Meta-Learning:Learning to Learn and Applications
作者:Tobias Lee
知乎专栏:NLPer 的成长之路
原文链接,可点击文末"阅读原文"直达:
https://zhuanlan.zhihu.com/p/89448019
Meta-Learning 是一个最近非常 promising 的方向,背后的 Learning to Learn 的思想在解决一些 Low-Resource / Few-shot 场景下的问题是非常有帮助的。因此,这篇文章就是 Meta-Learning 的学习笔记,同时会讨论一些在 NLP 问题上的应用。
Meta-Learning
首先,在了解 Meta-Learning 具体的方法之前,一个很重要的问题就是,Meta-Learning 有什么用?为什么要用 Meta-Learning 呢?先来看看传统监督学习的 paradigm:在 training set 上利用 examples 来 training (update model parameter),然后在 test set 上做 testing (only inference)。
如果我们希望我们的 model 有足够的泛化能力,那么对于 training set 的大小是有一定要求的,一般来说, the bigger the better,这也是现在预训练模型动辄 billion-level 的 Corpus 的一个很重要的原因。并且很多场景下的数据分布,是服从一个长尾分布的,即有一些 class 的样本很多,而有一些 class 的样本很少,典型的就是,类别不均衡问题,在这样的限制之下,怎么学习一个良好的分类器,特别是在那些只有极少数样例的 class 上。
另一个很明显的对比就是人类学习的时候,能够基于过往的经验快速地学习,即使新的任务只有 few examples,比如下面这个图,你觉得是哪个画家的风格呢?:

正确答案是 Braque(我在这两者之间摇摆不定了很久hhh),Chelsea 在 Tutorial 现场是多数人答对了,看来我可能真的没什么艺术天赋?这里每个风格只有 3 个样例,我们答对的一个很大的原因就是来自于过往的经验,如果我们的 Machine Learning Method 也能具备这样的能力,那么他是不是就能离真正的智能更近一步?Meta-Learning 就是用来做这个的,Learning to Learn!
Meta-Learning 的具体定义这里就不再展开,有兴趣的可以参考 Tutorial 中的符号。倒是有一些术语例如 k-shot 值得一提,这里的 k 指的是 example 的数量,而 k-way classification 则是指的是类别的数量。
接下来就是 Meta-Learning 的具体算法,主流算法可以分成三大类:
Black-box Adaption:核心的思想就是学习一个神经网络,来从过去的任务中学习模型的参数,新的任务则会根据之前学到的参数进行预测。因为要不断地 consuming tasks,所以一般这个学习模型参数的模型一般会采用 RNN-based Model。带来的一个问题就是:Outputing all neural net parameters does not seem scalable,要预测一个神经网络的所有参数,是不具备可拓展性的,特别是现在动辄几个 M 的参数的网络。一个直接的解决方案就是输出一个 low-dimension 的 vector 来代表之前 task 的 context,再过一个 NN 来习得模型的参数。
Non-parametric methods:或者说是 Metric-based,通过学一个度量 examples 之间的 metric,来利用之前的任务的信息,比如判断两张图片中的物体是不是同一个类别,一个很常规的方法就是训练一个 Siamese Network,得到各自的表示之后过一个 Distance NN 再判断是否是同类。测试的时候就是利用 test example 和其对应的 metric 进行比对,得到一个预测结果。主要的问题就是:一般受限与分类问题,以及对于 K 的泛化能力不是很好(比对所有的训练集,那么就是和 K 的大小成 linear 复杂度的)
Optimization-based inference:主要就是 Chelsea Finn 提出的 Model Agnostic Meta-Learning (MAML),下一节就详细地讲一讲 MAML。
MAML
之前已经讲了 MAML 提出的动机,就是希望 Model 能够具备快速学习的能力,甚至是在没有见过的样本类别、并且只有少数几个样例的情况下。Chelsea Finn 给出的解决方案就是:
一方面,学习一个好的初始化参数,如果背离目标太远那么快速 adapt 也就无从谈起,当然,这也就变相地要求我们测试的 task 和训练的用的 task 时候要是同一个分布
除了一个好的参数以外,在 training 过程中,我们去模拟 train-test 的过程,即提高模型参数对于 loss 的敏感性,这样才能只用几个样本就能够在未见过的 task 上取得一个比较好的效果
下面这一张图很直观地说明了 MAML 在做的事情:
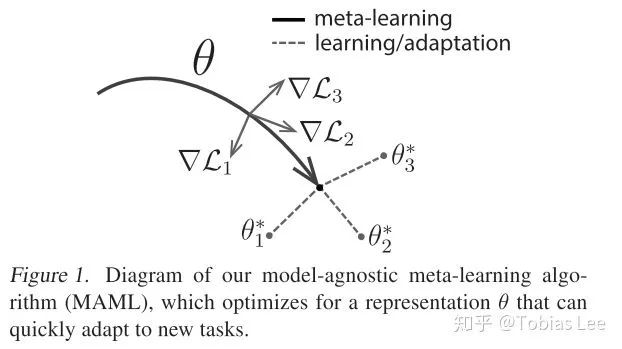
具体的算法框架如下:

可以看到有两个循环:
内循环:采样一个 Task 之后,从这个 Task 中选取一些 examples 作为 training set,并且留一部分作为 validation set,根据这些样本上的 loss 对模型参数进行更新,得到的更新后的参数叫做
外循环:我们用内循环得到的 在之前留出的 validation set 上计算 Loss,再用这个 Loss 来更新原来的模型参数
值得注意的是这里的 只是一个临时的模型参数,最后使用的还是更新过的 。因为外循环通过对模型内循环得到的更新后的参数求导,所以这里隐含着二阶导数,当然,对于有着 Autograd 框架的我们来说只要 loss.backward() + optimizer.step() 就好。
我对于这个算法的理解是这样:首先我们内循环就是一般的梯度更新,但我们把传统的测试阶段也加入到了训练过程之中,即外循环的时候在 validation 集上计算 loss。这一步起到的作用就是引入训练过程中未见过的样例,再利用这上面的 loss 来更新梯度,从而使得模型更新后的参数具备快速 adapt 的能力。直觉上,这样的方法是 make sense 的,数学上能够证明 MAML 最后能够收敛到 optima 吗,Chelsea 也给出了答案,更多的证明就请参考 references 中的文章。
当然,也有研究者认为这样的二阶导数计算复杂,所以也提出了 REPTILE,一个一阶的 Meta-Learning 算法,框架如下:

和 MAML 的不同之处在于,这里的外循环被简化成更新梯度时,取前面更新 k 步后与原模型的改变量的 倍。特别地,当 

Specifically, it maximizes the inner product between the gradients on different minibatches from the same task. If gradients from different batches have positive inner product, then taking a gradient step on one batch improves performance on the other batch.
也就是会有个同一个 task 内,maximize 多个 mini-batch 梯度的内积。Why?我的理解是,内积为正说明梯度的夹角小于九十度,那么两次更新的方向可以认为是近似的,所以一个 batch 上的更新能够提升在另外一个 batch 上的性能,从而提升了模型的泛化能力。
Pre-train & Multi-Task Learning
在学习的 MAML 过程中,会发现它背后的 idea 和目前盛行的 pre-train 很接近,他们都是去学一个初始化的参数,然后在下游的任务上进行 fine-tune;和 multi-task learning 也有些类似,那么它们的区别在哪呢?
和 pre-train 的一个最大的区别在于:MAML 对于新 task 的 fit 能力更强,几步 gradient update 就能够获取一个比较好的性能 适合 few-shot learning 这样的 task,因为在一开始选取参数的时候,pre-train model 侧重的是 model 的表达能力,能够很好的
而 Multi-Task Learning 可以看做是一个 zero-shot meta learning problem,也就是说,经过 multi-task 的 pre-training 之后,不再会有 N-way k-shot 的训练数据给你去 fine-tune 了
Applications in NLP
MAML 在 RL 中四处开花之后,很自然就会想到,把这个 framework 运用到 NLP 中,特别是那些天然存在 few-shot 设置的场景,接下来就介绍几篇 MAML 在具体的一些 NLP 任务上的应用文章(所有的文章都在参考文献里可以找到链接)。
Meta-Learning for Low-Resource Neural Machine Translation: EMNLP 2018 的文章,是 Meta-Learning 在 NMT 上的一次尝试,思路也很直接,机器翻译任务中存在着大量的语言,他们的语料因为使用范围、人数等原因本身就少,规模不大。那么,能不能利用富语料 e.g. En-De / Ch-En 做预训练,从而快速地 fit 小语料的翻译任务呢?套用 MAML 的框架,如果我们把每一个语言对视作是一种 task,那么只有少量数据的语言对的翻译就是 MAML 对应的 k-shot learning 问题,文章也给出了一个很直观的示意图:
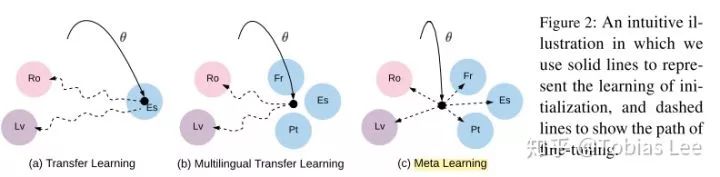
实验的结果就是 MAML 能够在目标的四个语言对上打败 Multi-task Learning 和 Transfer Learning。作者在 training 的时候设计了一项正则项以及使用 ealy-stopping 来避免 meta-update 造成的偏移太大,并且提出了一种 fine-tune 只更新部分 Module 的思路,怀疑这个方法面临的一个主要问题就是在 Meta-Learning 阶段,模型参数容易产生比较大的偏移,从而倾向于某一种 source task,进而在下游任务取得比较差的表现。
Personalizing Dialogue Agents via Meta-Learning: EMNLP 19, 短文。在 PersonaChat(ConvAI2) 上做的 persona-chat 的实验,这篇文章把 Persona 看做是不同的 task,旨在不使用 Persona 的信息,仅仅通过用 MAML 来根据 dialog history,学习生产 personalized 的对话。生成的实验结果很有意思,在 BLEU 和 PPL 都没能超过普通的 Seq2Seq 方法,但是在 persona 的一致性和 Human-Evaluation 上超过了 Baseline。persona 一致性是通过一个预训练的分类器,判断对话是否和 persona 对应训练出来的。有点奇怪的是,PPL 和人类对 fluency 的评估结果是相反的。
Investigating Meta-Learning Algorithms for Low-Resource Natural Language Understanding Tasks:EMNLP 19 的一篇短文,如标题所说,主要是探究 MAML 在 NLU 任务上的应用。直接套框架,主要贡献在于比较了 MAML、FOMAML 以及 REPTILE 三种 MAML 算法的效果,并且对采样任务的方法(uniform/根据 dataset size 采样)做了探究。
Learning to Learn and Predict: A Meta-Learning Approach for Multi-Label Classification:EMNLP 19, 长文,这篇文章利用 Meta-Learning 的方式不再是学习初始化,而是之前的方式一:输出模型的参数。具体来说,是输出一个多标签分类器的 threshold 以及各个标签类别对于 loss function 的权重,motivation 在于:
多标签分类问题,存在标签之间的 dependency,以及不同标签之间的区分度是不同的(区别 organization 和 person 很简单,但是区别 broadcast 和 news 就不容易了),因此需要一个 label-specific 的 classifier
用 Meta-Learning 的思路,我们可以学习一个 classifier,而全部输出参数的话不太现实,这篇文章采用了输出两个值:分类的 threshold 以及不同 label 对于 loss function 的贡献度(权重)
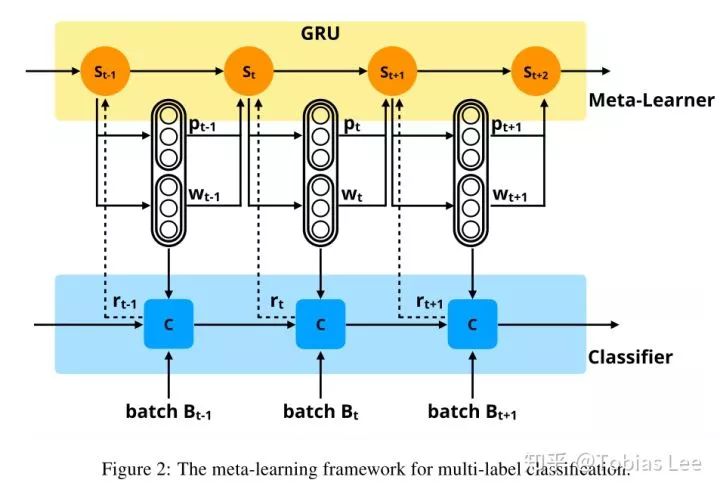
需要解决的一个不可微分的问题(threshold 这里有个对梯度的截断),所以文章提出用 Policy gradient 的方法来训练这个 classifier,设计了一个跟预测的 threshold 以及 prediction label prob 的相关的 reward,具体请参考文章中的公式,一句话说就是分类正确并且和预测的 label 概率值和 prob threshold 差距越大,则 reward 越高,反之则会收到惩罚。
Summary
总结一下:
MAML 或者说 Meta-Learning 还是有很大的应用空间的,因为具体的问题存在着很多 few-shot 的场景,如果真的有这样的需求,那么可以尝试一下 MAML
简单的套用 MAML 框架,对于 NLP community 来说其实是没有太大增益的,想要有更大的 Contribution,还是需要结合具体的问题,针对问题提出基于 MAML 相应的解决方案。
References
ICML 2019 Meta-Learning Tutorial
PhD Thesis of Chelsea Finn - Learning to Learn with Gradient
Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks
Meta-Learning and Universality: Deep Representations and Gradient Descent can Approximate any Learning Algorithm
Reptile: On First-Order Meta-Learning Algorithms
Meta-Learning for Low-Resource Neural Machine Translation
Learning to Learn and Predict: A Meta-Learning Approach for Multi-Label Classification
Personalizing Dialogue Agents via Meta-Learning
Learning to Learn and Predict: A Meta-Learning Approach for Multi-Label Classification
Investigating Meta-Learning Algorithms for Low-Resource Natural Language Understanding Tasks
本文由作者授权AINLP原创发布于公众号平台,点击'阅读原文'直达原文链接,欢迎投稿,AI、NLP均可。
推荐阅读
BERT 瘦身之路:Distillation,Quantization,Pruning
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLP君微信(id:AINLP2),备注工作/研究方向+加群目的。




