这是一份通俗易懂的知识图谱技术应用落地指南
在面向对象的时代里,我们常说万物皆对象,之前我们只是来分析对象的个体,随着互联网和社交网络的发展,对象与对象之间的联系变得越来越紧密,我们把一个对象称之为一个实体。

我们现在对于实体之间关系的分析变得尤为重要,我们可以使用知识图谱相关技术,来挖掘实体之间的关系,从而找到其中的商业价值,打造自己的知识图谱应用。
2018 年 11 月 30 日-12 月 1 日,由 51CTO 主办的 WOT 全球人工智能技术峰会在北京粤财 JW 万豪酒店隆重举行。
本次峰会以人工智能为主题,金山办公 AI 领域专家黄鸿波在业务实践专场与来宾分享"知识图谱在企业中的落地"的主题演讲。
本文将按照如下四个层次向大家介绍知识图谱在企业中的落地情况:
知识图谱发展展望,包括知识图谱的定义和实现方式。
知识图谱常见应用场景,包括如何来应用和具体的应用场景。
知识图谱图数据库选型,包括选型比较和经验分享。
知识图谱落地,包括落地方案的制定和从无到有的图谱架构。
知识图谱发展展望
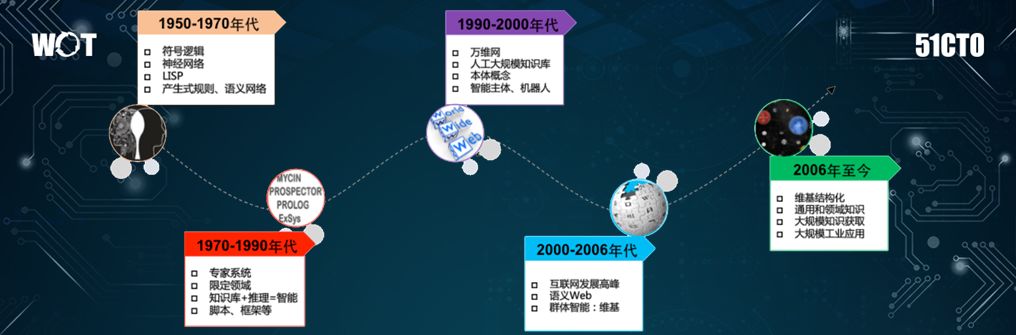
我们先来看看知识图谱的发展历史:
50 年代到 70 年代,符号逻辑、神经网络、LISP(List Processing语言)、还有一些语义网络已经出现,不过尚处于简单且不太规范的知识表示形式。
70 年代到 90 年代,出现了一些专家系统,一些限定领域的知识库(如金融、农业、林业等领域),以及后来出现的一些脚本、框架、推理。
90 年代到 00 年,出现了万维网、人工大规模知识库、本体概念、以及智能主体与机器人。
00 年到 06 年,出现了语义 Web、群体智能、维基百科、百度百科、以及工作百科之类的内容。
06 年至今,我们对数据进行了结构化。但是数据和知识的体量越来越大,因此导致了通用知识库越来越多。随着大规模的知识需要被获取、整理、以及融合,知识图谱应运而生。

从发展里程碑来看:
2010 年,微软发布了 Satori 和 Probase,它们是比较早期的数据库,当时图谱规模约为 500 亿,主要被应用于微软的广告和搜索等业务。
接着在 2012 年,谷歌推出了 Knowledge Graph(知识型图数据库),当时的数据规模有 700 亿。
后来,Facebook、阿里巴巴、以及亚马逊也相继于 2013 年、2015 年和 2016 年推出了各自的知识图谱和知识库。它们主要被用在知识理解、智能问答、以及推理和搜索等业务上。
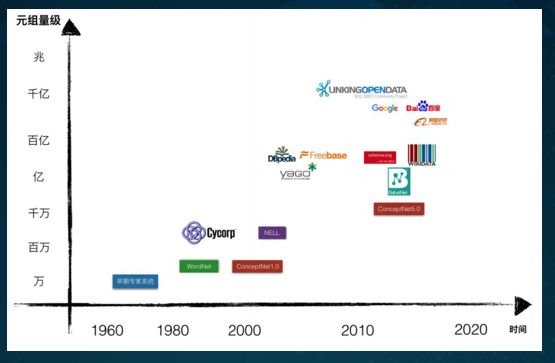
从数据的处置量来看,早期的专家系统只有上万级知识体量,后来阿里巴巴和百度推出了千亿级、甚至是兆级的知识图谱系统。
上图便是如今在知识图谱领域的世界各大知名公司,可见该领域的玩家还是非常多的。
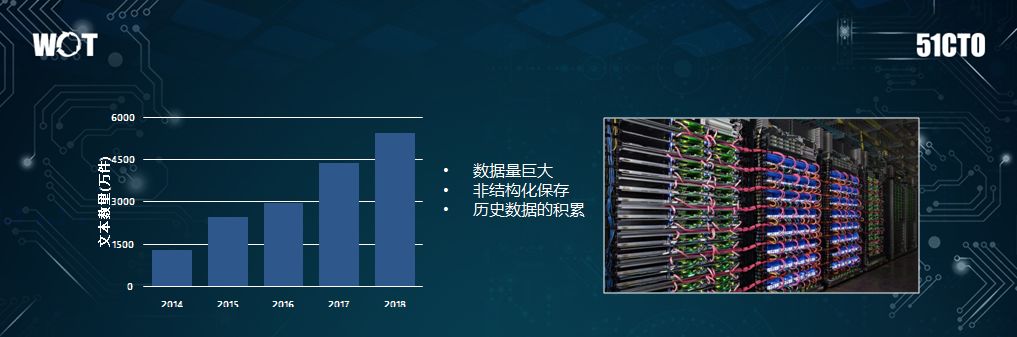
上图左表反映的是我们曾经给客户做过的某类法律文本在数量上的变化趋势。
在 2014 年文本的数量还不到 1500 万,而到了 2018 年总量就超过了 4500 万。
我们预计至 2020 年,文本的数量有望突破 1 亿万件(某一特定类别)。那么,我们现在所面临的问题包括:数据量的庞大、非结构化的保存、以及历史数据的积累等方面。
这些都会导致信息知识体、以及各种实体的逐渐膨胀。因此,我们需要通过将各种知识连接起来,形成知识图谱。
知识图谱常见应用场景
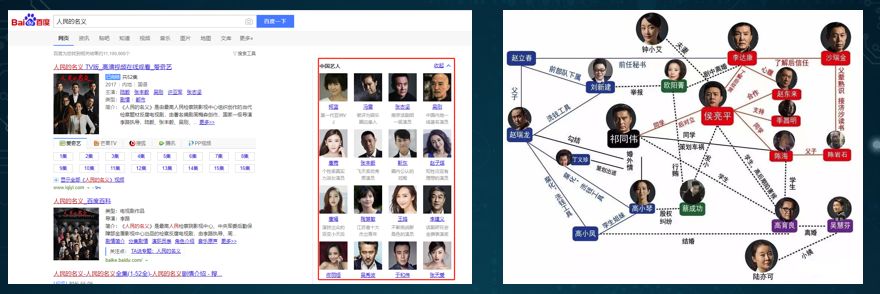
知识图谱可以被用于查找人与人之间的关系,如上图所示,我们可以理解为电视剧《人民的名义》中人物的关系图谱。而在很多企业中,就是用到知识图谱来找出用户与用户之间的关系。
知识图谱的另一个应用场景是:找出实体之间的关系。所谓实体,我们可以理解为早年曾提到的“面向对象”中“对象”这一概念。
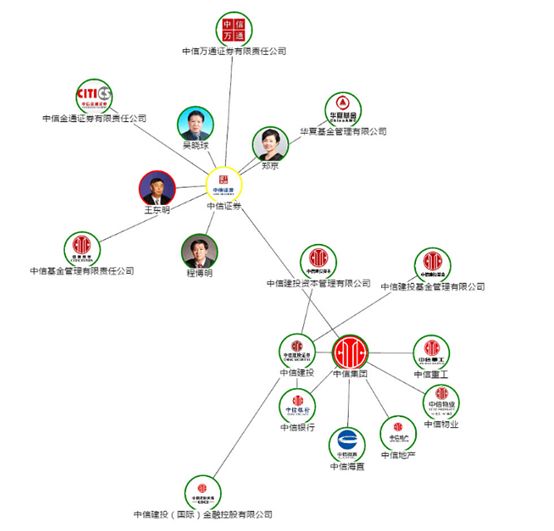
如上图所示,在公司和企业之间,包括它们的子公司、以及合作公司之间都存在着实体的关系,这就是知识图谱的核心概念。
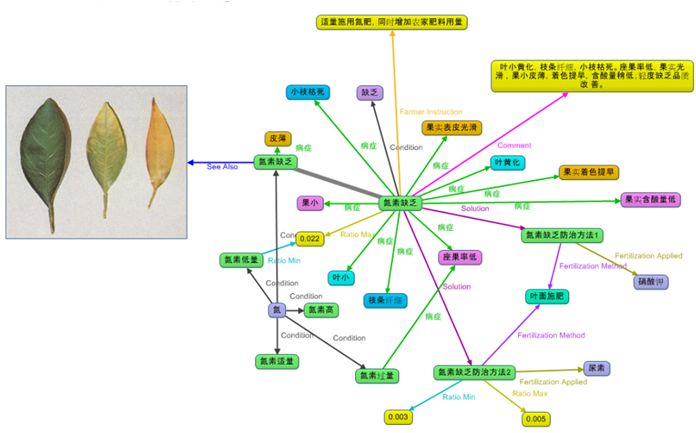
上图是知识图谱在农业方面的应用。可见,由氮素缺乏辐射开来之后,最终会导致叶子的枯萎,以及落果率的降低等农业方面的歉收情况。
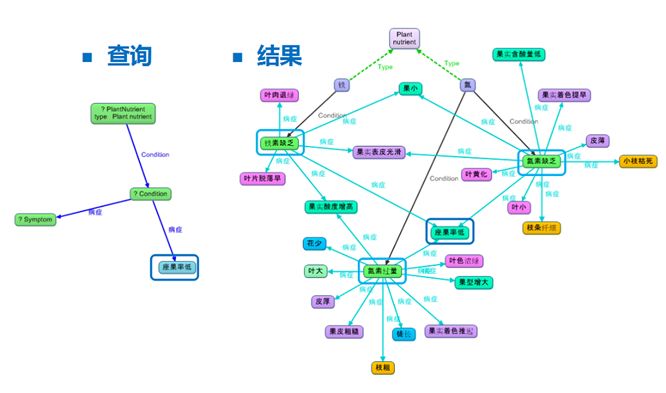
因此,我们在做知识图谱的时候,实际上就是要查找并建立各个实体之间的联系。

如上图所示,在知识图谱的研究和落地方面,业界一般分为三大类:
智能语义的搜索。例如:我们通过搜索引擎把各种知识点、实体、以及内容结合起来,形成实体之间的关系。
个性化的推荐。例如:我们在网购和浏览头条新闻时,下一次打开某个 App 所看到的内容,往往是该系统根据上一次搜索过的相关内容所做出的个性化推荐。
智能问答。比如:某家空调公司需要上线一个“知识问答”功能。那么他们既要收集本领域的电器相关知识,又要从外部实体那里抽取电路设计、功率设计、能耗设计、智能程度和用电量等方面的知识。
因此,他们会通过推荐或者是知识的抽取与融合,将结果保存到分布式图数据库里,进而发现各个点与点之间或是边与边之间的关系。
就每天有着超过两亿日活用户数的 WPS 而言,我们需要通过建立用户节点,将用户的基本信息、属性特征和他们的文档联系起来,存放到普通数据库(如 MongoDB)里,然后再转化成图数据库的关系。
同时,我们需要梳理出各个用户节点之间的边。比如说:如果用户A和B来自同一家公司,他们就可能会有同一条边;如果他俩共享过了某个文档,则又会生成一条边。
因此具体寻找边的表述方式会有如下两种:
通过对数据的搜寻,发现在同一个数据库中不同节点所包含的共同字段和属性。
通过知识的融合与发掘、以及文档内容的语义,提取文字或标题的中心内容,再运用算法分析,采用主体之间的对比方式,找到两个用户之间可能存在的关系,进而建立一个知识体。
知识图谱图数据库选型

在做知识图谱时,我们最常碰到的问题莫过于对图数据库的选择。当前,业界有 Neo4j 和 Cayley 这两种最为常用的图数据库可供选择。
大家可能会普遍地认为:无论是网上资料的丰富程度,还是数据库知名度的排名,Neo4j 在各个方面的优势都胜过 Cayley。然而在实际选型中,我们却选择了后者。
具体原因如下:
数据的体量。由于我们公司有着两亿规模的日活数据量,而且还会持续产生无数个节点,因此我们需要选用一款能够支持大体量数据的数据库。
开源的属性。如今 Neo4j 的企业版已经不再开源。而就算它以前的开源模式也并不完全。由于其核心内容并未开源,因此一旦出现了问题,我们很难得到及时的支持与帮助。
是否支持分布式。鉴于上述企业版的限制,有人曾提出采用免费的版本。可是,由于只有企业版的 Neo4j 才能支持分布式存储与集群,而且其免费版无法支撑我们的数据体量,因此我们后续没有再去考虑 Neo4j。
落地时的性能。其间,我们还曾经对比过 Dgraph 与 Cayley。鉴于两者都是开源型的数据库,且都能够支持分布式,因此我们考量了它们的第三个维度:落地时的性能。
我们曾经使用上亿的数据量,去分别检验两种数据库查找关系和建立关系的性能。
随后,我们发现由于自身存在着 Bug,Dgraph 对于支持边的权重计算存在着缺陷,会导致在进行边与边、点与点的计算时出现性能上的问题。
因此经过综合考虑,我们最终还是选用了 Cayley 作为自己的图数据库。当然,我们也将自己的发现提交给了 Dgraph 的作者,如今的 Dgraph 版本,已经修正了该 Bug。
总的来说,我们在给企业选择图数据库时,需要分析企业自身的数据体量。如果要处理的数据量和知识量特别多,而且对于速度、性能有一定的要求的话,就不能使用单机版的数据库,而应当去考虑分布式。
与此同时,更重要的是:应用的场景。如果本企业除了要计算两个节点之间的关系,还需要得出节点关系所对应的边权重的话,那么我们更应该进行综合考量和全面对比。
在此,我分享一种我们自己研究出来的独门方法:一般而言,大多数图数据库(如 Neo4j),都会自带底层数据库。
而在实际建模的过程中,我们完全可以在底层不去使用图数据库,例如:可以用 MongoDB 作为底层;然后在它的上面去嵌套一层并未内置底层数据库的图数据库。而且实践证明,这样的混合模式会更加灵活且高效。
知识图谱落地

接下来,我们来看看知识图谱的落地。如上图所示,整个过程分成六个方面:
建立一套知识的模型
如何获取知识
如何做好知识的融合
如何实现知识的存储
如何保证知识的计算
高效地开展知识应用
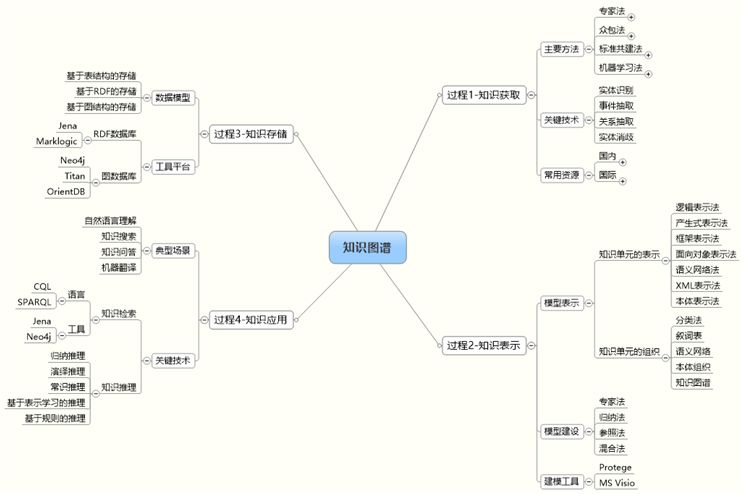
我们除了需要事先建立知识图谱的模型、以及运用模型来实现知识计算之外,上图反映了其他四个重要的过程,下面我们来逐一讨论。
知识获取
我们既可以通过网络爬虫爬取,也可以通过事件抽取(如使用 CRF 和 LSTM 等机器学习算法),还可以通过国内与国外的一些开源数据集来实现。
知识表示
在获取到了知识之后,我们要对知识进行加工表示。我们既可以用到逻辑表示、框架表示、语义表示,也可以用到各种词表、本体组织,还可以用到语义网络、以及文本与语义的分类方法。
在完成模型表示之后,我们需要进行各种模型的建设。当前,国内业界普遍采用的方法是专家法和归纳法,当然,参照法也有被用到。
所谓专家法,就是根据团队自身对于现有业务和行业的理解程度,通过人工来建模表示。
而归纳法,则是通过一些归纳算法、人工归纳、以及文本分类的方法,来进行模型的归纳。
我们混合使用了上述两种方法。而在建模工具方面,当属 Protege 和 MSVisio 最为常用。
知识存储
接着要进行的是知识存储,如前所述,我们需要选择一款数据库,包括:MySQL、SQL Server、MongoDB、Neo4j 等,不一而足。
根据我们过往的屡次实验经验,您可以先将数据存放到 Key-Vaule 类型的数据库中,而在后续需要的时候,再往 Neo4j 之类的图数据库中拉。
这种模式的性能要比直接存储要高一些。而在工具平台方面,Neo4j、Titan、以及 Cayley 都十分常用。
知识应用
确定了存储方式,后面就是知识应用。它包括自然语言理解、知识搜索、知识问答、以及机器翻译等典型的应用场景。
业界一般在模式上分为两种:
检索模式。在已经建立好的现成知识库图谱的基础上,我们将需要理解或翻译的句子,放到库里进行“答案”检索,再通过语义分析来进行匹配。最终将匹配出来的结果反馈给用户。可见,这是一种理解自然语言的常用场景。
混合模式。在检索模式的基础上,我们添加了深度自我生成的模型,以应对在知识库或语义库的匹配效果不佳的情况下,利用 RNN(循环神经网络)和 LSTM(长短期记忆网络)来生成智能模型。
在知识应用中,常用的关键技术包括:CQL、SPARQL、Jena、Neo4j、以及归纳、演绎和基于规则学习的推理。
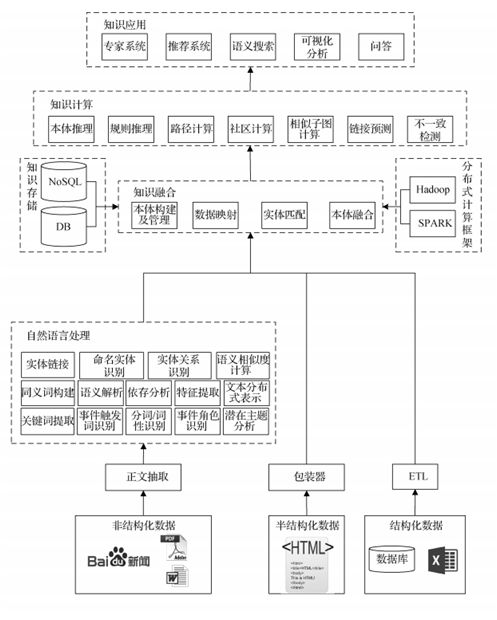
上图是一张非常经典的知识图谱整体架构图,让我们一起从下往上来解读这张图:
通过百度搜索、Word 文件、PDF 文档或是其他类型的文献,抽取出非结构化的数据。
通过自然语言处理技术,使用命令实体识别的方式,来识别出文章中的实体,包括:地名、人名、以及机构名称等。
通过语义相似度的计算,确定两个实体或两段话之间的相似程度。
通过同义词构建、语义解析、依存分析等方式,来找到实体之间的特征关系。
通过诸如 TF-IDF 和向量来提取文本特征,通过触发事件、分词词性等予以表示。
通过 RDA(冗余分析)来进行主题的含义分析。
使用数据库或数据表进行数据存储。
针对所提取出来的文本、语义、内容等特征,通过知识本体的构建,实现实体之间的匹配,进而将它们存放到 Key-Value 类型的数据库中,以完成数据的映射和本体的融合。
当数据的体量过大时,使用 Hadoop 和 Spark 之类的分布式数据存储框架,再通过 NoSQL 的内容将数据存过去。
当需要进行数据推理或知识图谱的建立时,再从数据中抽取出各类关系,通过各种集成规则来形成不同的应用。
总结起来,在我们使用知识图谱来进行各种应用识别时,需要注意的关键点包括:如何抽取实体的关系,如何做好关键词与特征的提取,以及如何保证语义内容的分析。这便是我们构建一整套知识图谱的常用方法与理论。
作者:黄鸿波
介绍:
编辑:陈峻、陶家龙、孙淑娟
来源:有投稿、寻求报道意向技术人请联络 editor@51cto.com

精彩文章推荐:




