TensorSpace:超酷炫3D神经网络可视化框架
选自 PaperWeekly
作者:刘遥行
学校:圣何塞州立大学硕士生
研究方向:AI与现实生活的工业结合
TensorSpace - 一款 3D 模型可视化框架,支持多种模型,帮助你可视化层间输出,更直观地展示模型的输入输出,帮助理解模型结构和输出方法。
是什么(What)
TensorSpace 是一款 3D 模型可视化框架,一动图胜千言。

官网链接:
https://tensorspace.org/
Github链接:
https://github.com/tensorspace-team/tensorspace
TensorSpace 擅长直观展示模型结构和层间数据,生成的模型可交互。官方支持手写字符识别,物体识别,0-9 字符对抗生成网络案例等。
为什么(Why)
本部分说明:为什么要使用这个框架?这个框架主要解决了什么问题?我们的灵感来源于何处?
3D神经网络可视化一片空白
在机器学习可视化上,每个机器学习框架都有自己的御用工具,TensorBoard 之于 TensorFlow ,Visdom 之于 PyTorch,MXBoard 之于 MXNet。这些工具的 Slogan 不约而同地选择了 Visualization Learning(TensorBoard的 Slogan),也就是面向专业机器学习开发者,针对训练过程,调参等设计的专业向可视化工具。
但面向一般的计算机工程师和非技术类人才(市场、营销、产品等),一片空白,没有一个优秀的工具来帮助他们理解机器学习模型到底做了什么,能解决一个什么问题。
机器学习开发和工程使用并不是那么遥不可及,TensorSpace 搭建桥梁连接实际问题和机器学习模型。
3D可视化的信息密度更高更直观
市面上常见的机器学习可视化框架都是基于图表(2D),这是由它们的应用领域(训练调试)决定的。但 3D 可视化不仅能同时表示层间信息,更能直观地展示模型结构,这一点是 2D 可视化不具备的。
例如在何恺明大神的 Mask-RCNN 论文中,有这么一幅图来描述模型结构(很多模型设计类和应用落地类的论文都会有这么一幅图):
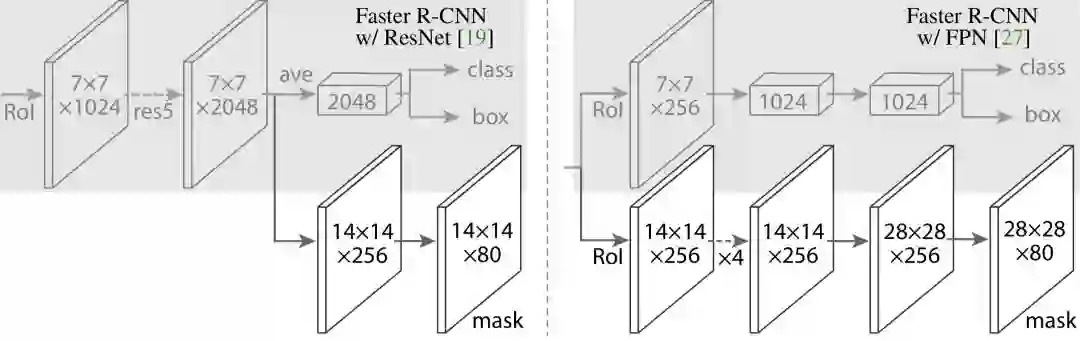
TensorSpace 可以让用户使用浏览器方便地构建一个可交互的神经网络 3D 结构。更进一步的,用户还可以利用 3D 模型的表意能力特点,结合 Tensorflow.js 在浏览器中进行模型预测(跑已经训练好的模型看输入输出分别是什么),帮助理解模型。
模型结构:黑盒子的真面目是什么?
模型就像是一个盛水的容器,而预训练模型就是给这个容器装满了水,可以用来解决实际问题。搞明白一个模型的输入是什么,输出是什么,如何转化成我们可理解的数据结构格式(比如输出的是一个物体标识框的左上角左下角目标),就可以方便地理解某个模型具体做了什么。
例如,YOLO 到底是如何算出最后的物体识别框的?LeNet 是如何做手写识别的?ACGAN 是怎么一步一步生成一个 0-9 的图片的?这些都可以在提供的 Playground 中自行探索。
如下图所示,模型层间的链接信息可通过直接鼠标悬停具体查看。
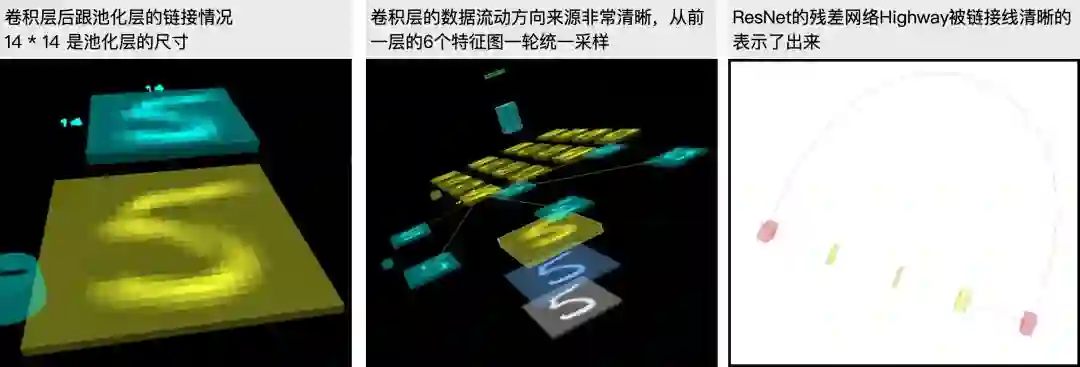
层间数据:神经网络的每一层都做了什么?
3D 模型不仅可以直观展示出神经网络的结构特征(哪些层相连,每一层的数据和计算是从哪里来),还能结合 Tensorflow.js 在浏览器中进行模型预测。由于我们已经有了模型结果,所有的层间数据直观可见,如下图所示:

在 TensorSpace 内部,调用 Callback Function 可以方便的拿到每一层的输出数据(未经处理),工程和应用上,了解一个模型的原始输出数据方便工程落地。
怎么建(How)
首先你需要有一个使用常用框架训练好的预训练模型,常见的模型都是只有输入输出两个暴露给用户的接口。TensorSpace 可以全面地展示层间数据,不过需要用户将模型转换成多输出的模型,过程详见以下文档。
模型预处理简介:
http://tensorspace.org/html/docs/preIntro_zh.html
具体流程如下图所示:
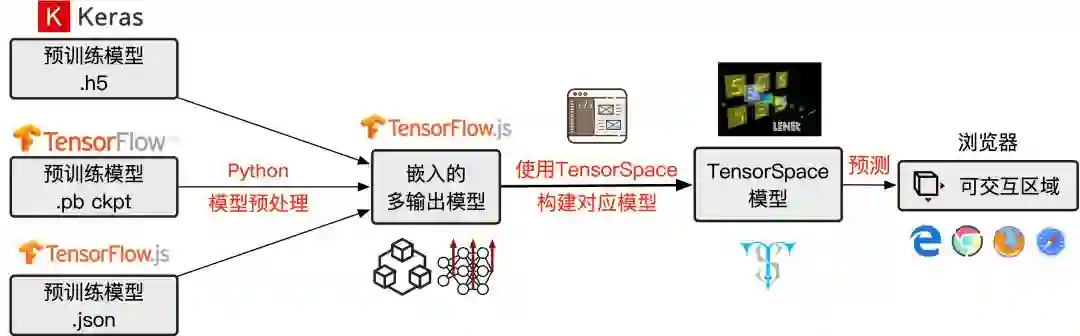
用 TensorSpace 构建对应模型这一步,下面一段构建 LetNet 的代码可能更加直观,如果要在本地运行,需要 Host 本地 Http Server。
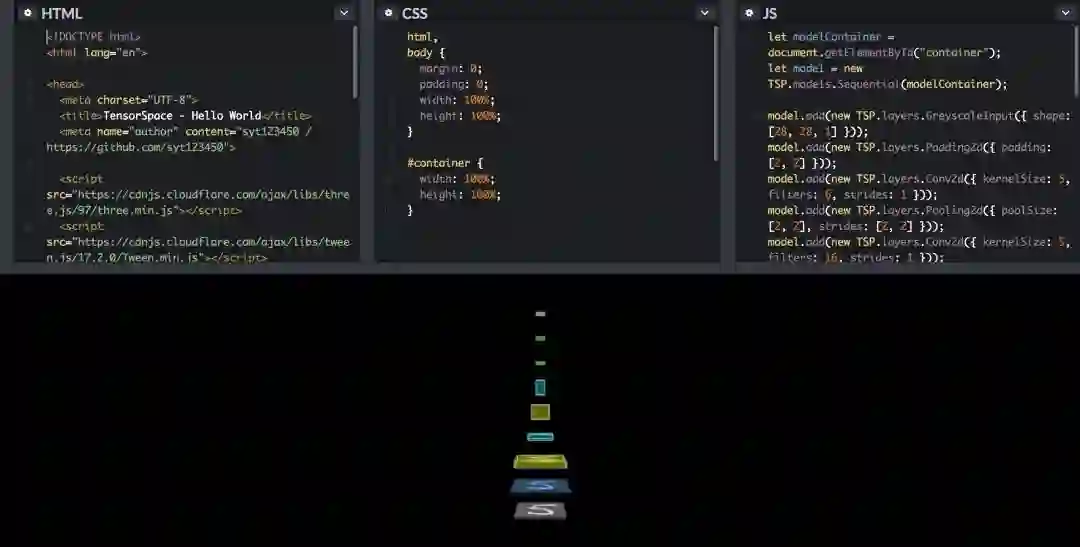
你最需要的是模型结构的相关信息,TensorFlow,Keras 都有对应的 API 打印模型结构信息,比如 Keras 的 model.summary()。还有类似生成结构图的方式,生成如下图的模型结构 2D 示意图:
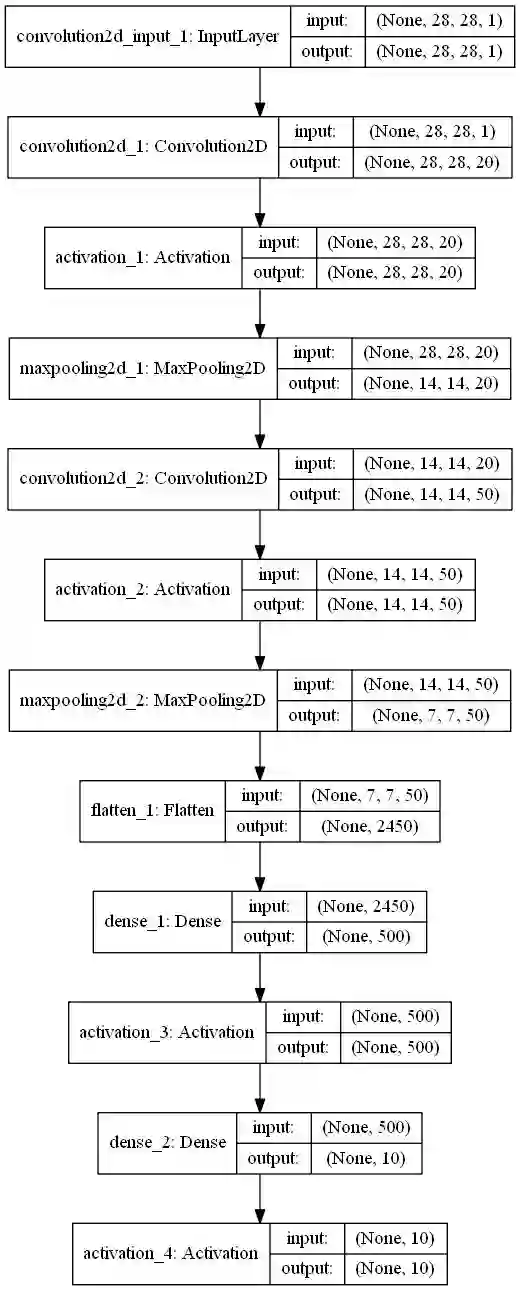
是的,你需要对模型结构非常了解才可能构建出对应的 TensorSpace 模型。未来版本已计划推出自动脚本,通过导入对应的模型预训练文件,一键生成多输出模型。但是 TensorSpace 的 Playground 子项目未来会力所能及地收集更多模型,在模型应用落地和直观展示这个领域努力做出贡献。
谁可能用(Who)
做这样一款开源框架,除了填补 3D 可视化的一般解决方案的框架空白外,还思索了几个可能可行的应用场景。
前端开发者过渡机器学习
前端(全栈)开发者,产品经理等
未来,前端的重复性工作可能会慢慢减少。最近有一个原型图→HTML代码的项目,另一个 2017 年的开源项目 Pix2Code 都在尝试利用机器学习自动化一些 Coding 中的重复劳动,提高效率。
机器学习一定不会取代前端工程师,但掌握机器学习工具的工程师会有优势(这种工具会不会整合进 Sketch 等工具不好说),既然入了工程师行,终身学习势在必行。
TensorSpace 虽然不能帮忙训练和设计模型,但它却擅长帮助工程师理解已有模型,为其找到可应用的领域。并且,在接驳广大开发者到机器学习的大道上做了一点微小的工作,做一个可视化的 Model Zoo。
机器学习教育
机器学习课程教育者
使用 TensorSpace 直观地在浏览器上显示模型细节和数据流动方向,讲解常见模型的实现原理,比如 ResNet,YOLO 等,可以让学生更直观地了解一个模型的前世今生,输入是什么,输出是什么,怎么处理数据等等。
我们只是提供了一个框架,每一个模型如果需要直观地展示对数据的处理过程,都值得 3D 化。
模型演示和传播
机器学习开发者
JavaScript 最大的优势就是可以在浏览器中运行,没有烦人的依赖,不需要踩过各种坑。有一个版本不那么落后的浏览器和一台性能还可以的电脑就可以完整访问所有内容。
如果您的项目需要展示自己的模型可以做什么、是怎么做的,私以为,您真的不应该错过 TensorSpace。
用 TensorSpace 教学模型原理效果非常好。它提供了一个接口去写代码,搞清楚每一个输出代表了什么,是如何转化成最后结果。当然,从输出到最后结果的转换还是需要写 JavaScript 代码去构建模型结构,在这个过程中也能更进一步理解模型的构造细节。
现在还没有完成的 Yolov2-tiny 就是因为 JavaScript 的轮子较少(大多数处理轮子都使用 Python 完成),所有的数据处理都需徒手搭建。时间的力量是强大的,我们搭建一个地基,万丈高楼平地起!
致谢
机器学习部分
我们最初的灵感来源于一个真正教会我深度卷积网是如何工作的网站:
http://scs.ryerson.ca/~aharley/vis/conv/
源码只能下载,我 Host 了一份在 Github 上:
https://github.com/CharlesLiuyx/3DVis_ConvNN
这个网站的效果,也是团队未来努力的方向(大网络上,因为实体过多,性能无法支持。为了解决性能问题,我们优化为:不是一个 Pixel 一个 Pixel 的渲染,而是一个特征图一个特征图的处理。
前端部分
使用 Tensorflow.js、Three.js、Tween.js 等框架完成这个项目,感谢前人给的宽阔肩膀让我们有机会去探索更广阔的世界。
开发团队们
感谢每一个为这个项目付出的伙伴,没有你们每个人,就没有这个开源项目破土而出。
开发团队成员:
syt123450 — 主力开发
https://github.com/syt123450
Chenhua Zhu — 开发
https://github.com/zchholmes
Qi (Nora) — 设计师
https://github.com/lq3297401
CharlesLiuyx — 机器学习模型 & 文档
https://github.com/CharlesLiuyx
也欢迎你有什么想法给我留言,或直接在 Github 上提出 Pull Request。
本文为机器之心专栏,转载请联系 PaperWeekly 公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com





