ECCV 2018 | 港科腾讯等提出Bi-Real net:超XNOR-net 10%的ImageNet分类精度
极市平台(ExtremeMart)是深圳极视角旗下的专业视觉算法开发与分发平台,为开发者提供行业场景集,每月上百真实项目需求,算法分发,技术共享等,旨在联合开发者建立起良好的计算机视觉生态。已与上百名开发者建立了合作并转化了上百种视觉算法。
PS.8月29日(本周三)晚20:00~21:30,图普科技深度学习算法工程师小美,及格林深瞳算法团队张德兵,将为大家分享基于分布式人脸训练谜题思路及背后的工业级应用,公众号回复“32”即可获取直播详情。
这项工作由香港科技大学,腾讯 AI lab,以及华中科技大学合作完成,目的是提升二值化卷积神经网络(1-bit CNN)的精度。虽然 1-bit CNN 压缩程度高,但是其当前在大数据集上的分类精度与对应的实值 CNN 相比有较大的精度下降。本文提出的 Bi-Real net 用 shortcut 传递网络中已有的实数值,从而提高二值化网络的表达能力,并且改进了现有的 1-bit CNN 训练方法。试验结果表明,18 层 Bi-Real net 在 imagenet 数据集上达到 56.4%的 top-1 分类精度,比 baseline XNOR Net 相对高了 10%。并且更深的 34 层 Bi-Real net 达到了 62.4%的 top-1 分类精度。

地址:https://arxiv.org/pdf/1808.00278.pdf
深度卷积神经网络(CNN)由于精度高在视觉任务中已经有非常广泛的应用,但是 CNN 的模型过大限制了它在很多移动端的部署。模型压缩也因此变得尤为重要。在模型压缩方法中,将网络中的权重和激活都只用+1 或者-1 来表示将可以达到理论上的 32 倍的存储空间的节省和 64 倍的加速效应。由于它的权重和激活都只需要用 1bit 表示,因此极其有利于硬件上的部署和实现。
然而现有的二值化压缩方法在 imagenet 这样的大数据集上会有较大的精度下降。我们认为,这种精度的下降主要是有两方面造成的。1. 1-bit CNN 的表达能力本身很有限,不如实数值的网络。2. 1-bit CNN 在训练过程中有导数不匹配的问题导致难以收敛到很好的精度。
针对这两个问题,我们分别提出了解决方案。
1. 通过分析我们发现,尽管输入 1-bit 卷积层的参数和激活值都是二值化的,但经过 xnor 和 bitcout 之后,网络内部会产生实数值,但是这个实数值的输出如果经过下一层 1-bit 卷积就又会被二值化,造成极大的信息丢失。
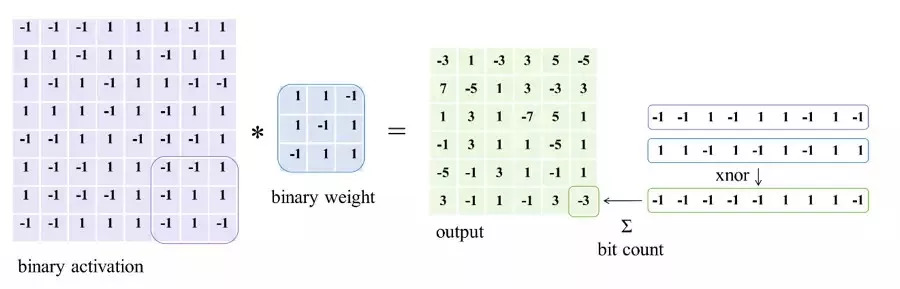
通过打印网络内部的由激活值组成的特征图也可以发现这一个问题
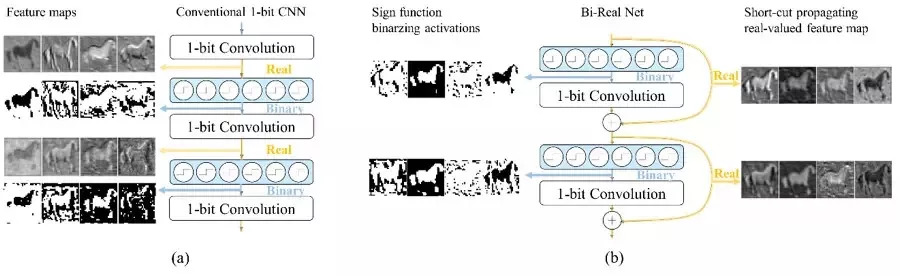
左图是传统神经网络,连续灰度的特征图每次经过 1-bit 卷积的时候,都会被二值化。所以我们提出在特征图在被二值化之前,利用 shortcut 来传递这些实数值的特征图,这样就可以大大地保留网络中的信息量,提高网络的表达能力。
2. 除此之外,我们分析了原有的二值化网络的训练方法,发现原有训练方法在对于激活值的求导和对于参数的更新存在导数不匹配的问题。我们针对激活值的求导和参数更新问题分别提出了解决方案。
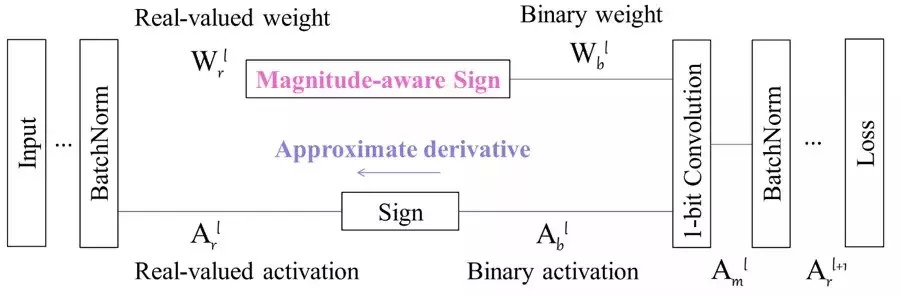
(1)在对激活值求导的时候,由于二值化激活值的 sign 函数不可导,所以在前人(Binary Net)采用的方法是利用 clip(-1,x,1) 的导数来拟合 sign 的导数,但是这样造成的效果就是,网络在正向计算 loss 的时候所看到的是一个以 sign 为非线性函数的网络,而在反向计算 gradients 的时候是根据一个以 clip 为非线性函数的网络进行计算的。由于 clip 函数与 sign 函数有差距,这种计算方式会带来所谓的导数值不匹配的问题。基于这个,我们提出用二阶拟合 sign 的 ApproxSign 的导数来作为 sign 的导数,从而缩小导数值的不匹配问题。这个带来了约 12% 的性能提升。

(2)而在对二值化参数进行更新的时候,由于二值化参数是离散的,导数值太小往往不足以改变它的符号,因此前人采用的方法是存储实数值的参数,在更新的时候将网络根据二值参数计算出来的导数更新实数值参数,在正向传播过程中,用 sign 将实数值参数二值化,得到更新后的二值化参数。
但是这样的更新方式的实质是,将对于二值化参数求得的导数值加在存储的实数值。而在将导数二值化的时候,sign 函数其实只考虑了所存储的实数参数的符号,而没有考虑存储使出参数的量级,由于一些训练上的考虑,实数值网络内部的参数值,往往集中在 0 附近,而直接把它二值化到+1 或者-1,会导致网络计算导数值所参考的参数和网络实际更新的参数有很大差距,使得网络难于收敛到较高精度。
基于这个观察,我们提出,在训练的时候,将网络中存储的实数值的量级计入考虑。
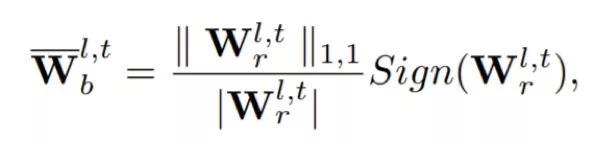
根据用实数值参数的绝对值平均值计算的标量乘以实数值参数的符号作为网络计算导数的二值化参数。这种方法大大缩小了二值化参数与网络内部存储的用于更新的实值参数之间的差距,达到 23% 的网络精度值相对提升。
而更加有意思的是,由于 BatchNorm 层的存在,这个帮助训练的标量,其实在正向传播的时候可以直接被 BatchNorm 层归一化。因此,在测试即部署训练好的二值化的网络到移动端的时候,并不需要这一实值标量。
(3)此外我们还提出了针对二值化网络的初始化方法。从二值化参数更新的方法里也可以看出,内部所存储的实数值代表了二值化参数能改变符号的可能性,因此初始化的实数值选取非常重要。之前的工作都是直接采用随机初始化(XnorNet)或者是直接用以 ReLU 为非线性函数的实数值网络初始化。我们发现,如果采用 Clip 函数替换 ReLU 函数来进行初始化,将进一步带来性能提升。
实验结果
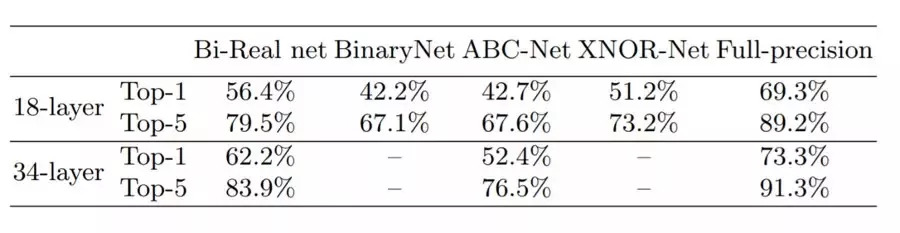
从表中的比较可以看到, 本文提出的 Bi-Real net 比 state-of-the-art Xnor Net 精度由显著提升。
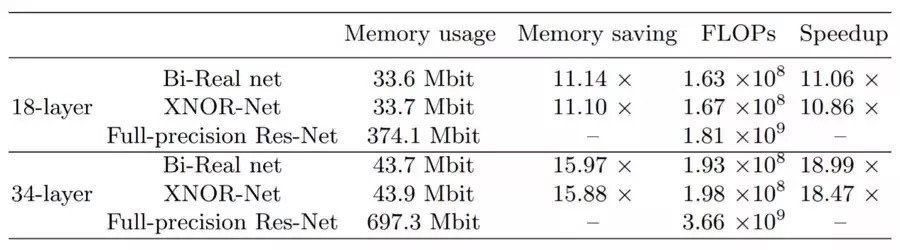
并且 Bi-Real net 比 Xnor net 需要更少的存储空间和计算资源。
来源:机器之心
*推荐阅读*
ECCV2018|视觉目标跟踪之DaSiamRPN
ECCV18 Oral | MIT&谷歌视频运动放大让计算机辅助人眼“明察秋毫”
PS.8月29日(本周三)晚20:00~21:30,图普科技深度学习算法工程师小美,及格林深瞳算法团队张德兵,将为大家分享基于分布式人脸训练谜题思路及背后的工业级应用,点击文末阅读原文申请加入谜题活动交流群,~




