今天介绍一篇 ICLR 2020 的工作 Adversarial AutoAugment。
作者是来自华为的 Xinyu Zhang, Qiang Wang, Jian Zhang, Zhao Zhong。
之前的那些 NAS 做数据增强的工作,例如 AutoAugment,算法流程大致是这样的:用强化学习训练一个 policy generator ,从样本空间中采样,产生大量的 policy 。每一个 policy 会对应一个做分类任务的子网络,子网络使用这个 policy 来做数据增强,在数据集上随机初始化训练完后,测一下验证集上的准确率作为强化学习的 reward 更新 policy generator。
-
计算开销大,policy generator 要从样本空间中产生大量的 policy,每一个 policy 都对应一个从头开始训练的子网络,更新 policy generator 还必要要等到整个网络训练完。为了给 AutoAugment 加速,有一些方法会提出一些 proxy tasks,比如说用小模型在数据集的一个小的子集上面搜。但是这样做存在一个 proxy tasks 和原始的任务之间的 gap,在 proxy tasks 上面最优不能保证在原始任务上也是最优的;
-
在分类子网络训练的过程中,policy 是静态、一成不变的。这样做可能也不是最优的。
针对这些不足,本文就提出了一种新的方法,policy generator 和分类网络能同时并行训练;此外,在分类网络的训练过程中,还能动态调整 policy 。这种方法和 AutoAugment 相比,在 ImageNet 数据集上的计算开销减少了12倍,训练时间缩短了11倍。
怎么做到的呢?作者引入了 GAN 里面的“对抗”思想,引入了 adversarial loss。整个网络可以看做两部分:一个是 policy generator,优化目标是生成那些让分类器的分类 loss 最大的数据增强 policy;一个是分类器,优化目标是在给定 policy 之后对应的分类 loss 最小。
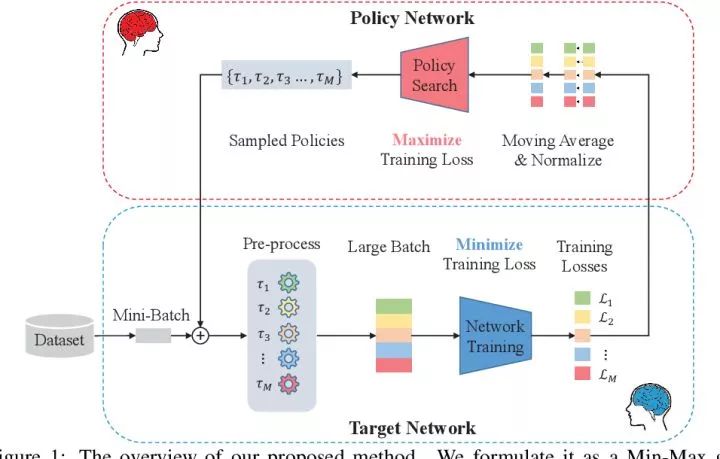
具体的网络结构如下图所示,就是一个分类网络 target network,和一个生成 policy 的 policy network。
![]() 在训练的过程中,policy network 会生成 M 个不同的 policy,并把这 M 个 policy 作用于相同的数据上,得到 M 个分类 loss,并更新分类网络 target network 的权重。而这 M 个分类 loss 也会收集起来,根据 Williams的REINFORCE算法拿来更新 policy network 的权重,目的是最大化分类 loss。如此迭代进行。
加入 adversarial loss 的好处可以看做是两方面:一方面是大大减少了训练所需的时间;另一方面,可以认为policy generator 在不断产生难样本,从而能帮助分类器学到 robust features,从而学的更好。
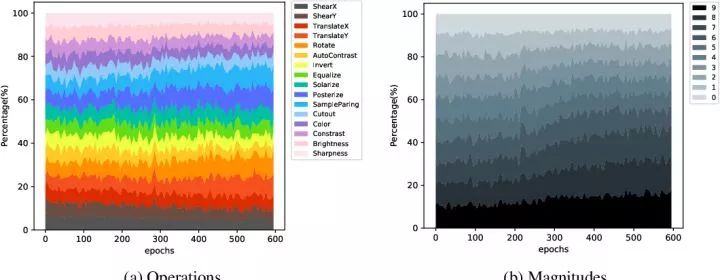
作者也可视化了学到的 policy ,如下图。可以看出随着 epoch 数量的增加,policy generator 会倾向于产生更难的数据增强 policy,如 TranslateX, ShearY and Rotate 这些几何转换会被更多使用。
在训练的过程中,policy network 会生成 M 个不同的 policy,并把这 M 个 policy 作用于相同的数据上,得到 M 个分类 loss,并更新分类网络 target network 的权重。而这 M 个分类 loss 也会收集起来,根据 Williams的REINFORCE算法拿来更新 policy network 的权重,目的是最大化分类 loss。如此迭代进行。
加入 adversarial loss 的好处可以看做是两方面:一方面是大大减少了训练所需的时间;另一方面,可以认为policy generator 在不断产生难样本,从而能帮助分类器学到 robust features,从而学的更好。
作者也可视化了学到的 policy ,如下图。可以看出随着 epoch 数量的增加,policy generator 会倾向于产生更难的数据增强 policy,如 TranslateX, ShearY and Rotate 这些几何转换会被更多使用。
![]()
![]() 作者的这种方法需要比较大的 batch size,一般来说大的 batch size + BN 能涨点,因此直接和 AutoAugment 比较似乎不太公平。针对这一点,如 table 4 所示,作者做了大 batch size + 随机搜索的对照实验,证明自己的搜索策略的有效性。
作者的这种方法需要比较大的 batch size,一般来说大的 batch size + BN 能涨点,因此直接和 AutoAugment 比较似乎不太公平。针对这一点,如 table 4 所示,作者做了大 batch size + 随机搜索的对照实验,证明自己的搜索策略的有效性。
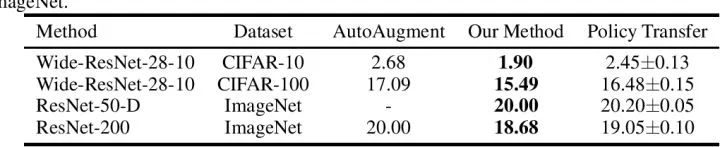
![]() 此外,作者也证明了搜到的 policy 具有很好的迁移性能。如下表所示,用 ResNet 50 在 ImageNet 上搜到的 policy,换到其他模型、其他数据集上也能有不错的结果。
此外,作者也证明了搜到的 policy 具有很好的迁移性能。如下表所示,用 ResNet 50 在 ImageNet 上搜到的 policy,换到其他模型、其他数据集上也能有不错的结果。
![]() 个人感觉 NAS 和 adversarial loss 结合的这个 idea 是很巧妙的,在其他任务中也能借鉴。比如说搜 loss function 的时候用 adversarial loss 或许也能有不错的结果。
个人感觉 NAS 和 adversarial loss 结合的这个 idea 是很巧妙的,在其他任务中也能借鉴。比如说搜 loss function 的时候用 adversarial loss 或许也能有不错的结果。
更多ICLR 2020信息,将在「ICLR 2020 交流群」中进行,加群方式:添加AI研习社顶会小助手(AIyanxishe2),备注「ICLR」,邀请入群。
![]()
ICLR 2020 论文解读系列:
![]()
![]()
![]()
![]() 点击“阅读原文” 前往 AAAI 2020 专题页
点击“阅读原文” 前往 AAAI 2020 专题页