个参数,即4×784)。最后两个参数μ和σ是移动平均值。它们不受反向传播的影响,因此Keras称其为“不可训练”9(如果你计算BN参数的总数3,136+ 1,200 + 400,然后除以2,则得到2,368,即此模型中不可训练参数的总数)。
让我们看一下第一个BN层的参数。两个是可训练的(通过反向传播),两个不是:
>>> [(var.name, var.trainable) for var inmodel.layers[1].variables] [('batch_normalization_v2/gamma:0', True), ('batch_normalization_v2/beta:0', True), ('batch_normalization_v2/moving_mean:0', False), ('batch_normalization_v2/moving_variance:0', False)]
现在,当你在Keras中创建BN层时,它还会创建两个操作,在训练期间的每次迭代中,Keras都会调用这两个操作。这些操作会更新移动平均值。由于我们使用的是TensorFlow后端,因此这些操作是TensorFlow操作(我们将在第12章中讨论TF操作):
>>> model.layers[1].updates [<tf.Operation 'cond_2/Identity' type=Identity>, <tf.Operation 'cond_3/Identity' type=Identity>]
BN论文的作者主张在激活函数之前而不是之后添加BN层(就像我们刚才所做的那样)。关于此问题,存在一些争论,哪个更好取决于你的任务—你也可以对此进行试验,看看哪个选择最适合你的数据集。要在激活函数之前添加BN层,你必须从隐藏层中删除激活函数,并将其作为单独的层添加到BN层之后。此外,由于批量归一化层的每个输入都包含一个偏移参数,因此你可以从上一层中删除偏置项(创建时只需传递use_bias = False即可):
model = keras.models.Sequential([ keras.layers.Flatten(input_shape=[28,28]), keras.layers.BatchNormalization(), keras.layers.Dense(300,kernel_initializer="he_normal", use_bias=False), keras.layers.BatchNormalization(), keras.layers.Activation("elu"), keras.layers.Dense(100,kernel_initializer="he_normal", use_bias=False), keras.layers.BatchNormalization(), keras.layers.Activation("elu"), keras.layers.Dense(10,activation="softmax") ])
BatchNormalization类具有许多可以调整的超参数。默认值通常可以,但是你偶尔可能需要调整动量(momentum)。BatchNormalization层在更新指数移动平均值时使用此超参数。给定一个新值V(即在当前批次中计算的输入均值或标准差的新向量),该层使用以下公式来更新运行时平均:
一个良好的动量值通常接近1;例如0.9、0.99或0.999(对于较大的数据集和较小的批处理,你需要更多的9)。
另一个重要的超参数是轴:它确定哪个轴应该被归一化。默认为 -1,这意味着默认情况下它将对最后一个轴进行归一化(使用跨其他轴计算得到的均值和标准差)。当输入批次为2D(即批次形状为[批次大小,特征])时,这意味着将基于在批次中所有实例上计算得到的平均值和标准偏差对每个输入特征进行归一化。例如,先前代码示例中的第一个BN层将独立地归一化(重新缩放和偏移)784个输入特征中的每一个。如果将第一个BN层移动到Flatten层之前,则输入批次将为3D,形状为 [批次大小,高度,宽度];因此,BN层将计算28个均值和28个标准差(每列像素1个,在批次中的所有实例以及在列中所有行之间计算),它将使用相同的平均值和标准偏差对给定列中的所有像素进行归一化。也是只有28个缩放参数和28个偏移参数。相反,你如果仍然要独立的处理784个像素中的每一个,则你应设置axis = [1、2]。
请注意,BN层在训练期间和训练后不会执行相同的计算:它在训练期间使用批处理统计信息,在训练后使用``最终'的'统计信息(即移动平均的最终值)。让我们看一下这个类的源代码,看看如何处理:
class BatchNormalization(keras.layers.Layer): [...] def call(self, inputs,training=None): [...]
如你所见,call ()方法是执行计算的方法,它有一个额外的训练参数,默认情况下将其设置为None,但是在训练过程中fit()方法将其设置为1。如果你需要编写自定义层,它的行为在训练和测试期间必须有所不同,把一个训练参数添加到call()方法中,并在该方法中使用这个参数来决定要计算的内容10(我们将在第12章中讨论自定义层)。
BatchNormalization已成为深度神经网络中最常用的层之一,以至于在图表中通常将其省略,因为假定在每层之后都添加了BN。但是Hongyi Zhang等人最近的论文可能会改变这一假设11:通过使用一种新颖的fixed-update(fixup)权重初始化技术,作者设法训练了一个非常深的神经网络(10,000层!),没有使用BN,在复杂的图像分类任务上实现了最先进的性能。但是,由于这是一项前沿研究,因此你在放弃批量归一化之前,可能需要等待其他研究来确认此发现。
1.4 梯度裁剪
缓解梯度爆炸问题的另一种流行技术是在反向传播期间裁剪梯度,使它们永远不会超过某个阈值。这称为“梯度裁剪”(Gradient Clipping)12。这种技术最常用于循环神经网络,因为在RNN中难以使用“批量归一化”,正如我们将在第15章中看到的那样。对于其他类型的网络,BN通常就足够了。
在Keras中,实现梯度裁剪仅仅是一个在创建优化器时设置clipvalue或clipnorm参数的问题,例如:
optimizer = keras.optimizers.SGD(clipvalue=1.0)model.compile(loss="mse" , optimizer=optimizer)
该优化器会将梯度向量的每个分量都裁剪为 -1.0和1.0之间的值。这意味着所有损失的偏导数(相对与每个可训练的参数)将限制在 -1.0和1.0之间。阈值是你可以调整的超参数。注意,它可能会改变梯度向量的方向。例如,如果原始梯度向量为[0.9,100.0],则其大部分指向第二个轴的方向;但是按值裁剪后,将得到[0.9,1.0],该点大致指向两个轴之间的对角线。实际上,这种方法行之有效。如果要确保“梯度裁剪”不更改梯度向量的方向,你应该通过设置clipnorm而不是clipvalue按照范数来裁剪。如果ℓ2范数大于你选择的阈值,则会裁剪整个梯度。例如,如果你设置clipnorm = 1.0,则向量[0.9,100.0]将被裁剪为[0.00899964,0.9999595],保留其方向,但几乎消除了第一个分量。如果你观察到了梯度在训练过程中爆炸(你可以使用TensorBoard跟踪梯度的大小),你可能要尝试使用两种方法,按值裁剪和按范数裁剪,看看哪个选择在验证集上表现更好。
福利时间
以上内容摘自
《机器学习实战:基于Scikit-Learn、Keras和TensorFlow(原书第2版)》 一书,经出版方授权发布。
国外AI“四大名著”之一!AI霸榜书重磅更新!“美亚”AI+神经网络+CV三大畅销榜首图书,基于TensorFlow2和新版Scikit-Learn全面升级,内容增加近一倍!前谷歌工程师撰写,Keras之父和TensorFlow移动端负责人鼎力推荐,从实践出发,手把手教你从零开始搭建起一个神经网络。
本次活动,极市联合
机械工业出版社华章公司 为大家带来
5本 正版新书 。
在本文下方留言,
10月24日17:00前 ,
小编将在本文留言区随机挑选
5名 极市平台公众号
常读用户 赠送正版图书1本
(在其他公号已获赠本书者重复参加无效)。没中奖的读者也可以扫码下方二维码进行购买~
《机器学习实战:基于Scikit-Learn、Keras和TensorFlow(原书第2版)》
推荐阅读
添加极市小助手微信 (ID : cvmart2) ,备注: 姓名-学校/公司-研究方向-城市 (如:小极-北大-目标检测- 深圳),即可申请加入 极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解 等技术交流群: 每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+ 来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流 ~
觉得有用麻烦给个在看啦~