一文读懂知识图谱的商业应用进程及技术背景
作者丨林锦周
公司丨澳银资本TMT负责人
关注方向丨知识图谱,深度学习
知识图谱(Knowledge Graph/Vault,以下简称 KG)本质上是语义网络,是一种基于图的数据结构,由节点(Point)和边(Edge)组成。在知识图谱里,每个节点表示现实世界中存在的“实体”,每条边为实体与实体之间的“关系”。知识图谱是关系的最有效的表示方式。通俗地讲,知识图谱就是把所有不同种类的信息(Heterogeneous Information)连接在一起而得到的一个关系网络。知识图谱提供了从“关系”的角度去分析问题的能力。
KG应用篇
在知识图谱应用这一块我会通过介绍名人知识图谱的聚类、知识图谱在搜索引擎、聊天机器人、金融科技领域等的商业应用。
进一步形象的解释这个定义,人物、作品、地点、数值、身高等都可以作为知识图谱中的节点,我们称这些节点为实体。 实体可以由若干个属性表示,节点关系这类可以有妻子、女儿、哥哥、偶像、同门等关系属性。通过实体的属性可以将不同的实体建立关联关系,例如:
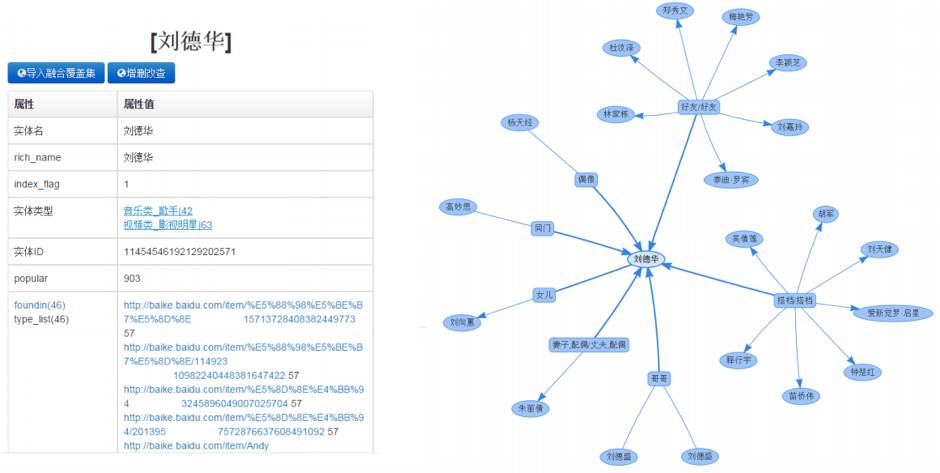
但这里面很多做知识图谱网络的公司都出过问题,比如同时在电影和音乐知识图谱内,电影数据源里有刘德华,音乐数据源里也有刘德华,这两其实是一个人,但是知识图谱目前的聚类分布效果并不好,经常容易出现两个刘德华。
从不同数据源构建图谱的时候,必须有自动化的算法将各处的刘德华聚类,这里面最难也最需要抓紧解决的是 如何将来自不同数据源的相同实体聚类。这方面谷歌走过弯路,但现在 Google now 的崛起也证明了谷歌正在从搜索引擎往谷歌知识图谱转型。
知识图谱最早被应用于搜索引擎领域。
自从 2012 年 Google 推出自己第一版知识图谱以来,它在学术界和工业界掀起了一股热潮。各大互联网企业在之后的短短一年内纷纷推出了自己的知识图谱产品以作为回应。比如在国内,互联网巨头百度和搜狗分别推出”知心“和”知立方”来改进其搜索质量。旨在通过语义把碎片化的数据关联起来,让用户能直接搜索到事务(Things),而不是文本字符串(Strings)。在搜索引擎中引入知识图谱大幅的提升和优化了搜索体验。
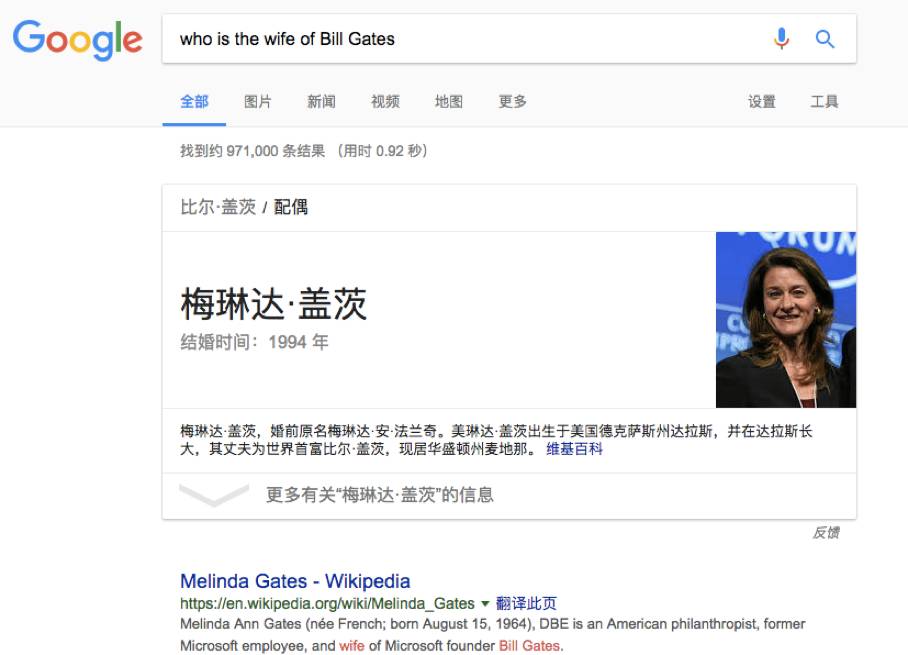
不同于基于关键词搜索的传统搜索引擎,知识图谱可用来更好地查询复杂的关联信息,从语义层面理解用户意图,改进搜索质量。比如在 Google 的搜索框里输入 Bill Gates 的时候,搜索结果页面的右侧还会出现 Bill Gates 相关的信息比如出生年月,家庭情况等等。对于稍微复杂的搜索语句比如 ”Who is the wife of Bill Gates“,Google 能准确返回他的妻子 Melinda Gates。这就说明搜索引擎通过知识图谱真正理解了用户的意图。
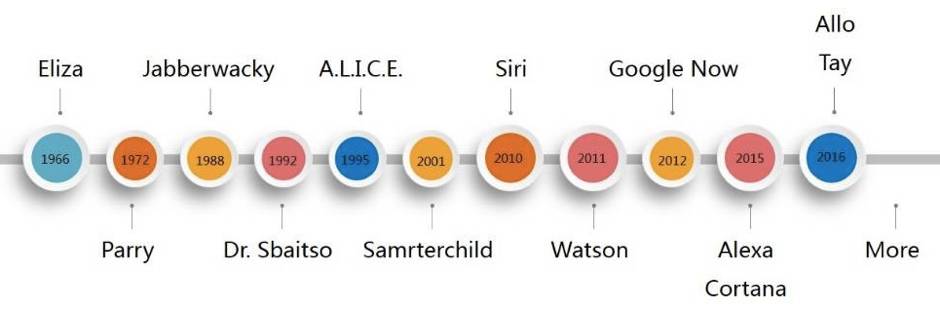
近年来,随着人工智能的再次兴起,知识图谱又被广泛的应用于聊天机器人和问答系统中,用于辅助深度理解人类的语言和支持推理,并提升人机问答的用户体验等。典型的如 IBM 的 Watson,苹果的 Siri,Google Allo,Amazon Echo,百度度秘,公子小白等。


知识图谱也被广泛用于各种问答交互场景中。Watson 背后依托 DBpedia 和 Yago 等百科知识库和 WordNet 等语言学知识。类似地,Alexa 也依托其早年收购的 True Knowledge 公司所积累的知识库;Siri 则利用 DBpedia 和可计算的知识服务引擎 WolframAlpha;狗尾草公司推出的虚拟美少女机器人琥珀虚颜则用到了首个中文链接知识库 Zhishi.me。
伴随着机器人和 IoT 设备的智能化浪潮,智能厨房、智能驾驶和智能家居等应用层出不穷。无独有偶,百度推出的 Duer OS 和 Siri 的进化版 Viv 背后也都有海量知识库的支撑。
小冰是微软中国团队推出的娱乐聊天机器人。她的人设是一位 16 岁的少女。小冰是一个基于搜索的回复检索系统。通过各种基于深度学习的语义匹配算法,从海量的问答对语料中返回最佳的回复(Message response 而非 Answer)。小冰也会不定期推出新的技能供大家使用,这些技能往往包含了微软团队在图像理解、语音和自然语言理解方面的各种小应用尝试。
更值得一提的是:微软针对日本、北美和欧洲等市场陆续推出了具有不同人设的少女如 Rinna、Tay 和 Zo,她们往往可以方便的通过微信、微博或 Twitter 等平台进行交流。
此外,知识图谱还被用来提升数据分析的能力和效果。例如著名的大数据公司Palantir利用知识图谱建立数据的关联以提升上游数据分析的效果。与知识图谱有关的语义技术也被用来提升机器与机器之间的语义互操作能力,解决机器之间的语义理解问题。例如,全球最大物联网标准化组织OneM2M就把语义和知识技术作为物联设备抽象和语义封装的技术基础。
在金融、农业、电商、医疗健康、环境保护等大量的垂直领域,知识图谱都得到广泛的应用。例如,很多金融领域公司也构建了金融知识库以进行碎片化金融数据的集成与管理,并辅助金融专家进行风控控制、欺诈识别等;生物医疗专家通过集成和分析大规模的生物医学知识图谱,辅助其进行药物发现、潜在靶点识别等多方面任务。
就金融领域来说,规则可以是专家对行业的理解,投资的逻辑,风控的把握,关系可以是企业的上下游、合作、竞争对手、子母公司、投资、对标等关系,可以是高管与企业间的任职等关系,也可以是行业间的逻辑关系,实体则是投资机构、投资人、企业等等,把它们用知识图谱表示出来,从而进行更深入的知识推理。
这里我们主要围绕着知识图谱在国内金融市场的应用敞开来讲,目前在中国市场上我们可以将看到的主要的各种类型的金融知识图谱做个简单分类。


这里面知识图谱在国内金融市场的细分应用,超过 15 项,其中有 10 项是在去年一年的时间内出现的,足以见得技术成本的有效下滑对这个行业的促进影响作用。此外,有些国内的消费金融及互联网金融公司也积极在利用知识图谱加强自身的风控和完善用户画像,这里我们举个京东金融的例子。
京东金融团队花了大量时间研究消费者在京东商城上的行为知识图谱数据。一笔真实交易之前,有二三十倍的行为数据,都是碎片化的,风控团队的工作就是对这些细枝末节进行甄别评级,细节甚至包括同一个用户买东西是先看购物车,还是先看优惠券频道。“一下子到购物车的,则欺诈风险较大,因为他根本不去比价,有可能是欺诈性风险套现的个案”。
因为京东从商户的选择到物流都是自己做,能掌握更多、更准确的一手的数据。例如,除了电商交易数据之外,京东的自有物流可以提供大量的物流数据。”现在通过这些数据,可以判断一笔交易背后的众多逻辑:“比如是否是一个活跃客户——活跃客户一般违约概率都比较低。
如果用户买的电视是 60 英寸产品,很容易推断出他会有一个大客厅,这些看似跟信用没有强关联的碎片化数据经过模型处理就能够变得有用。” 京东金融已披露投资的技术类公司有 8 家。这些公司涉及数据源、数据抓取业务、数据清洗及建模等业务。京东金融 4000 多名员工中,一半属于风控和技术团队成员。
在消费金融内部,近百人集中在模型搭建环节,另一部分集中在数据挖掘,大量数学及统计博士在做模型开发和量化开发工作。和市场上大部分的竞争对手相比,京东金融在数据的丰富度和质量方面更有优势,因此通过知识图谱方式来构建用户画像及相应的风控模型,他们是有明显的先发优势。
在互联网飞速发展的今天,知识大量存在于非结构化的文本数据、大量半结构化的表格和网页以及生产系统的结构化数据中。在全球不断汇集的数据中,知识图谱帮助我们去精准地结构化每一层数据,每一条新闻、每一条微博、每一条朋友圈信息流、每一条网页数据。
对于每一条非结构化数据,通过精准地解构出来平均 7-8 条的知识图谱,包含了时间、地点、人物、事件、机构等等。而我们将这超过 3000 万篇章、5 亿多条每一天的数据更新,叠加出来去分析,每两点之间、三点之间、任意一点之间、任意一个要素之间的关联关系。而这些在数据底层里面构成了一个去掉语言符号,汇集起来庞大无比的知识图谱。
KG技术篇
当前世界范围内已经有非常成熟且知名的高质量大规模开放知识图谱,包括 DBpedia、Yago、Wikidata、BabelNet、ConceptNet以及Microsoft Concept Graph。其中 DBpedia 是一个大规模的多语言百科知识图谱,可视为是维基百科的结构化版本。Wikidata 是一个可以自由协作编辑的多语言百科知识库,它由维基媒体基金会发起,期望将维基百科、维基文库、维基导游等项目中结构化知识进行抽取、存储、关联。
BabelNet 是目前世界范围内最大的多语言百科同义词典,它本身可被视为一个由概念、实体、关系构成的语义网络(Semantic Network)。BabelNet 目前有超过 1400 万个词目,每个词目对应一个 synset。每个 synset 包含所有表达相同含义的不同语言的同义词。比如:“中国”、“中华人民共和国”、“China”以及“people’srepublic of China”均存在于一个 synset 中。
中文目前可用的大规模开放知识图谱有 Zhishi.me、Zhishi.schema 与 XLore。其中 Zhishi.me 是第一份构建中文链接数据的工作,与 DBpedia 类似,拥有约 1000 万个实体与一亿两千万个 RDF 三元组。
Zhishi.schema 是一个大规模的中文模式(Schema)知识库,其本质是一个语义网络,其中包含三种概念间的关系,即 equal、related 与 subClassOf 关系。Zhishi.schema 抽取自社交站点的分类目录(Category Taxonomy)及标签云(Tag Cloud),目前拥有约 40 万的中文概念与 150 万 RDF 三元组,正确率约为 84%,并支持数据集的完全下载。
此外,中文开放知识图谱联盟(OpenKG)目前也非常受业内欢迎,作为推动中文知识图谱的开放与互联的平台,它已经搭建有 OpenKG.CN 技术平台,目前已有 54家机构入驻。吸引了国内最著名知识图谱资源的加入,如 Zhishi.me, CN-DBPedia,PKUBase。并已经包含了来自于常识、医疗、金融、城市、出行等 15 个类目的开放知识图谱。

知识图谱的计算流程一般包括:知识提取、知识表现融合、知识存储计算及知识检索应用。
知识获取:在处理非结构化数据方面,首先要对用户的非结构化数据提取正文。目前的互联网数据存在着大量的广告,正文提取技术希望有效的过滤广告而只保留用户关注的文本内容。
当得到正文文本后,需要通过自然语言技术识别文章中的实体,实体识别通常有两种方法,一种是用户本身有一个知识库则可以使用实体链接将文章中可能的候选实体链接到用户的知识库上。另一种是当用户没有知识库则需要使用命名实体识别技术识别文章中的实体。
知识融合(knowledge fusion)指的是将多个数据源抽取的知识进行融合。知识计算主要是根据图谱提供的信息得到更多隐含的知识,如通过本体或者规则推理技术可以获取数据中存在的隐含知识;而链接预测则可预测实体间隐含的关系;同时使用社会计算的不同算法在知识网络上计算获取知识图谱上存在的社区,提供知识间关联的路径。
通过不一致检测技术发现数据中的噪声和缺陷。通过知识计算知识图谱可以产生大量的智能应用如可以提供精确的用户画像为精准营销系统提供潜在的客户;提供领域知识给专家系统提供决策数据,给律师、医生、公司 CEO 等提供辅助决策的意见;提供更智能的检索方式,使用户可以通过自然语言进行搜索;当然知识图谱也是问答必不可少的重要组建。
以上是知识图谱漫谈第一期,如您对 KG 的应用感兴趣,可以加我微信交流(348911857)。
澳银资本 TMT 负责人 Jocy 林锦周,目前主要 cover 技术驱动的方向,期待 AI + 领域项目可以多多合作。澳银主要投资阶段是 A 轮之前,preA 和天使轮估值区间在 5000 万~2 亿之间,这边 TMT 主要看软硬科技两个大方向,硬件主要是物联网机器人,软科技主要覆盖金融投顾、消费级 AI 应用方向。
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。





